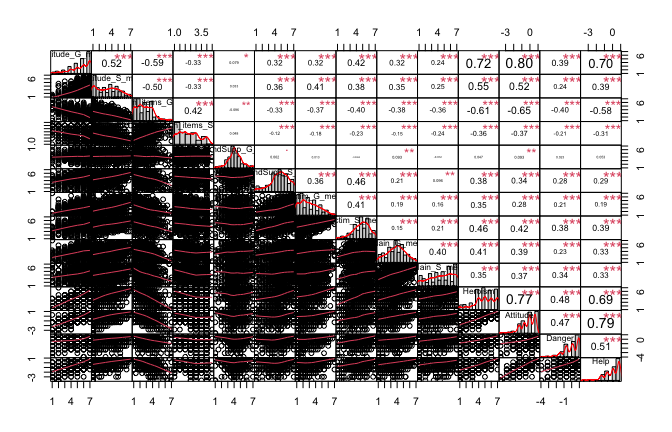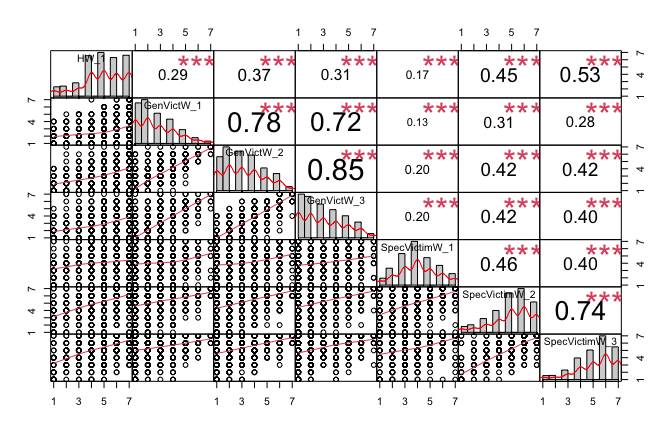
Primary analyses
A model comparison approach was used to assess our main hypotheses and qualify the part of variance explained by general attitude (i.e., Halo effect).
For each step of our model‐comparison procedure, we evaluated two models: 1) one based on general-level items, 2) one based on specific-level items,
If an hypothesis is supported at both the general and specific levels, we interpret this as full support for the hypothesis. If only one type of measure supports the hypothesis, we interpret this as partial support for the hypothesis.
We performed independent OLS regression models predicting each of our target outcomes (i.e., gratitude, criticism acceptability, support for workers demands, suffering assessment, and acceptability of regulations violation) using heroism score and occupations as predictors.
We established four models assessing the effect of heroism while accounting for possible interactions with occupation types and possible halo effects (see subsection Variable roles for details on each model).
Model 1 (Heroism effect across occupations): Target construct (gratitude, criticism acceptability, support for demands, suffering assessment, or acceptability of regulation violations): predicted variable Occupation: covariate Heroism: Main predictor Model: Target outcome ~ Occupation + Heroism
Model 2 (Heroism within occupations): Target construct (gratitude, criticism acceptability, support for demands, suffering assessment, or acceptability of regulation violations): predicted variable Occupation: main predictor and moderator Heroism: Main predictor and moderator Model: Target outcome ~ Occupation * Heroism
Model 3 (Heroism effect across occupations and Halo effect): Target construct (gratitude, criticism acceptability, support for demands, suffering assessment, or acceptability of regulation violations): predicted variable Occupation: covariate Attitude: Covariate Heroism: Main predictor and moderator Model: Target outcome ~ Occupation + Heroism + Attitude
Model 4 (Heroism within occupations and Halo effect): Target construct (gratitude, criticism acceptability, support for demands, suffering assessment, or acceptability of regulation violations): predicted variable Occupation: main predictor and moderator Heroism: Main predictor and moderator Attitude: Covariate Model: Target outcome ~ Occupation * Heroism + Attitude
Note that we interpret a type-III ANOVA based on the regression models, as for models including Occupation type (a factor variable), analysing directly the regression model would give us the slope of heroism only for the reference level of the factor variable. Not registered specification: In practice, it means using sum-to-zero contrasts for the factor Occupation
AS REGISTERED: our main conclusions will be based on Model 1 and 2 – not accounting for attitude.
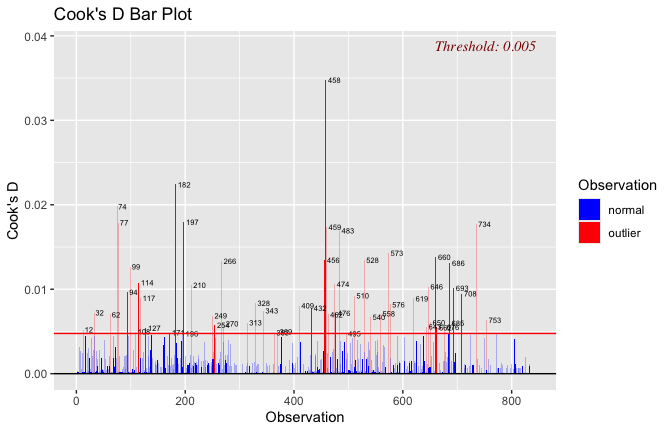
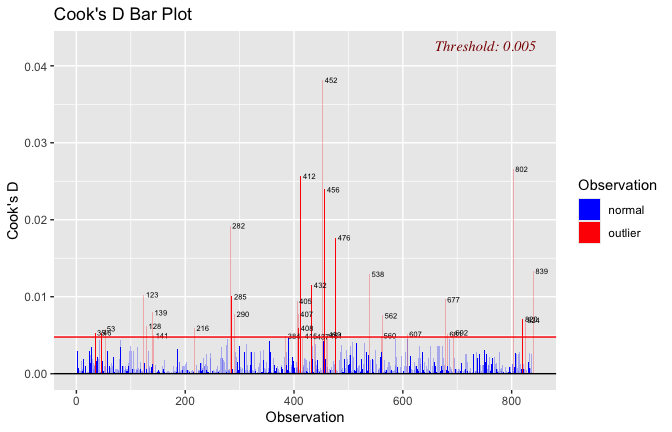
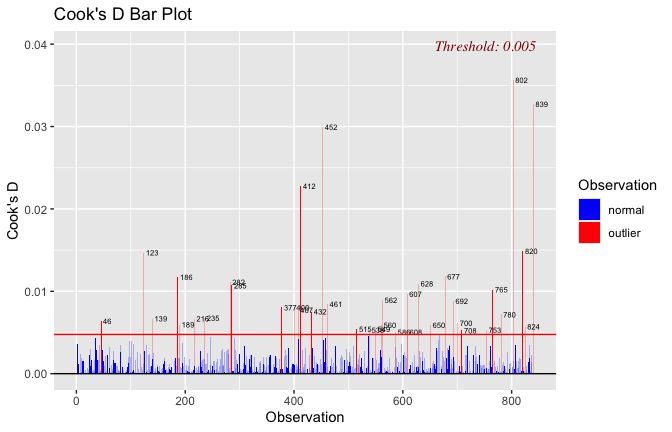
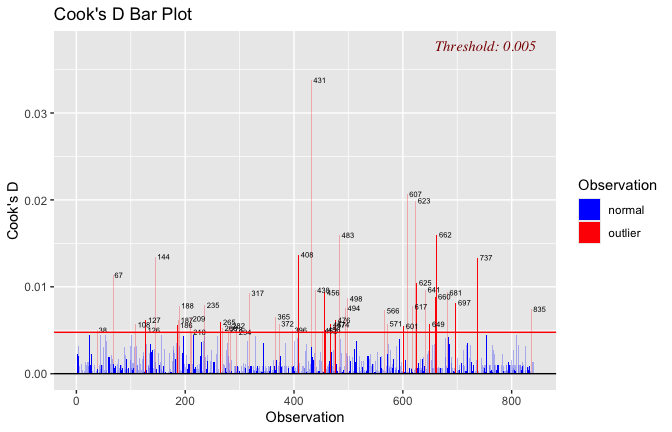
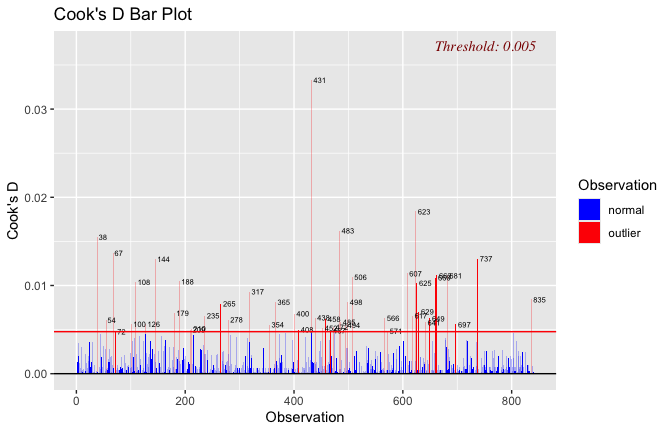
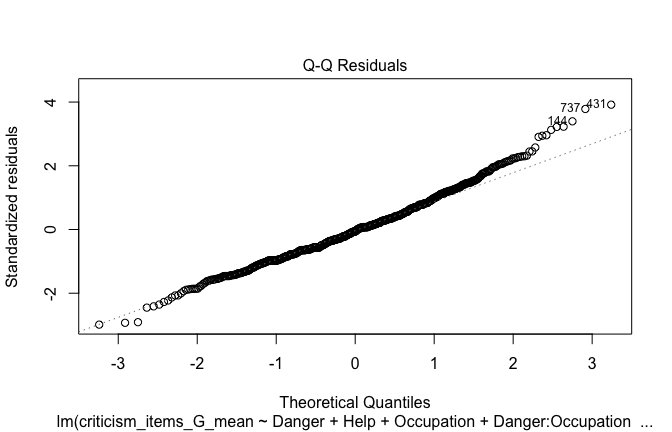
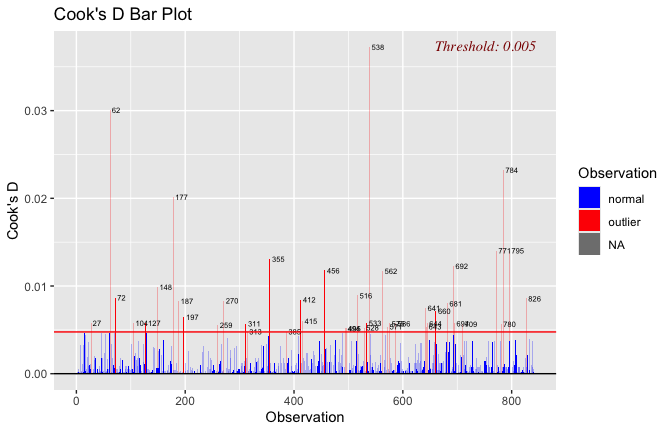
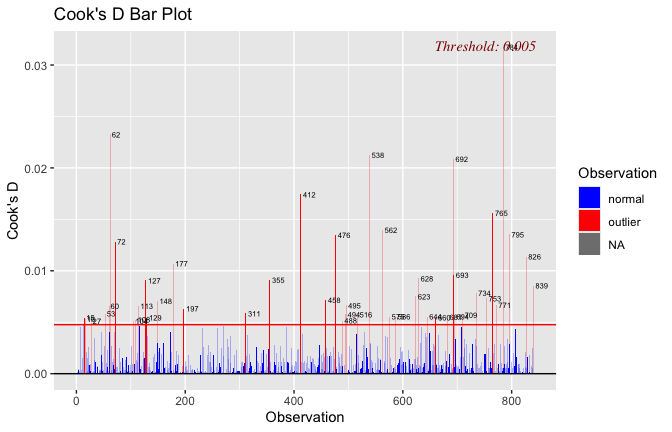
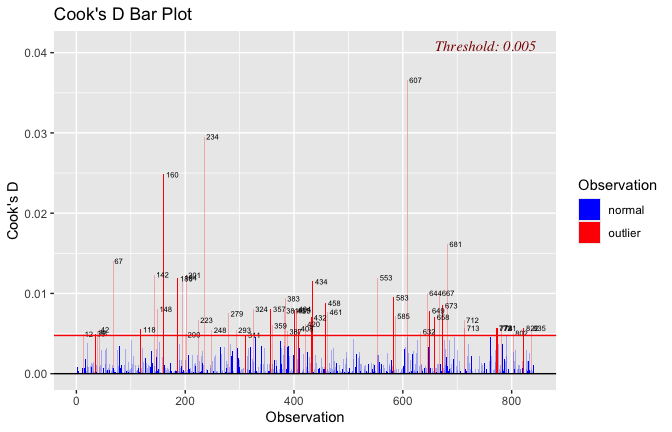
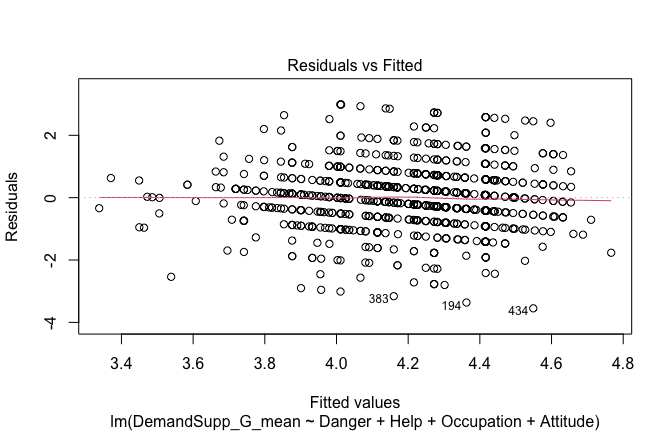
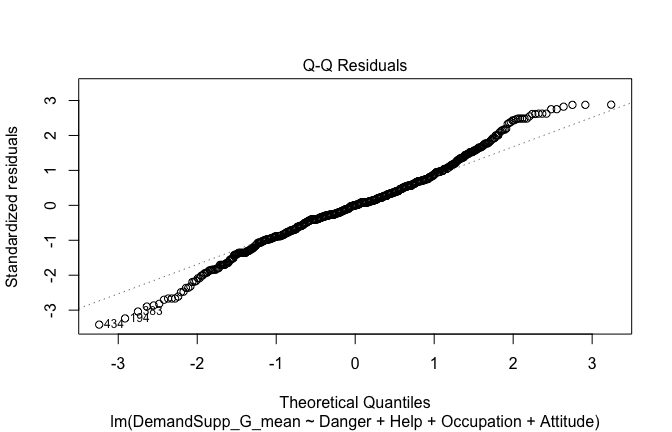
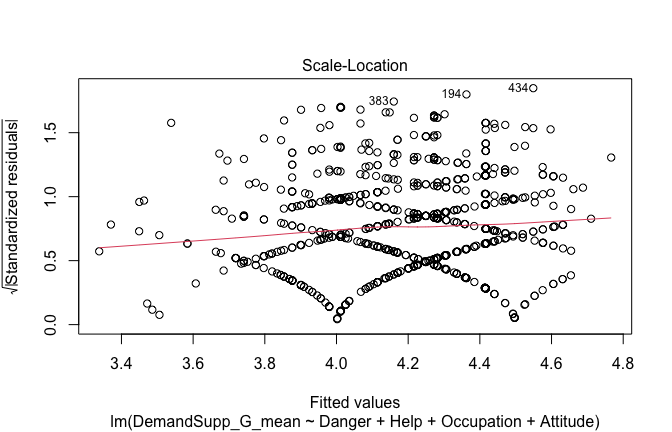
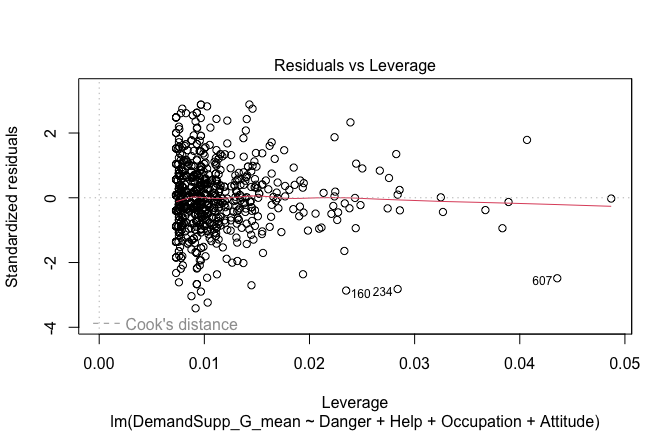
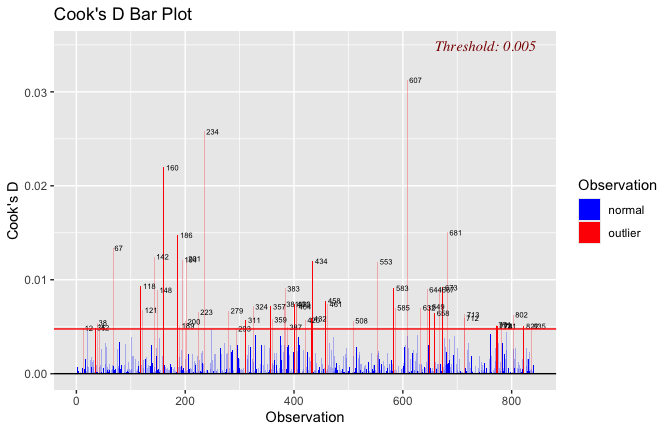
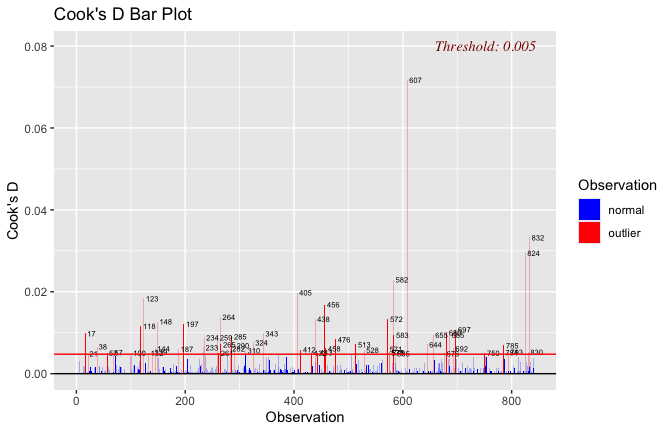
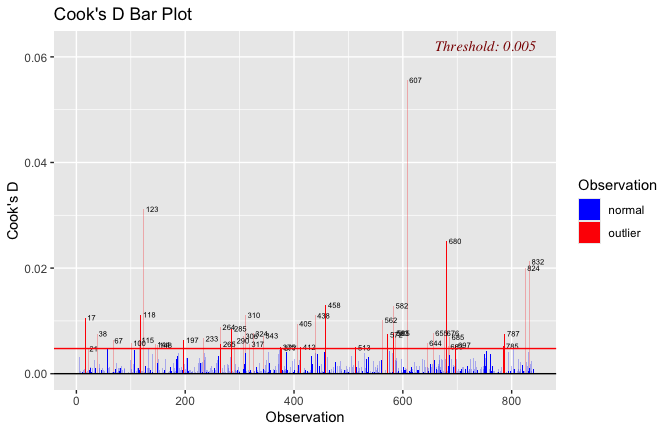
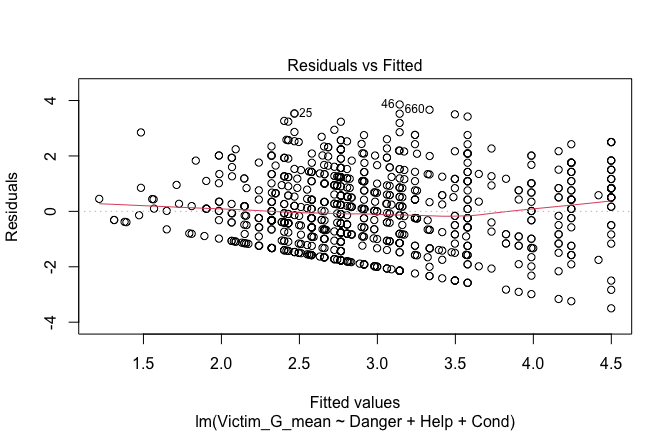
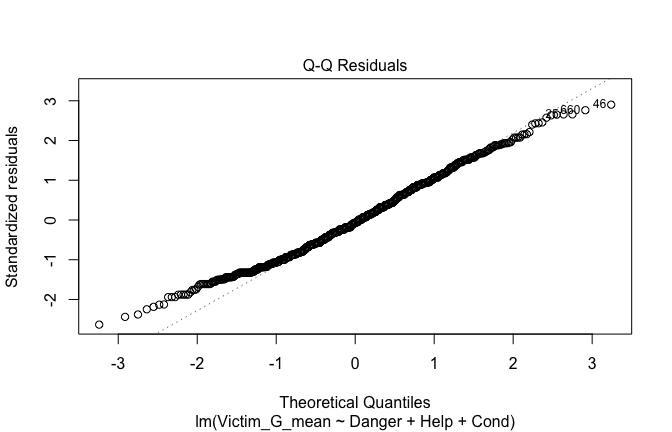
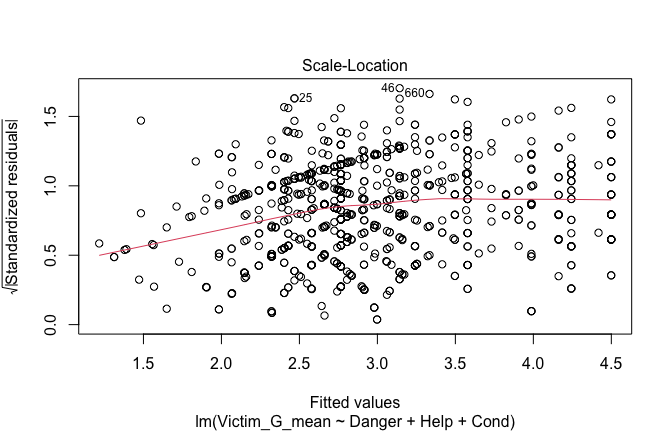
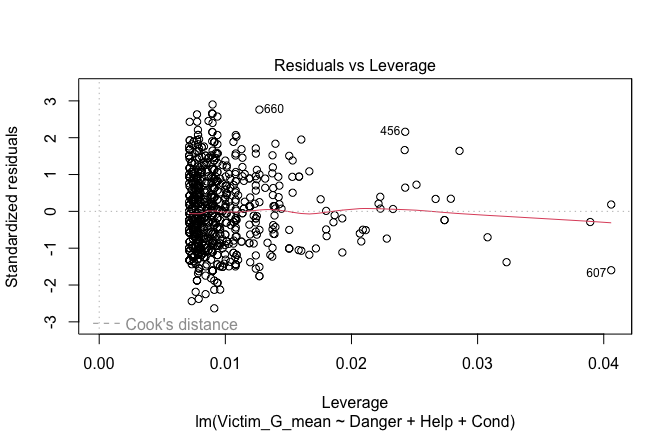
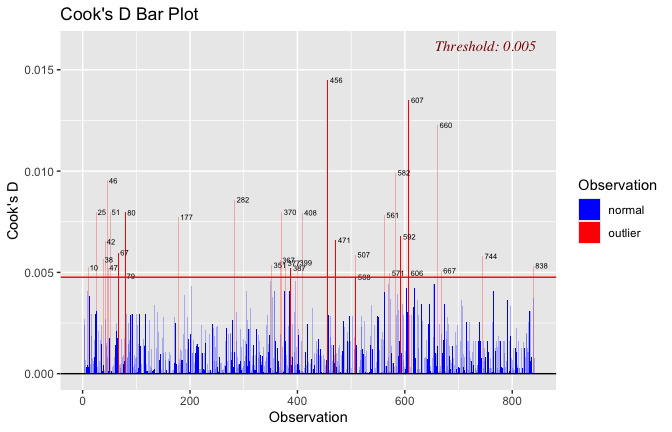
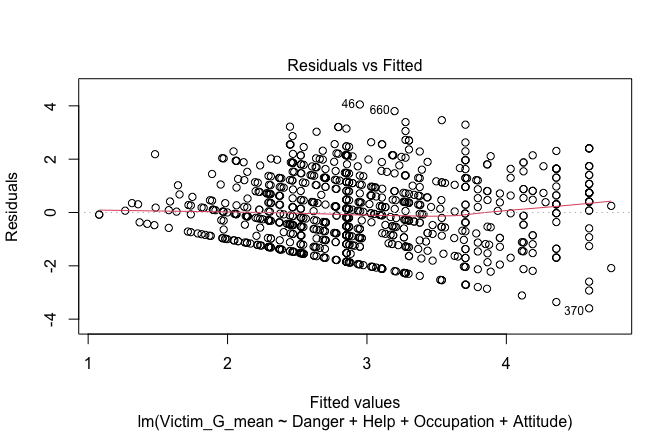
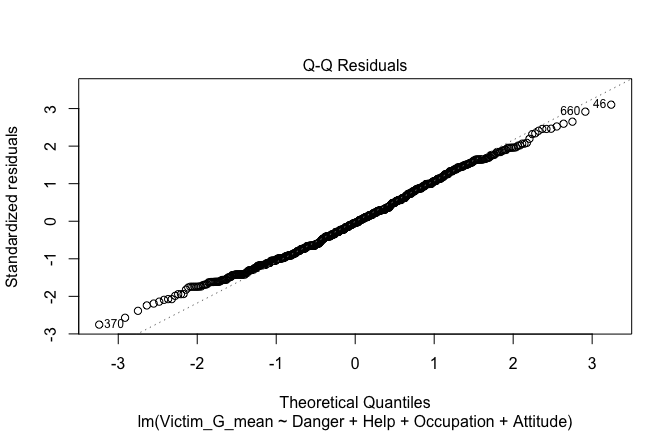
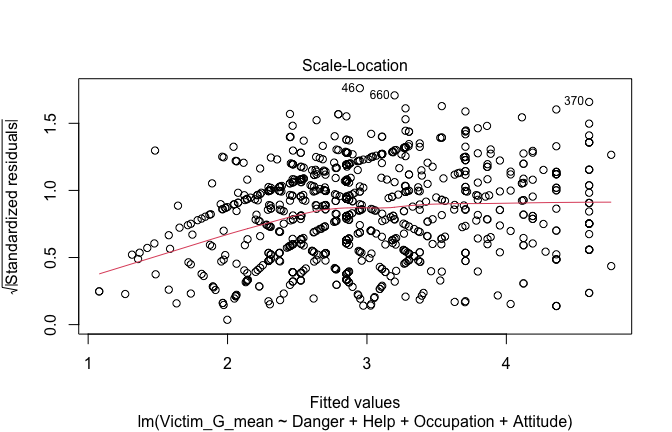
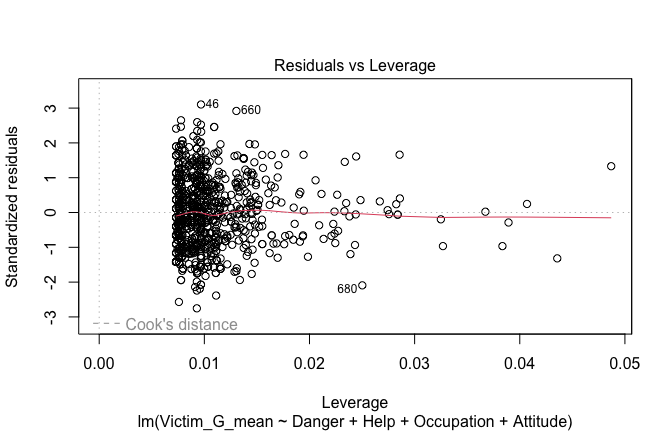
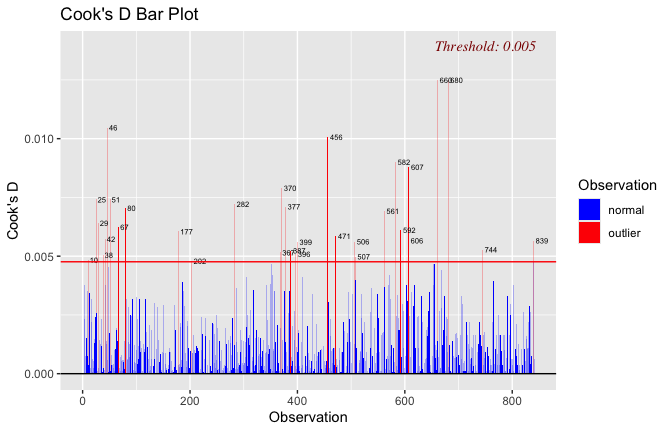
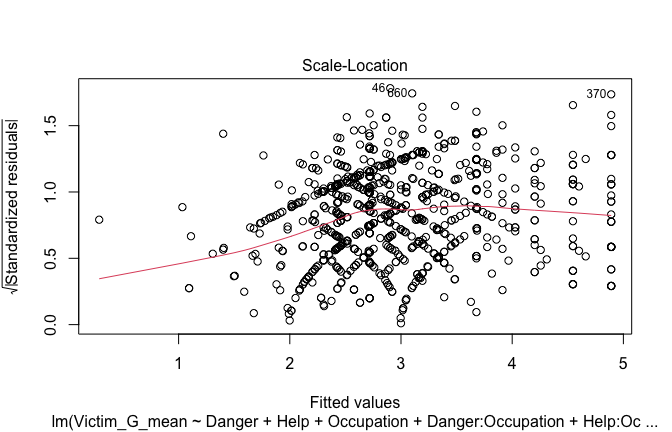
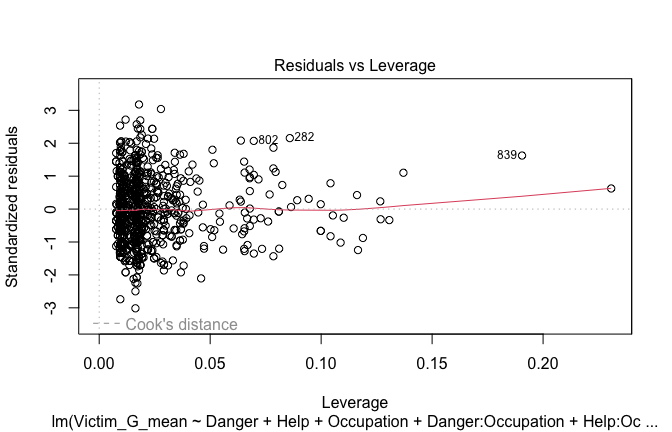
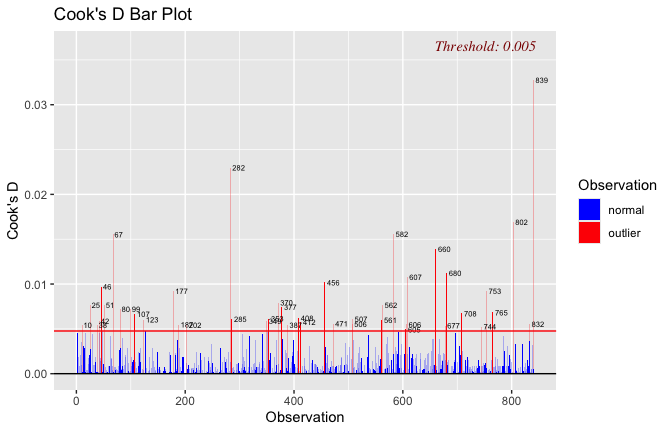
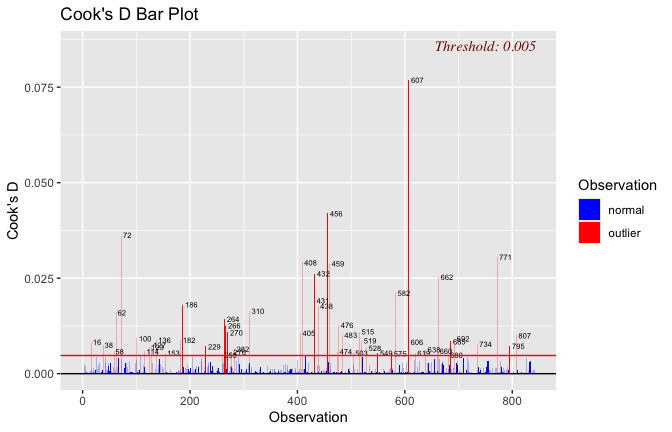
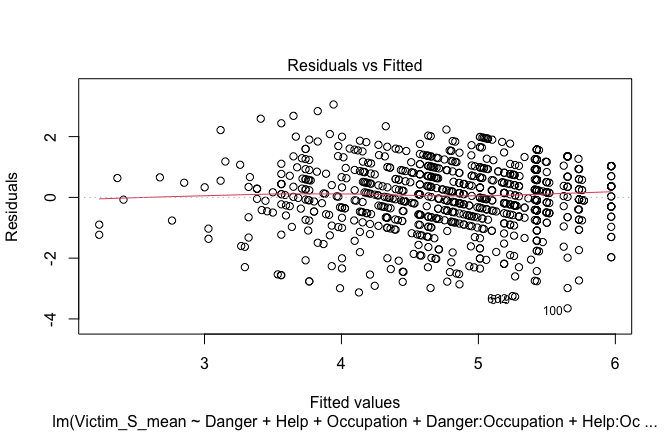
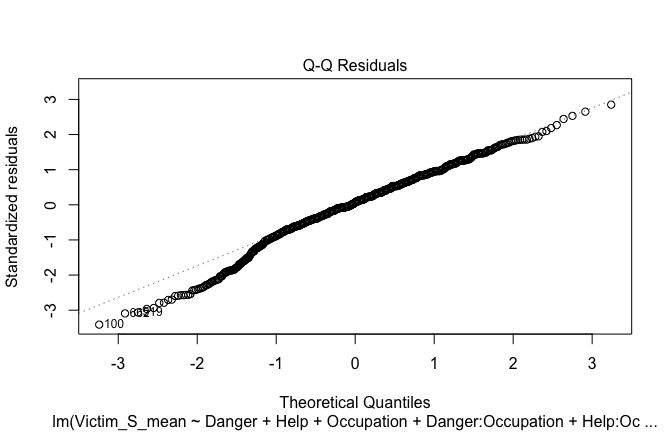
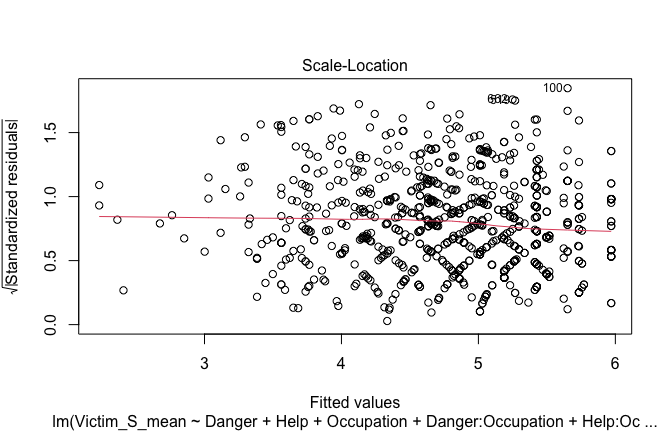
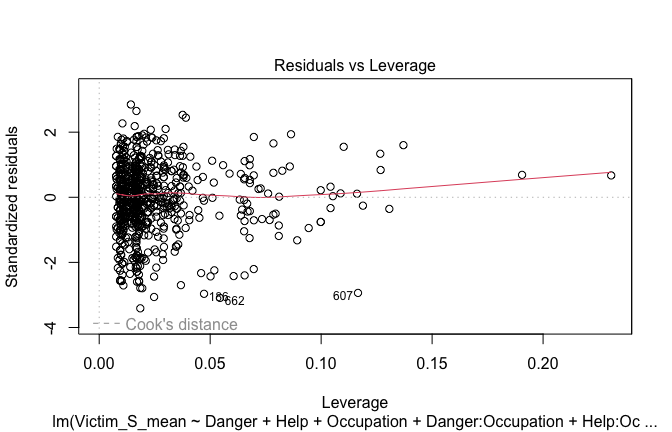
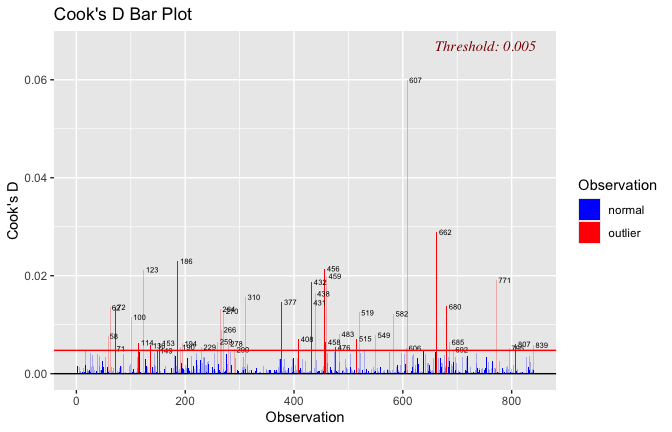
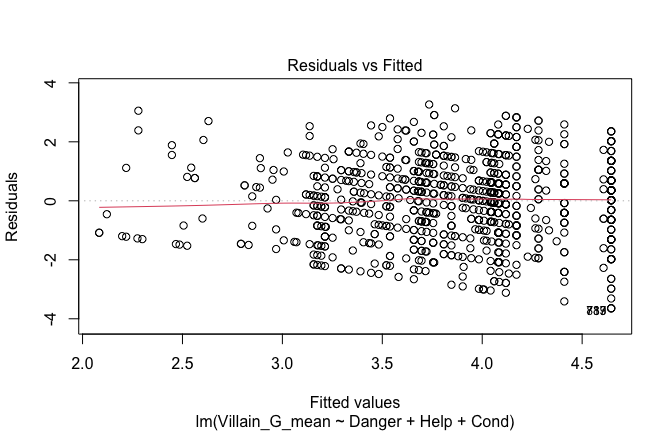
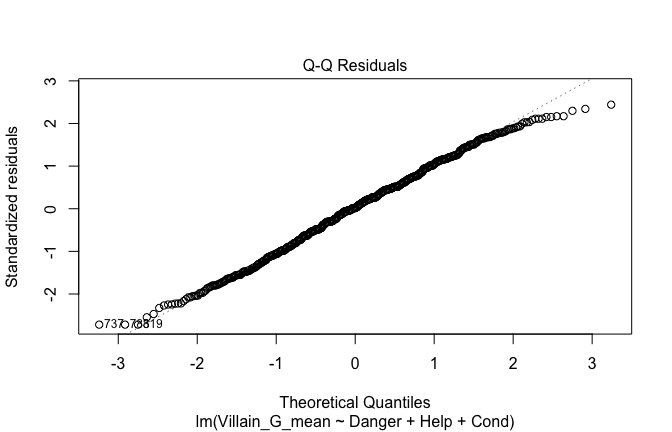
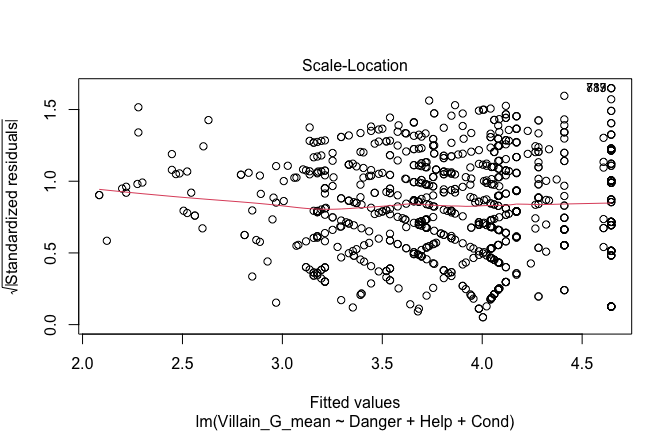
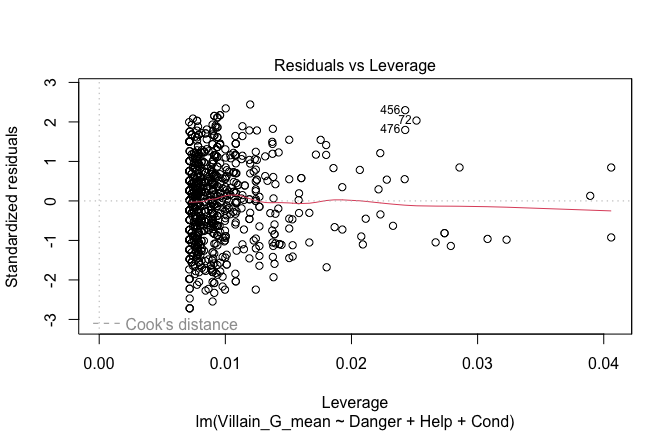
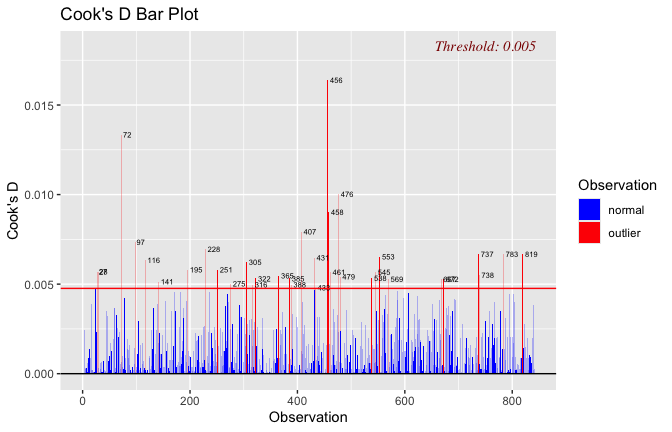
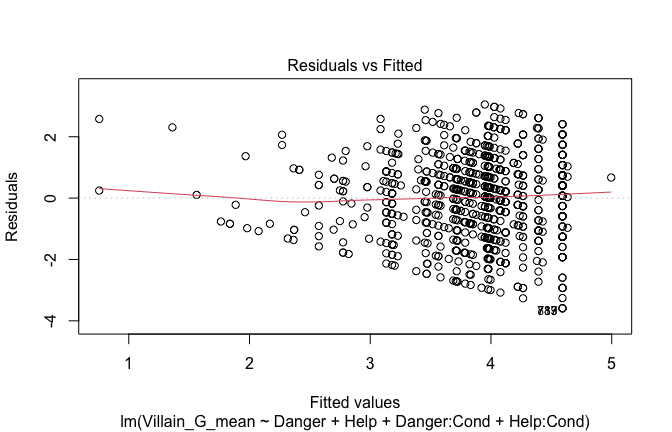
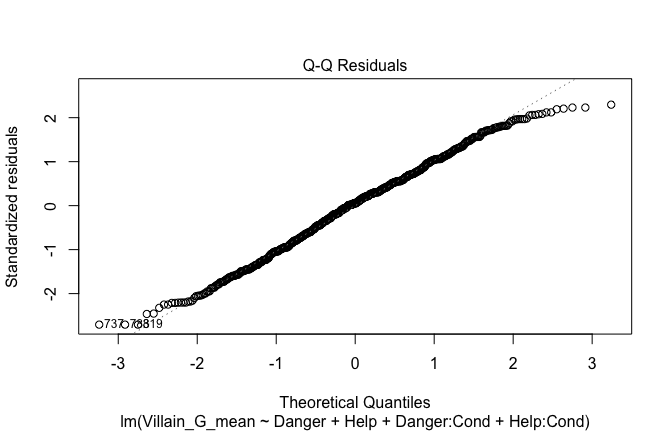
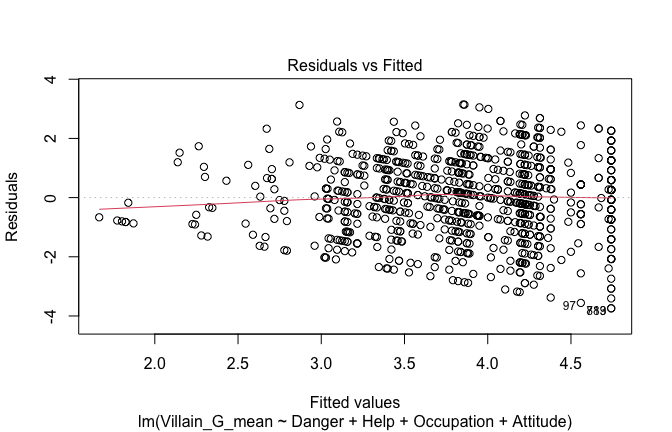
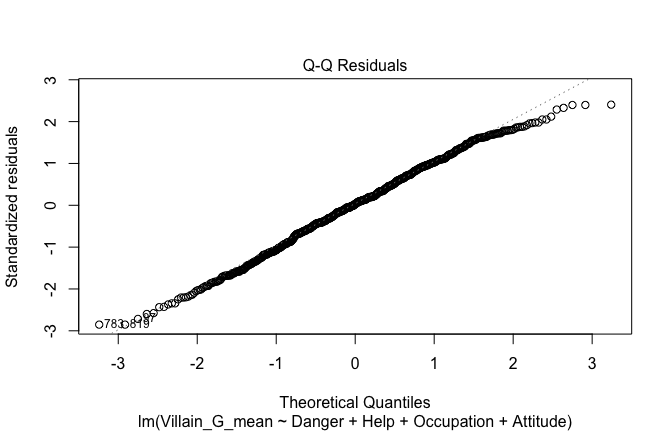
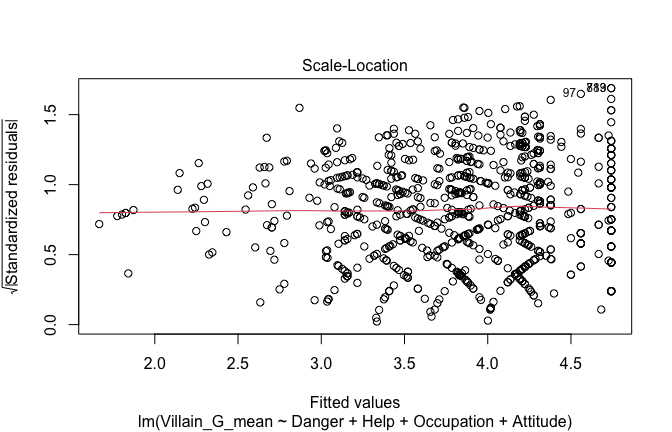
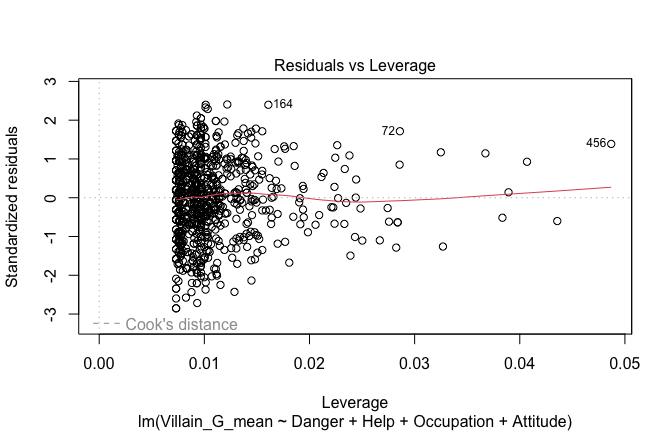
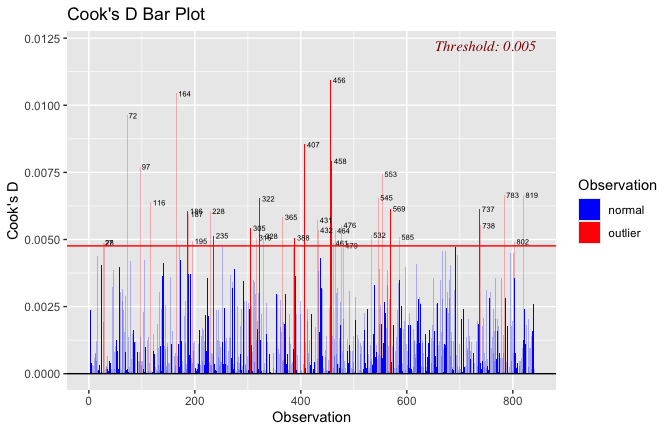
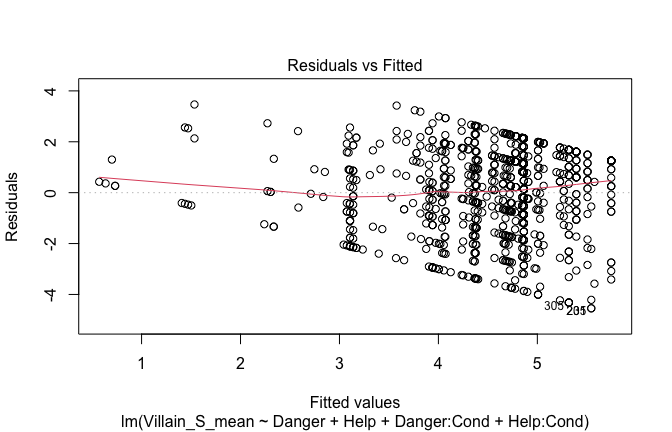
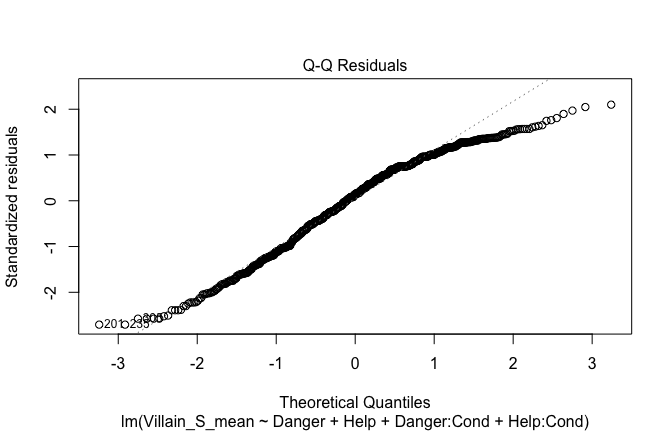
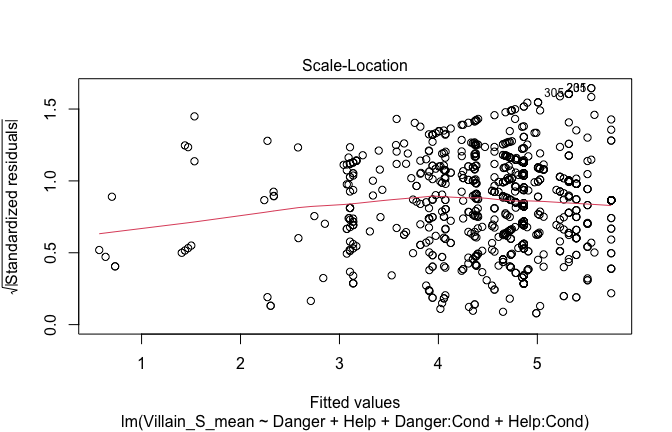
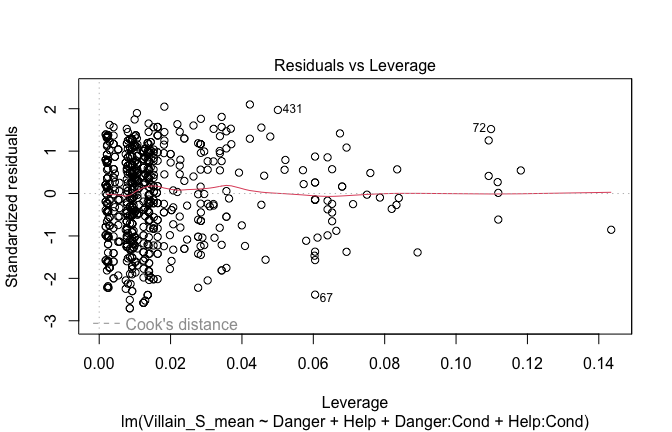
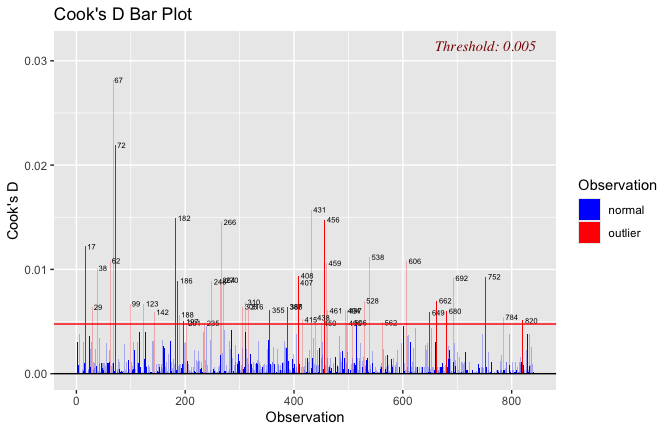
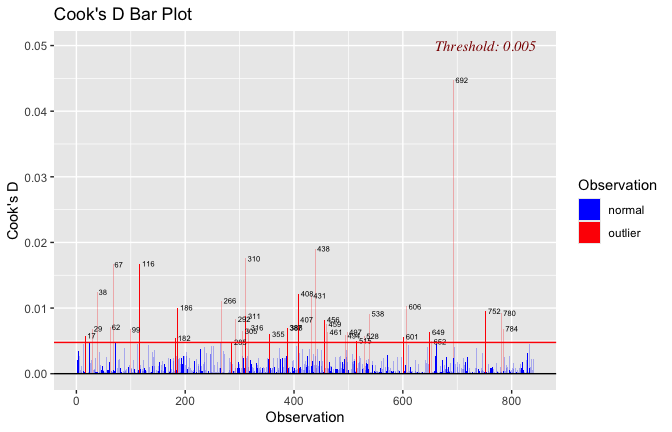
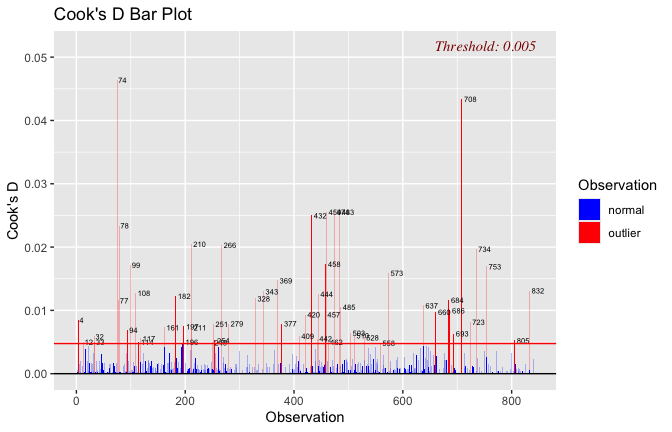
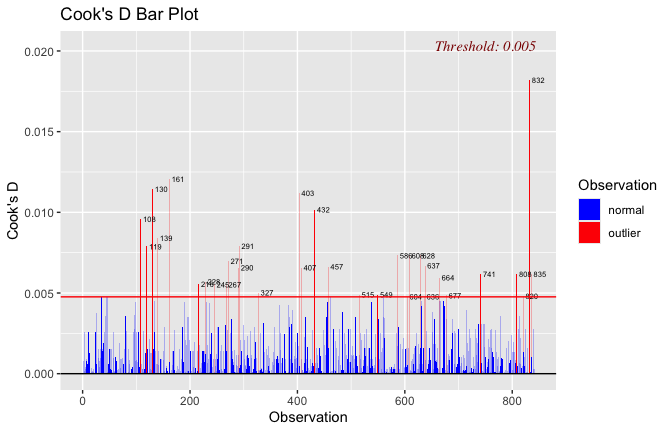
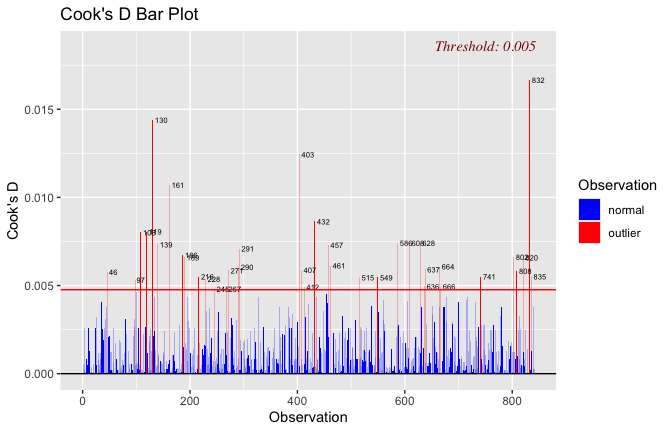
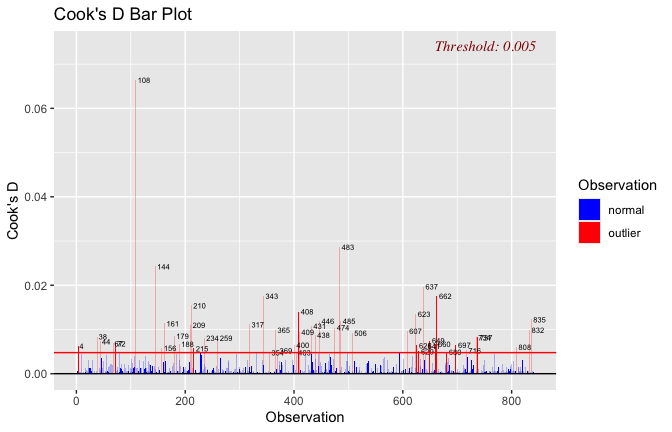
Toggle details of the models diagnostics and outlier analyses
We scale all numeric variables, and we add our sum-to-zero contrast to the occupation level.
scale_scores <- stacked_num[, c(40, 2, 48:57, 36:39, 34, 35)]
scale_scores$Cond <- as.factor(scale_scores$Cond)
contrasts(scale_scores$Cond) <- contr.sum(nlevels(scale_scores$Cond))
contrasts(scale_scores$Cond) # Deviations from registration!! We need to use sum to zero contrasts to make coef interpretable## [,1] [,2] [,3] [,4] [,5]
## Firefighter 1 0 0 0 0
## Journalist 0 1 0 0 0
## Nurse 0 0 1 0 0
## Psych 0 0 0 1 0
## Soldier 0 0 0 0 1
## Weld -1 -1 -1 -1 -1H1: Heroism is positively associated to gratitude
We are grateful for our heroes. As such, at a general level, people might declare openly gratefulness toward workers, and at the specific level, they are likely to display public support for the workers that are heroised. Sharing supportive post online, donating to campaigns, volunteering their time… people want to give back to heroes.
General level
To what extent do you feel grateful for XXXs’ work?
Toggle details of the models diagnostics and outlier analyses
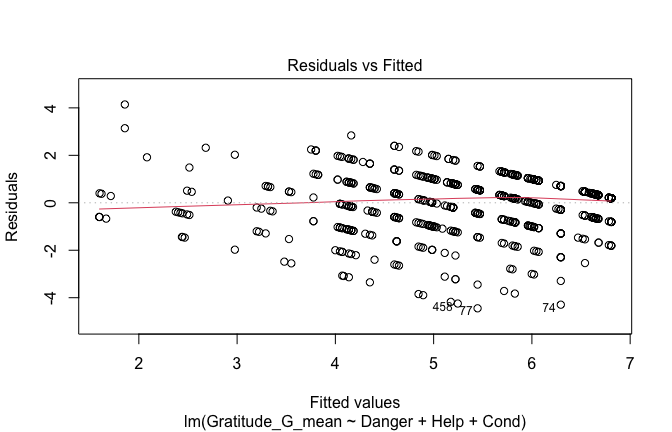
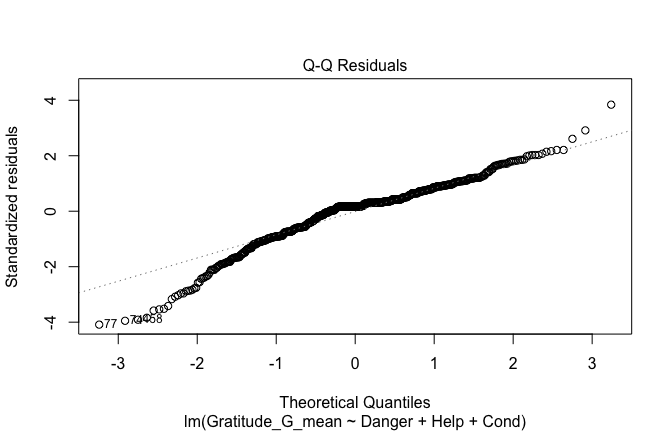
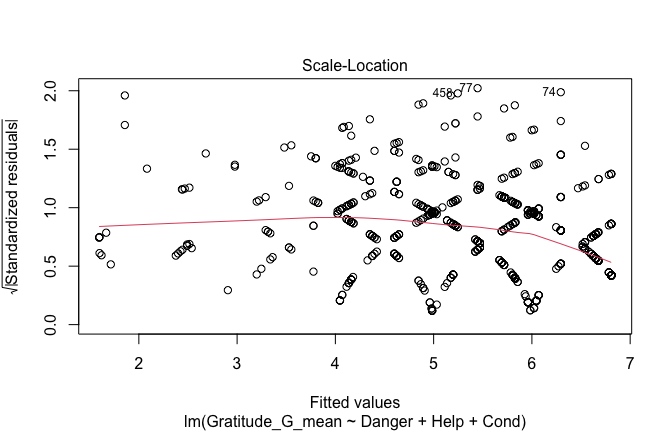
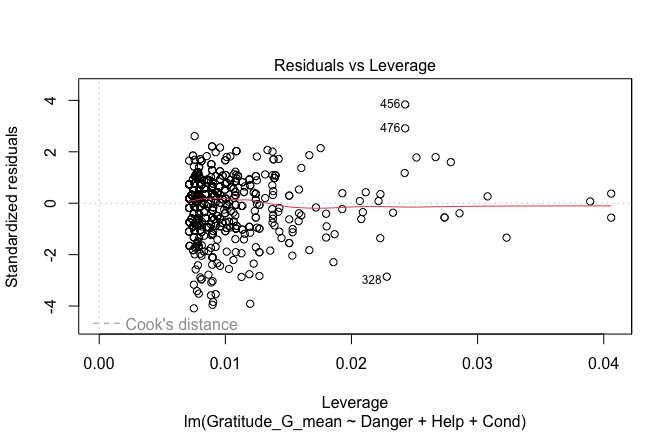
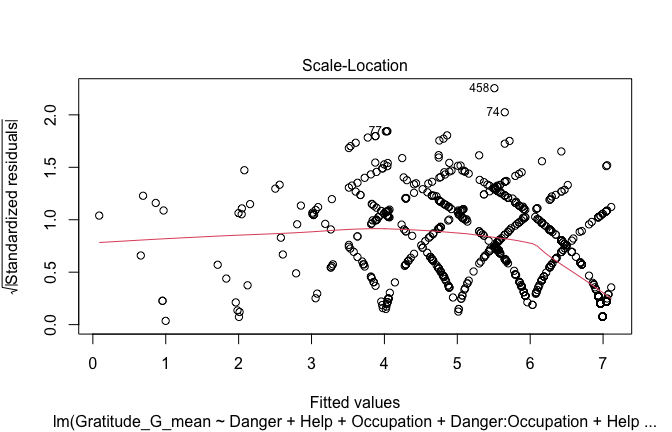
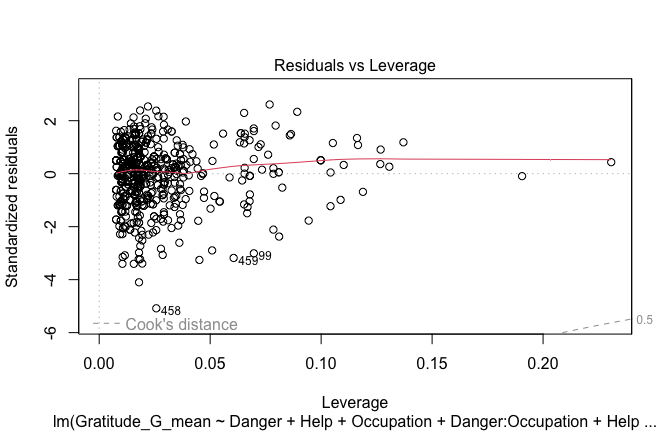
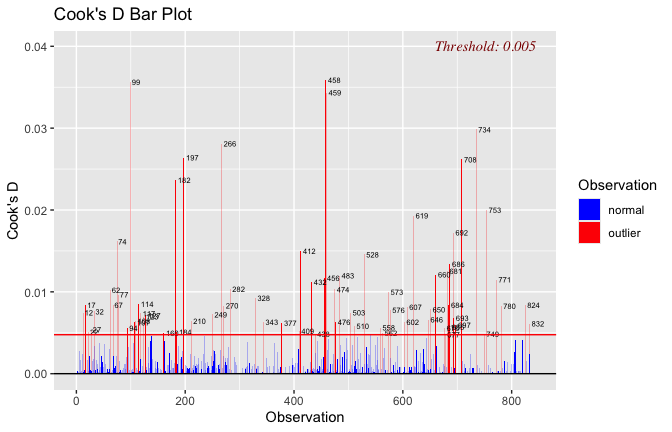
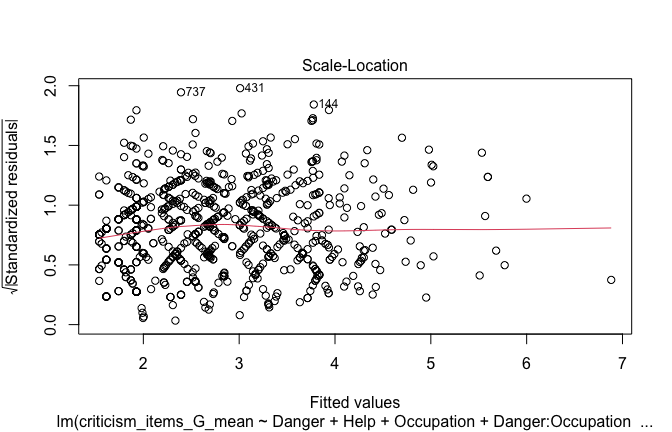
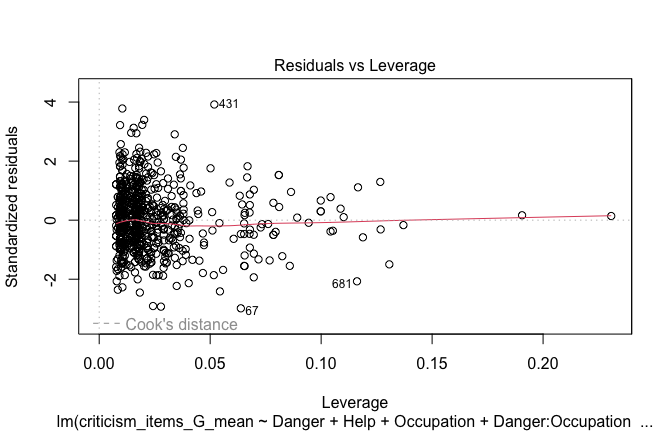
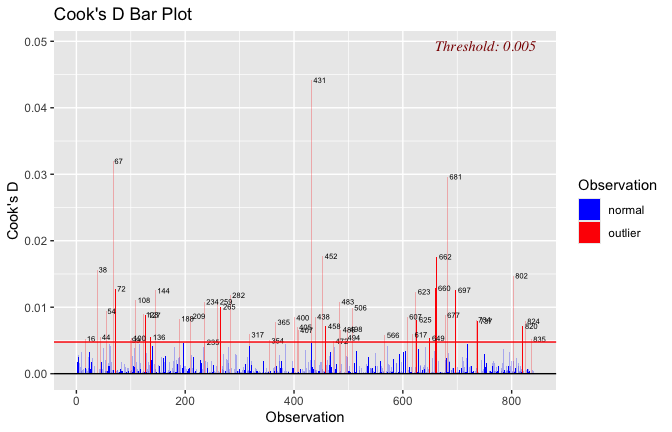
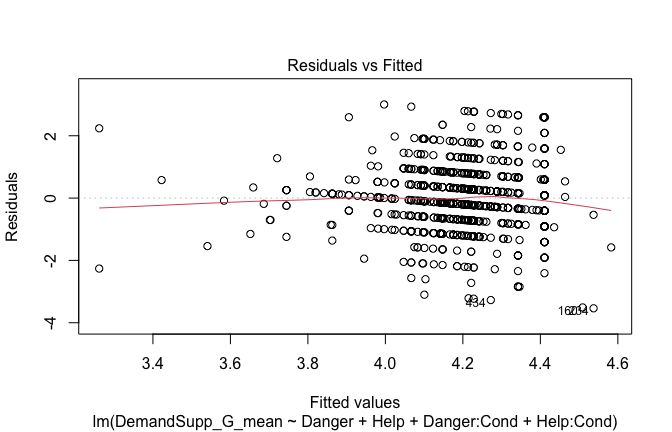
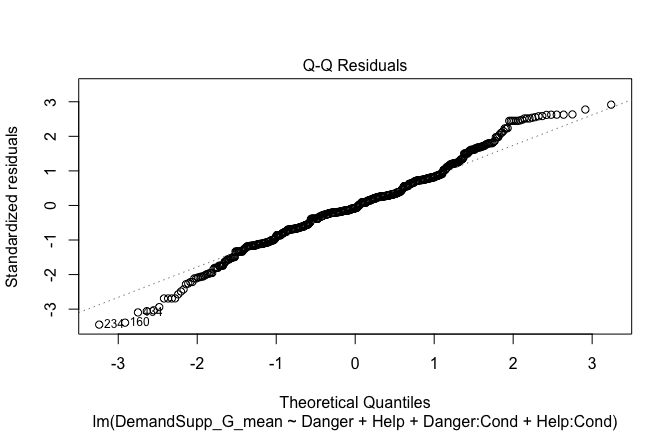
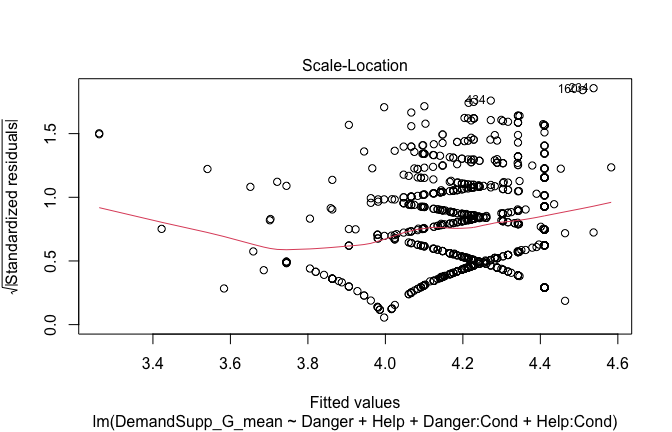
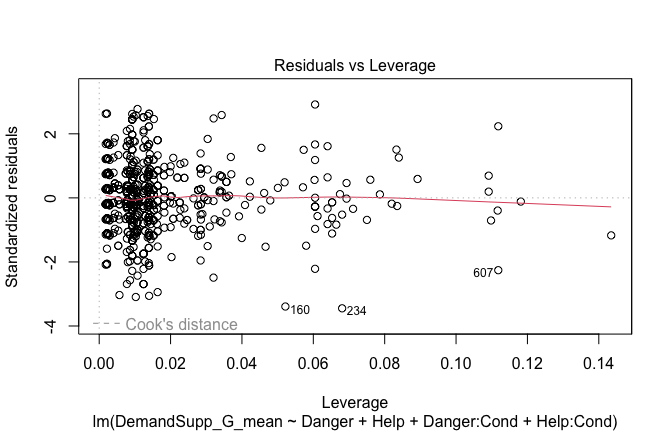
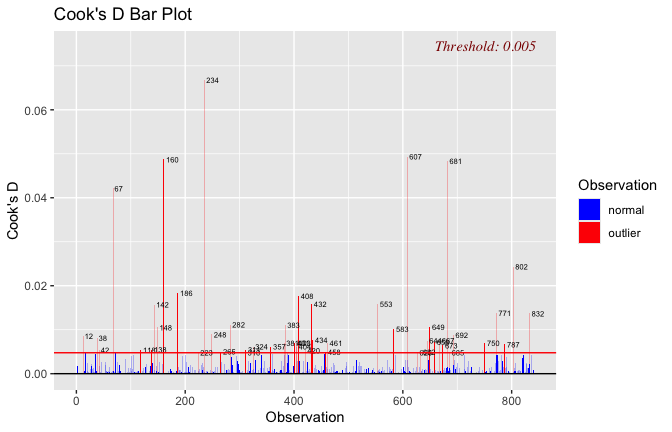
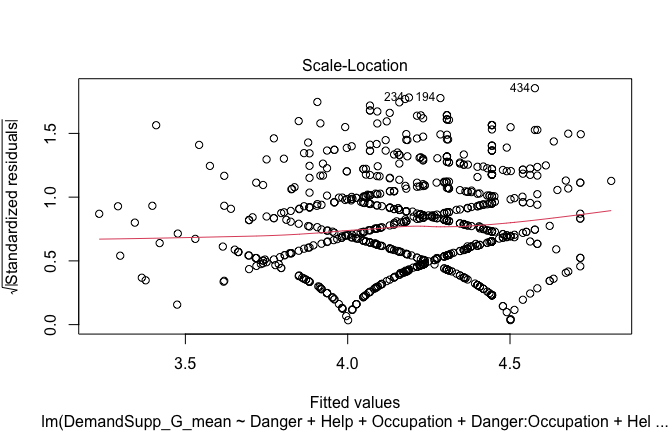
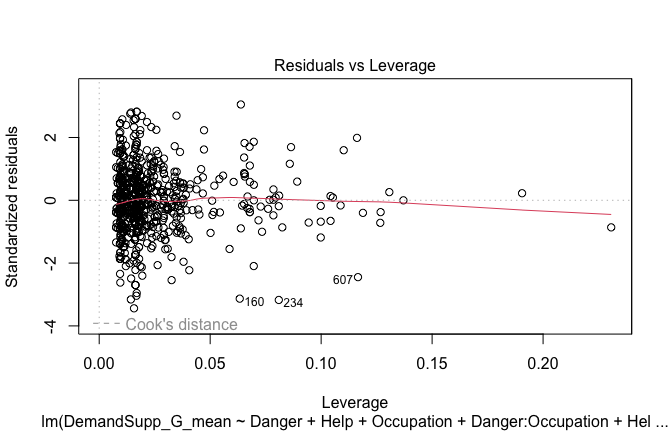
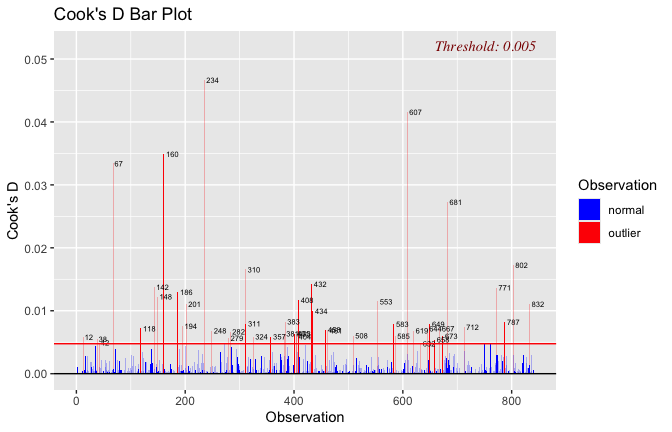
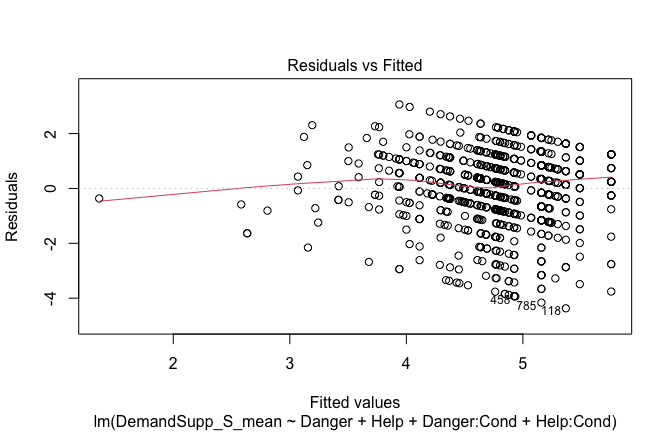
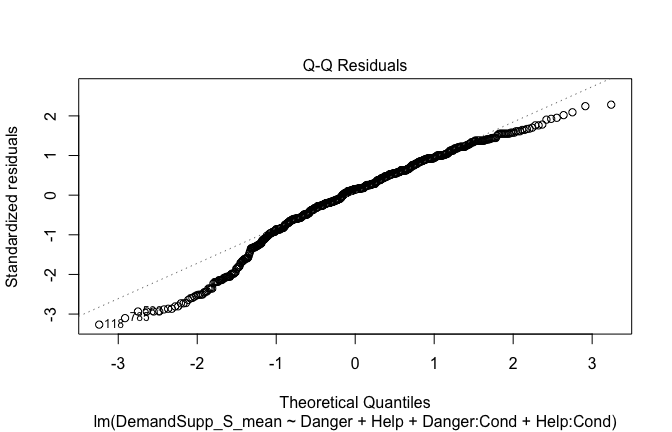
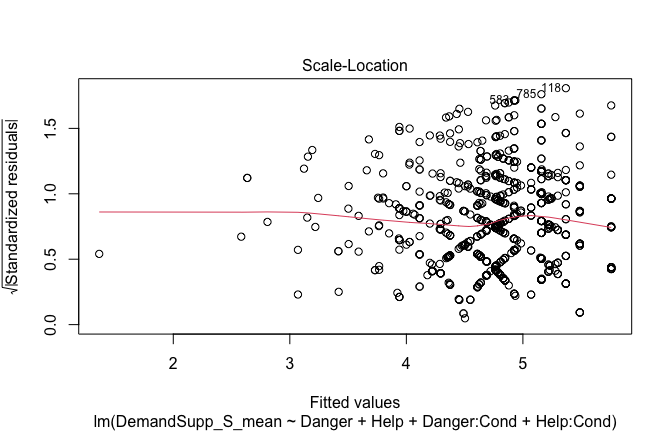
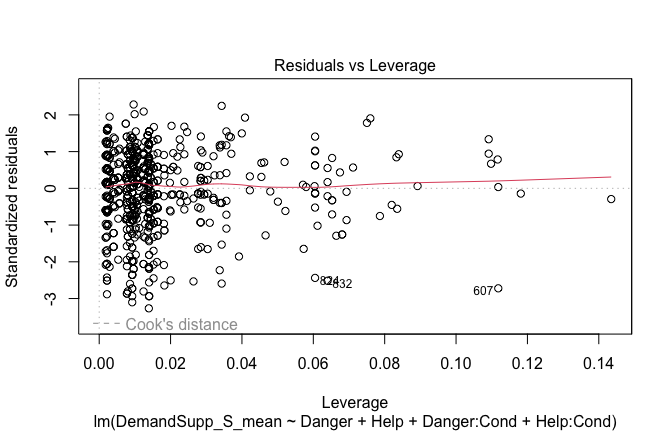
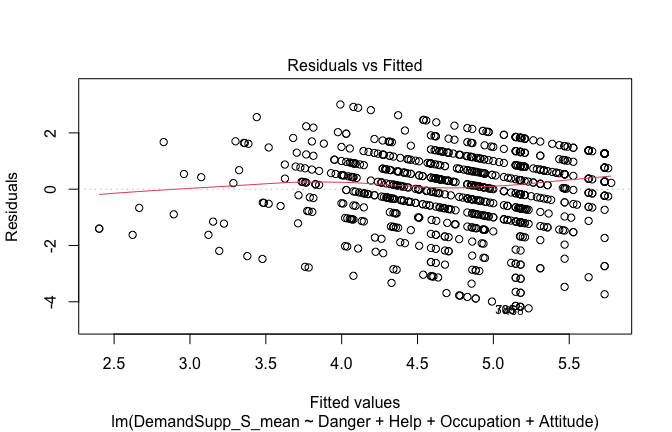
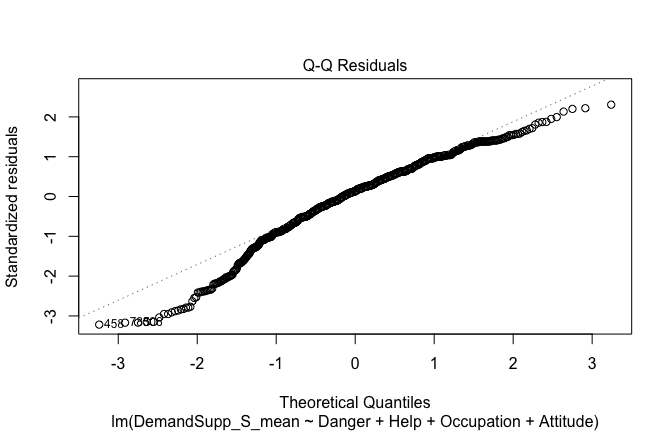
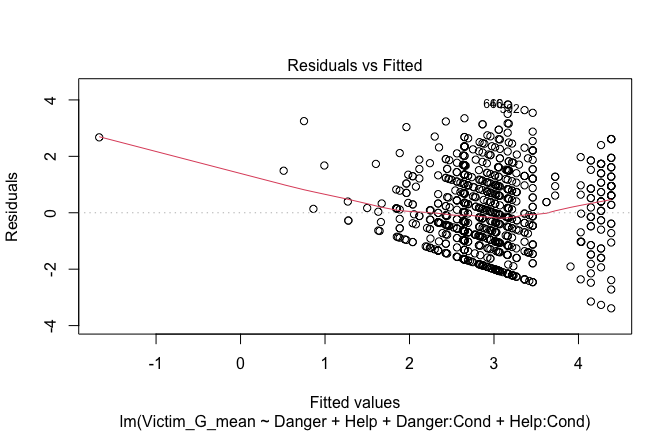
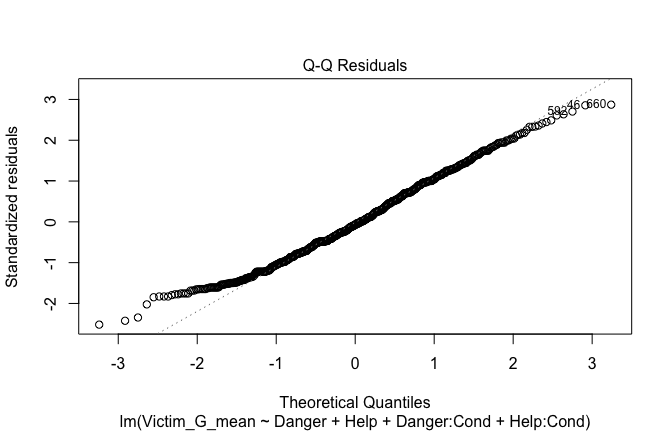
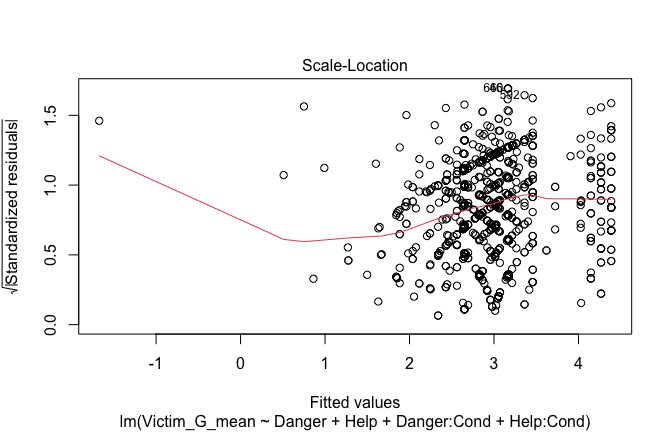
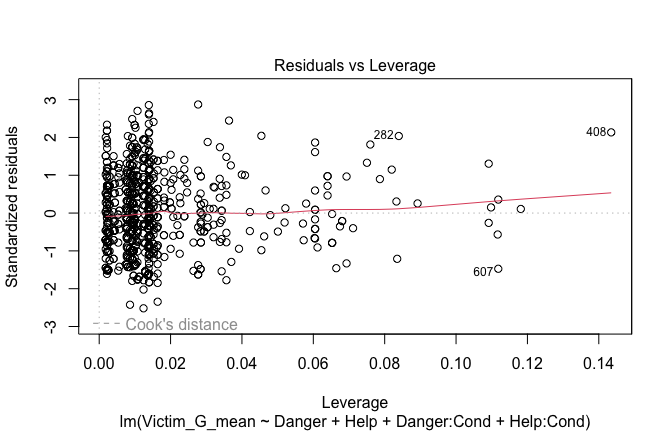
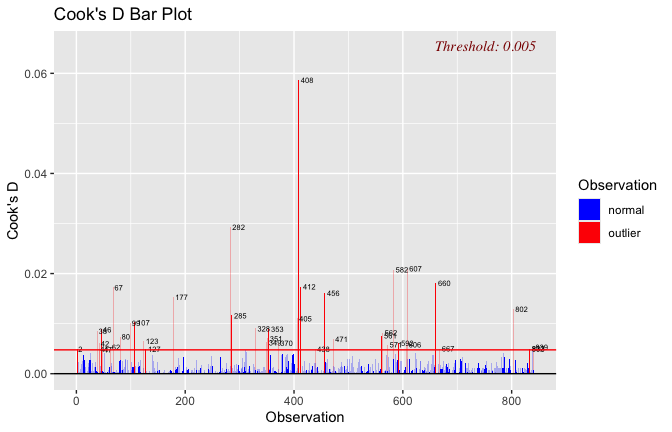
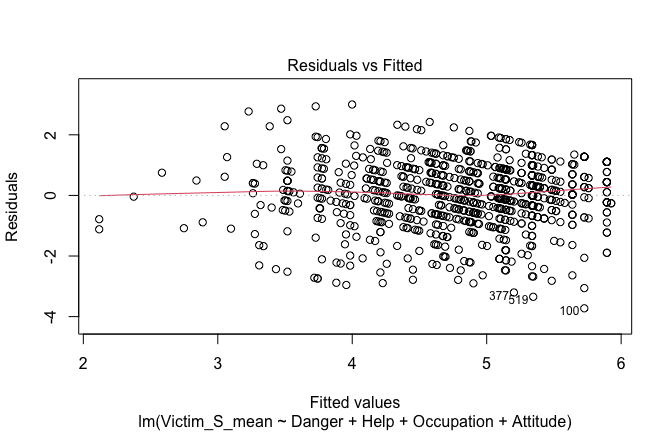
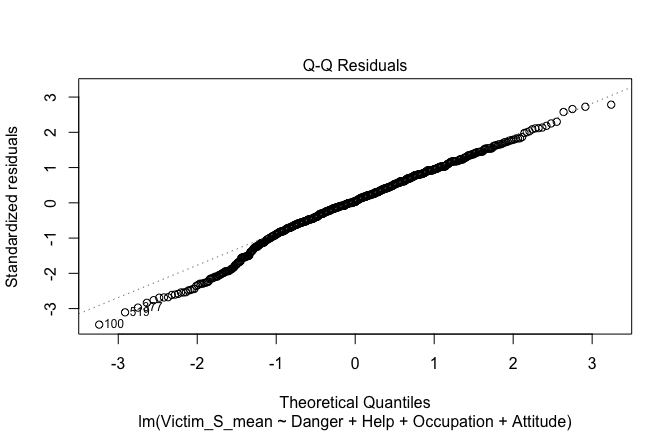
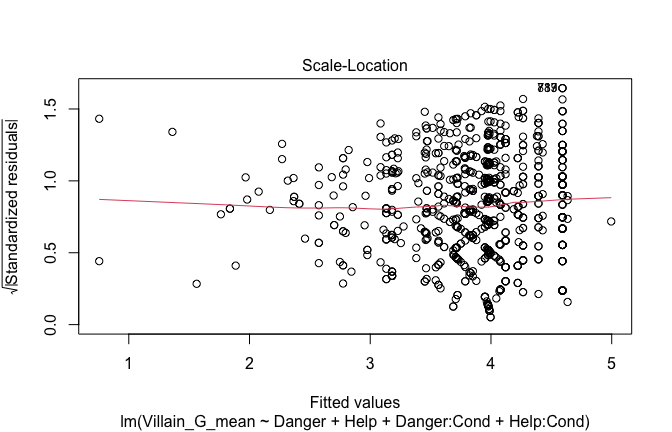
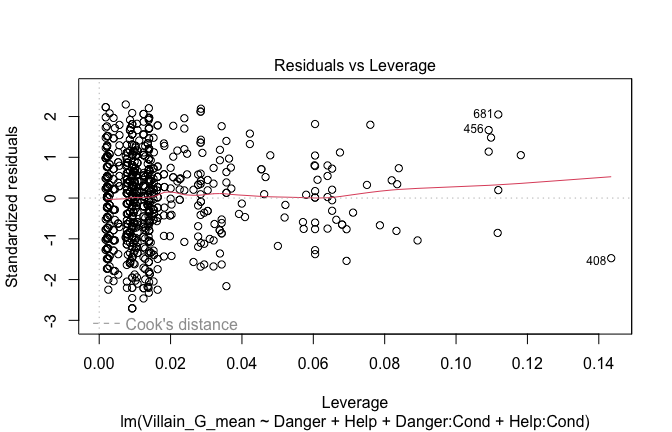
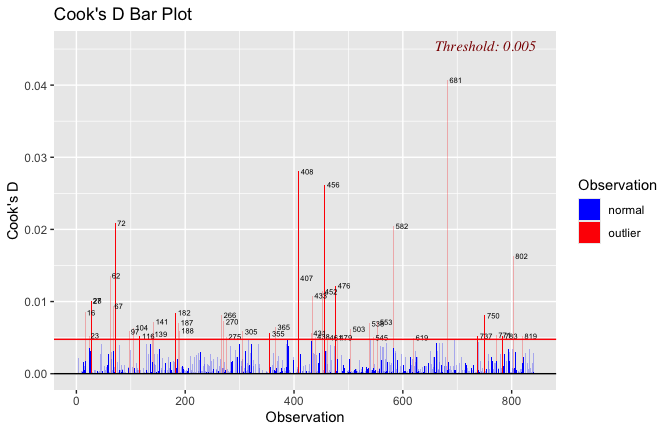
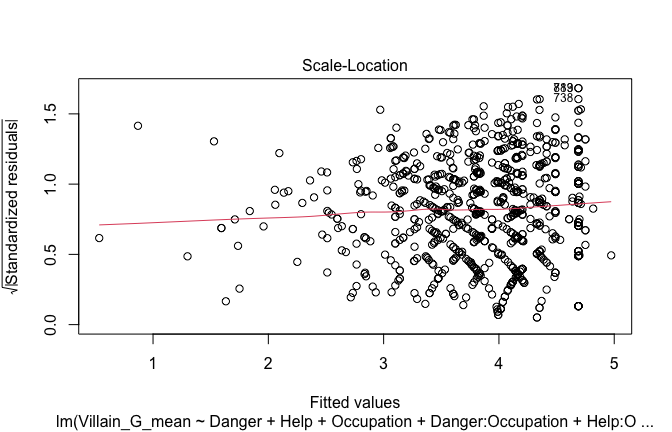
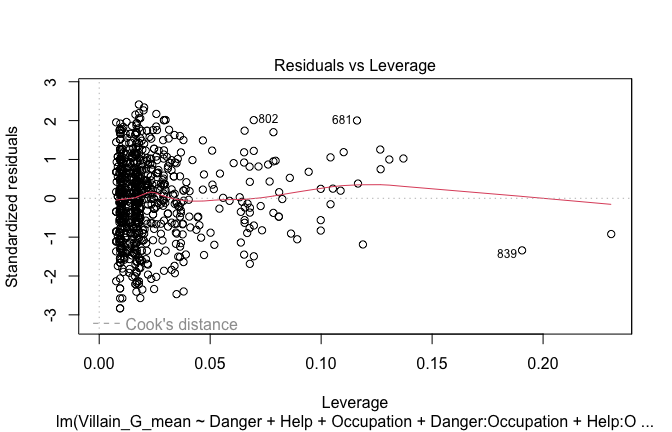
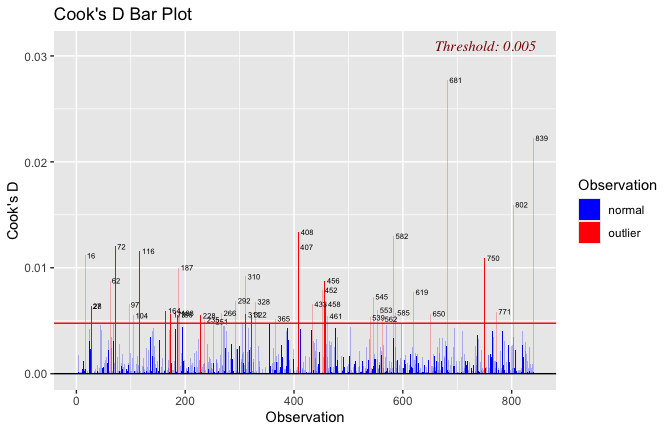
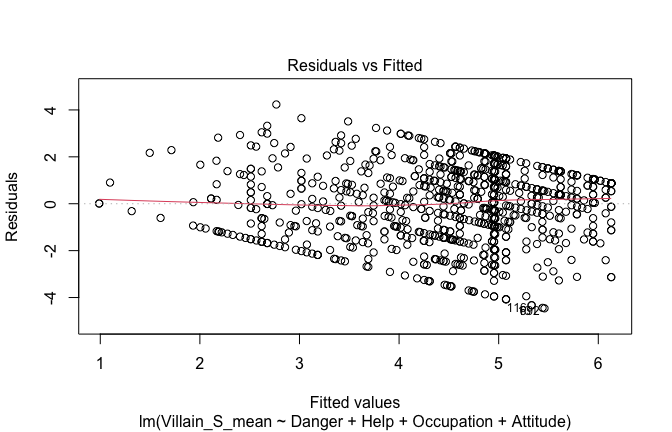
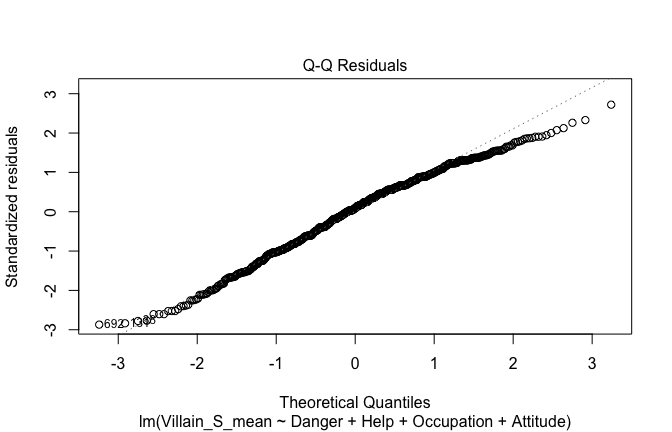
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
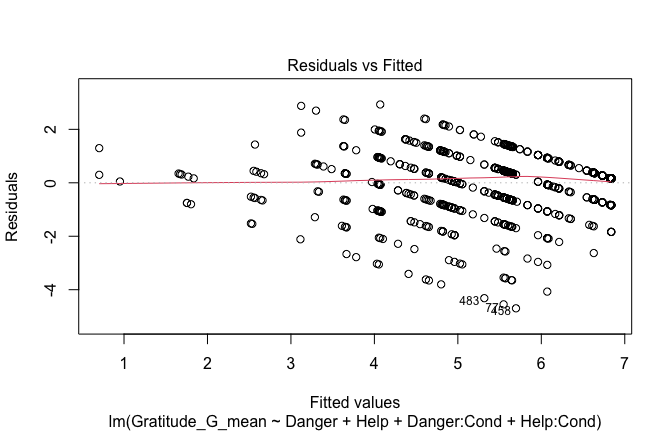
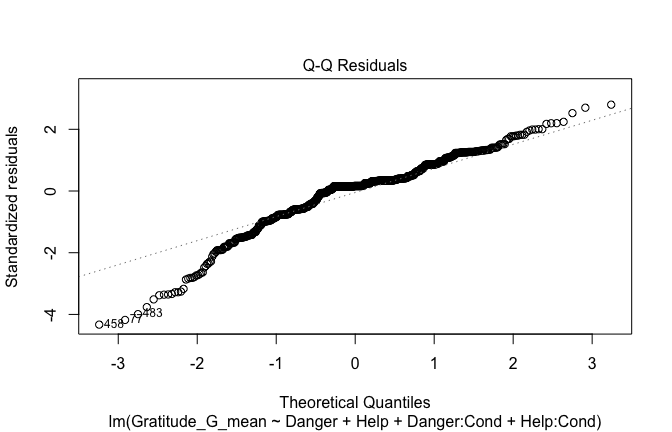
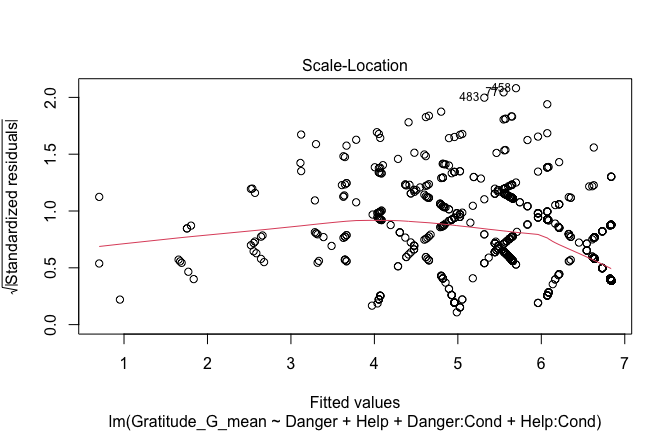
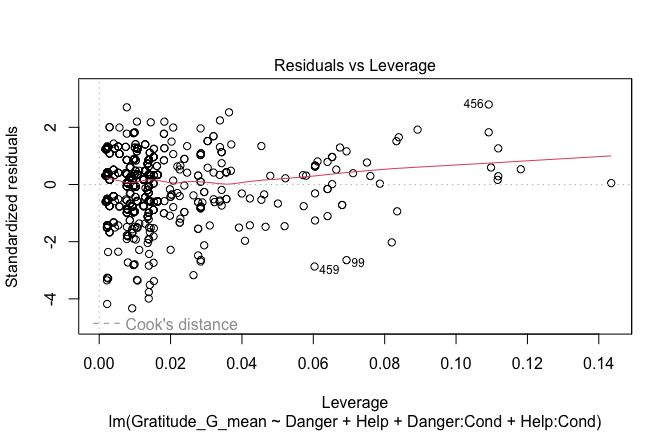
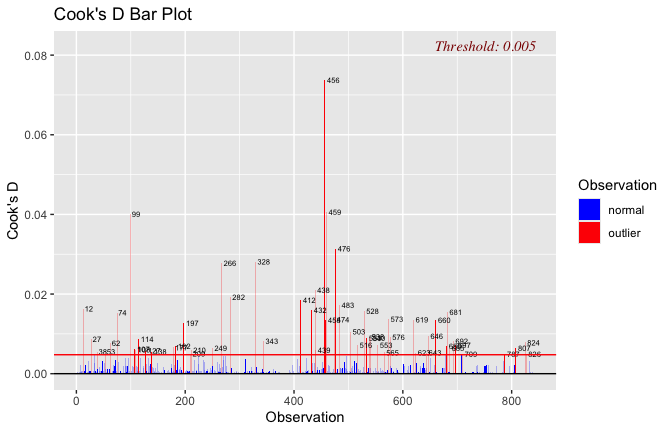
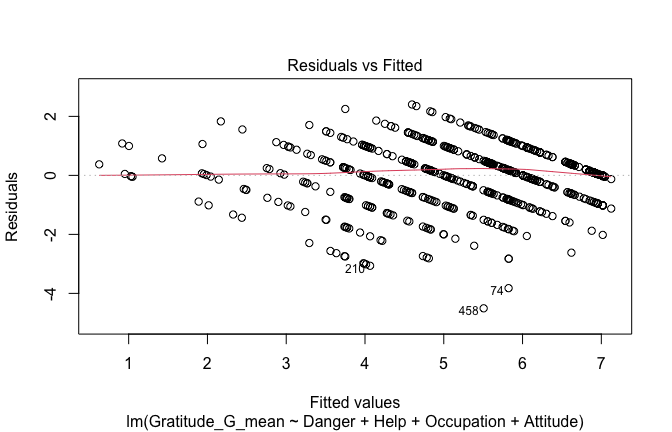
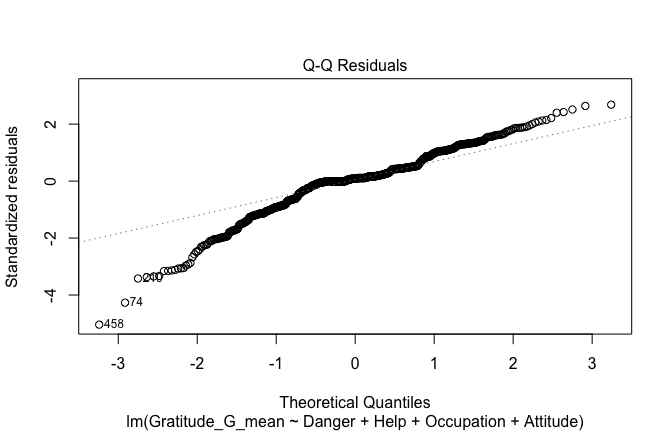
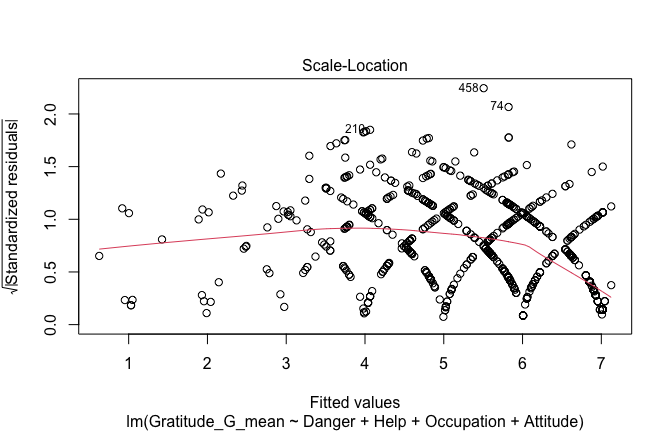
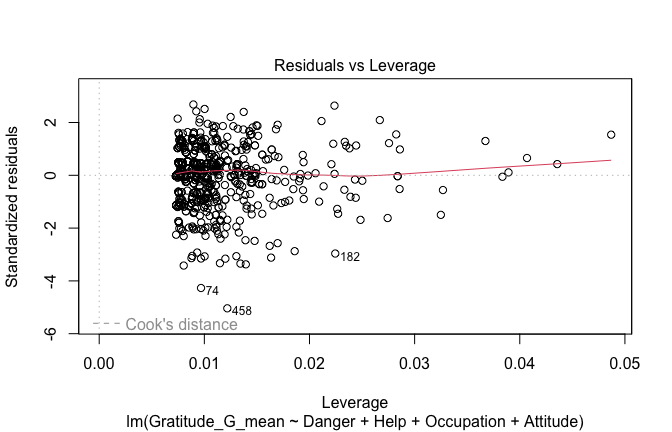
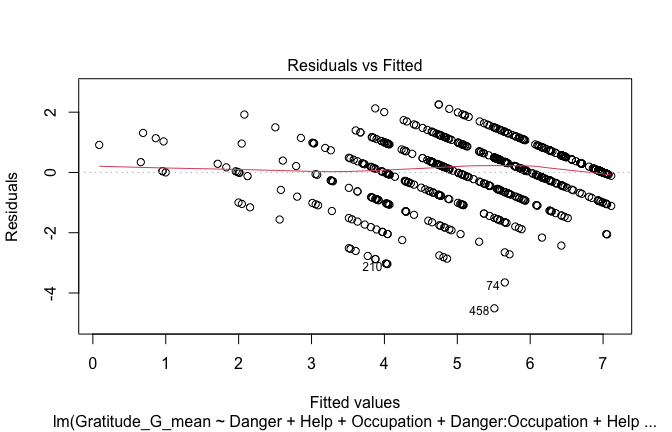
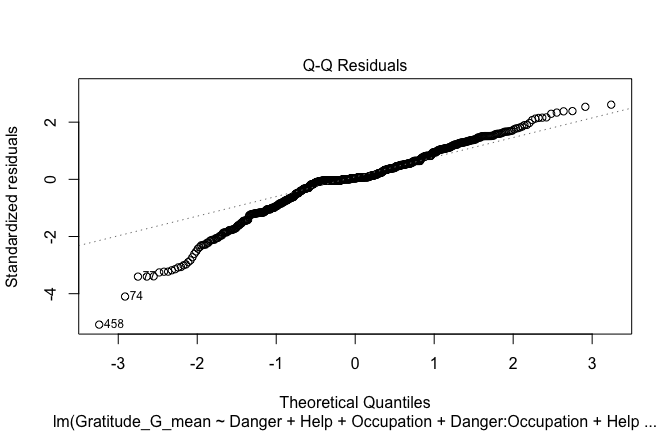
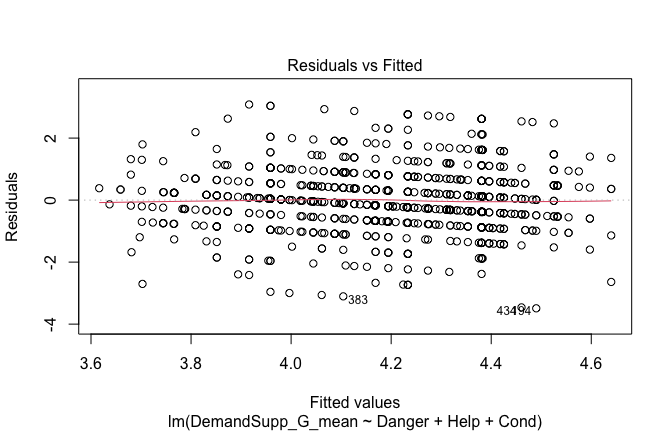
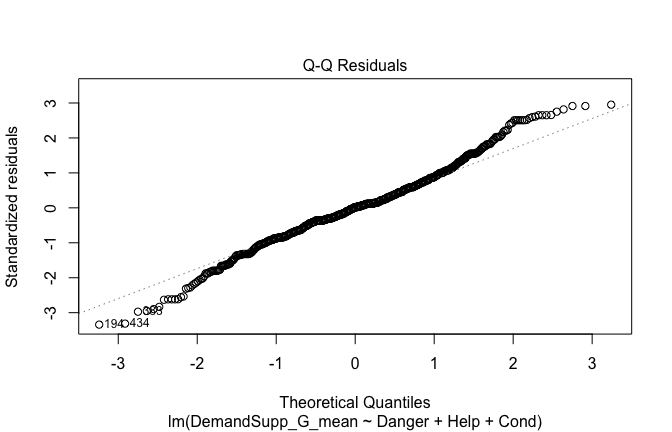
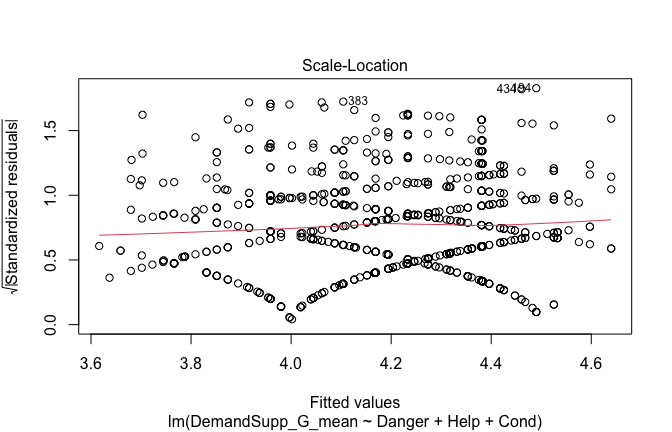
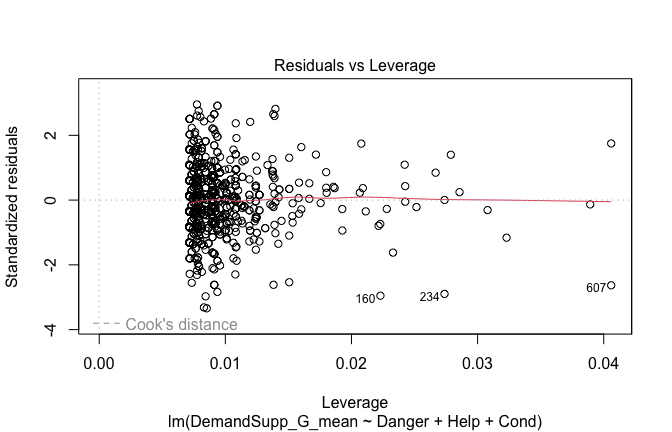
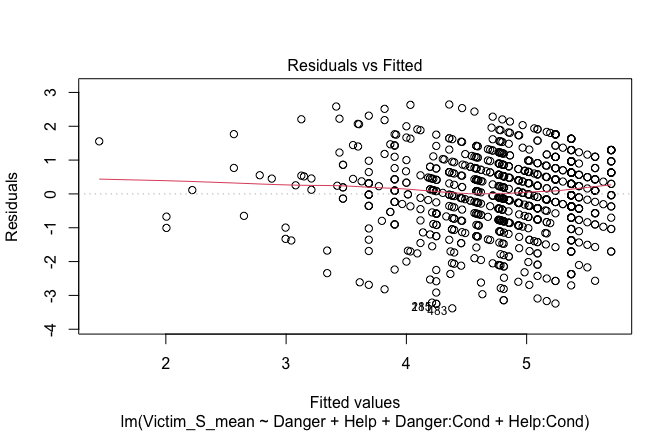
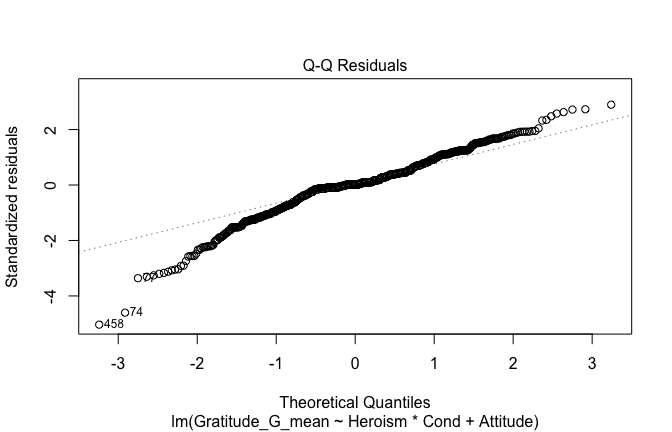
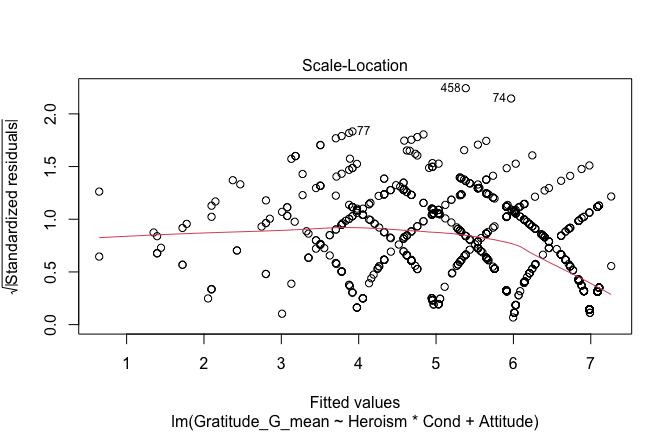
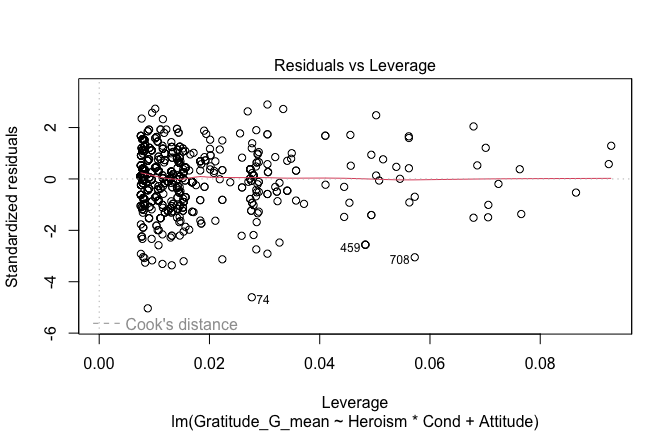
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(Gratitude_G_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(Gratitude_G_mean ~ Heroism + Cond, data = scale_scores)
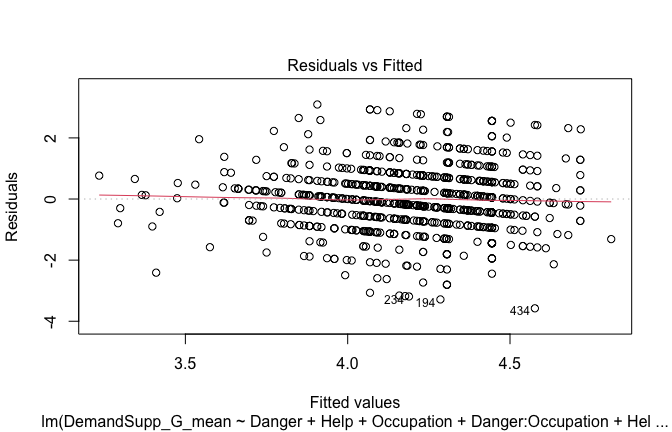
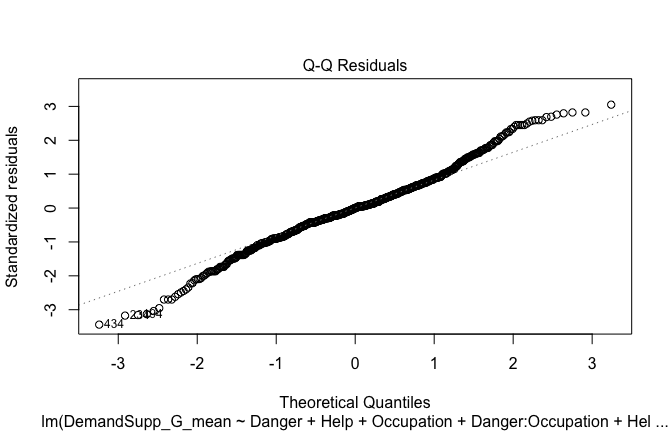
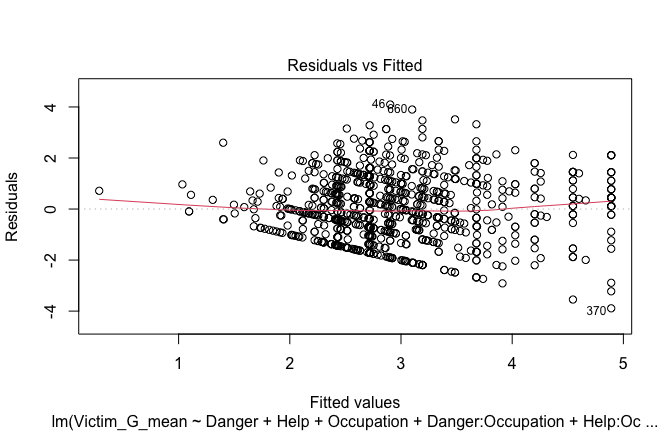
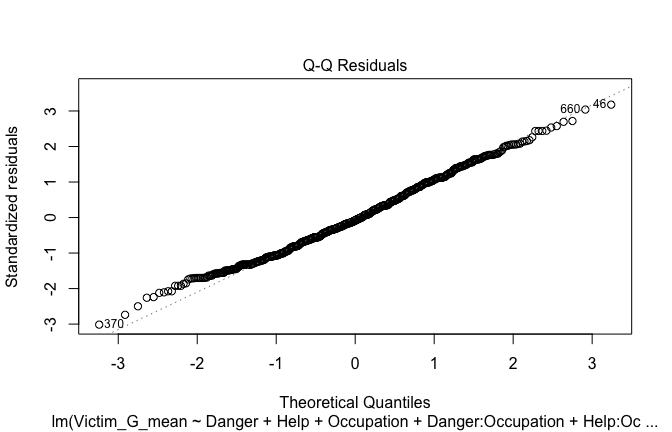
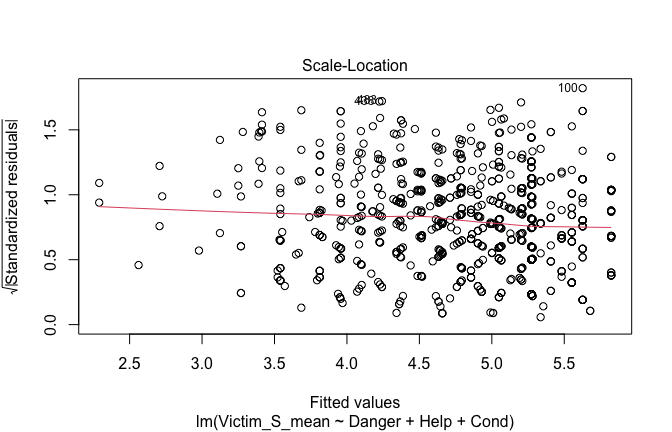
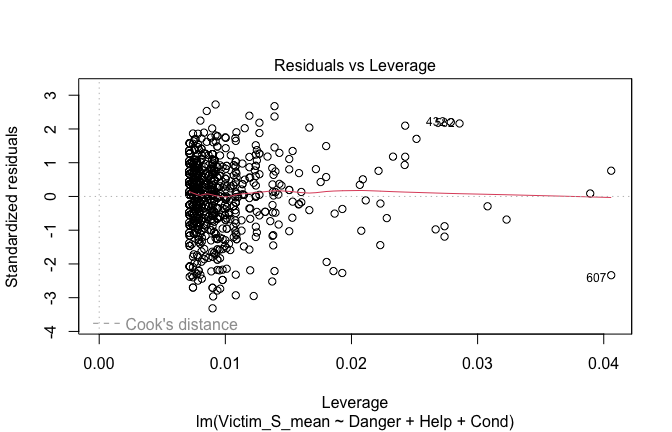
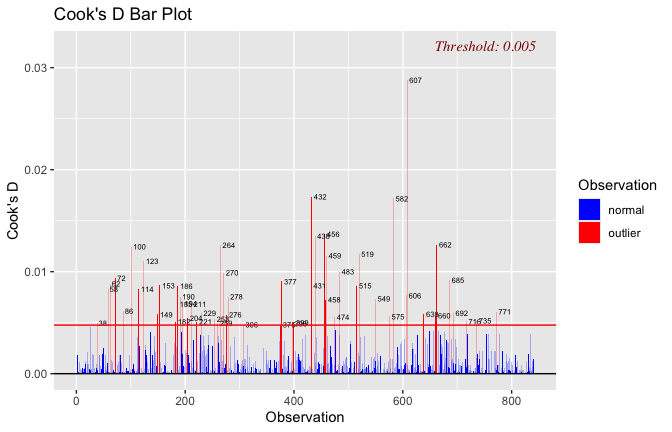
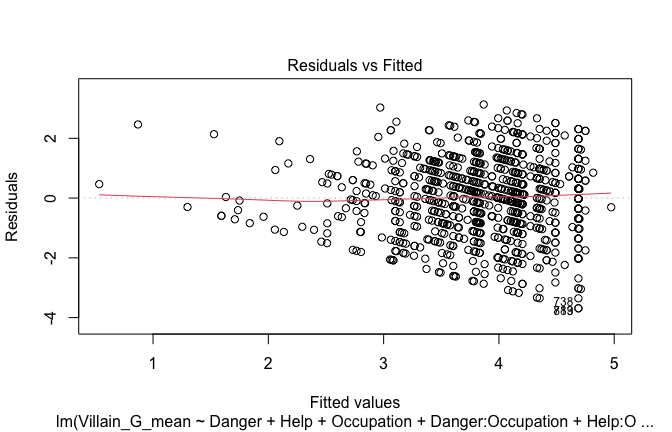
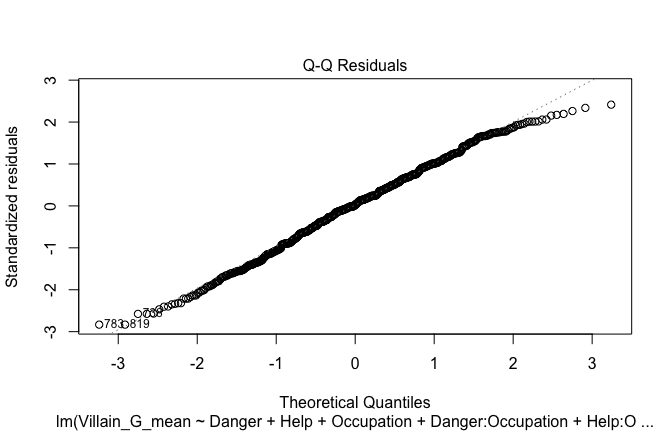
plot(mod1)
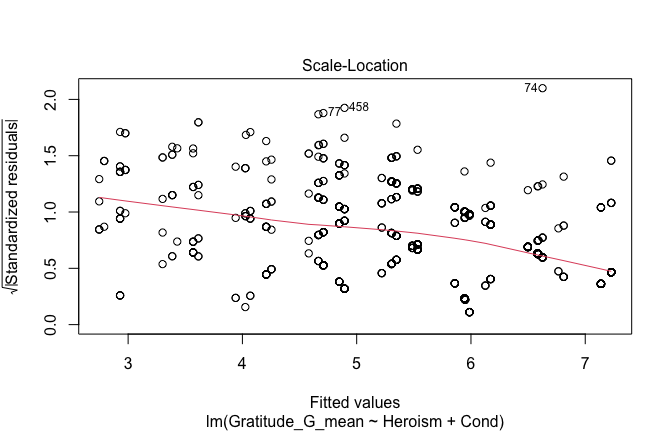
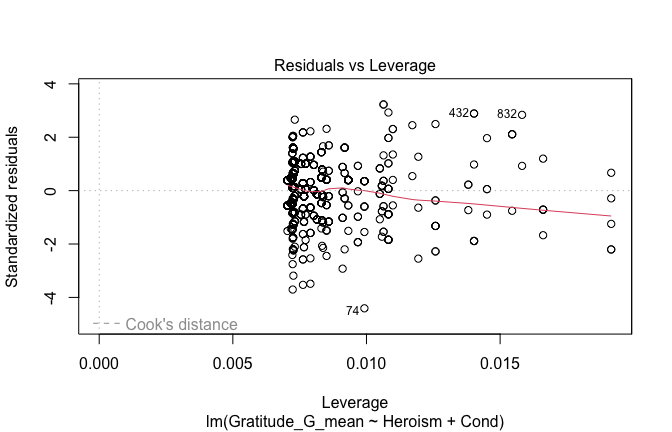
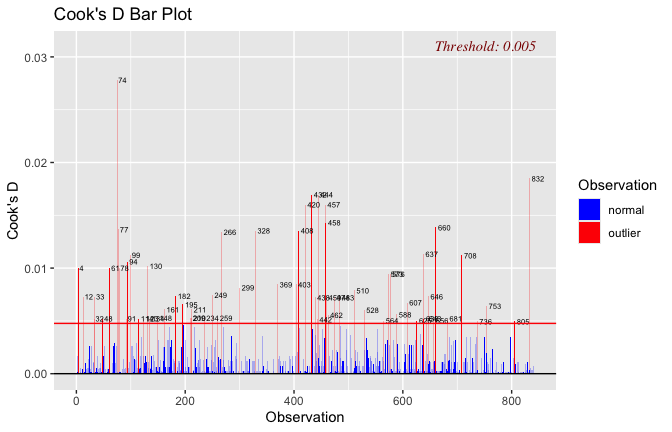
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.383 | 2.264 |
| (0.128) | (0.222) | |
| 18.555 | 10.211 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.639 | 0.669 |
| (0.025) | (0.038) | |
| 25.560 | 17.402 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.369 | 0.305 |
| (0.085) | (0.067) | |
| 4.345 | 4.537 | |
| p = <0.001 | p = <0.001 | |
| Cond2 | −0.093 | −0.097 |
| (0.088) | (0.110) | |
| −1.054 | −0.876 | |
| p = 0.292 | p = 0.381 | |
| Cond3 | 0.279 | 0.201 |
| (0.083) | (0.067) | |
| 3.361 | 2.989 | |
| p = <0.001 | p = 0.003 | |
| Cond4 | −0.047 | −0.073 |
| (0.082) | (0.090) | |
| −0.575 | −0.807 | |
| p = 0.565 | p = 0.420 | |
| Cond5 | −0.276 | −0.198 |
| (0.082) | (0.088) | |
| −3.365 | −2.253 | |
| p = <0.001 | p = 0.025 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.546 | 0.609 |
| R2 Adj. | 0.542 | 0.606 |
| RMSE | 1.05 | 1.05 |
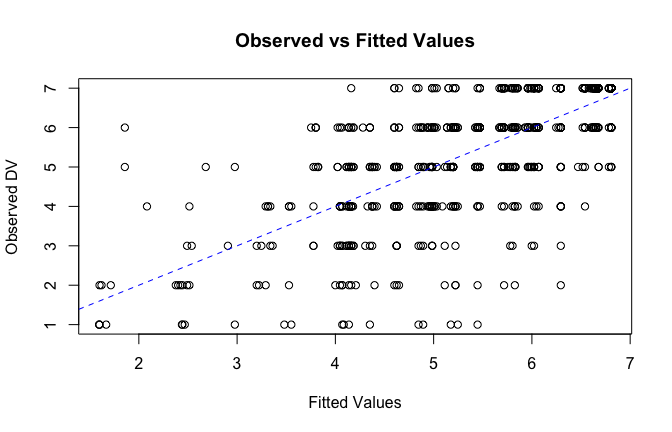
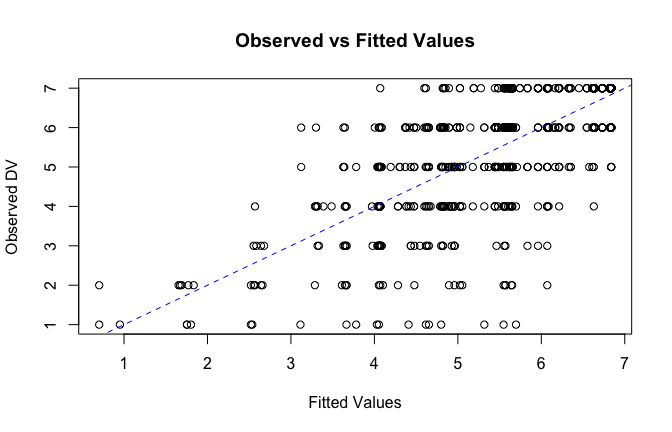
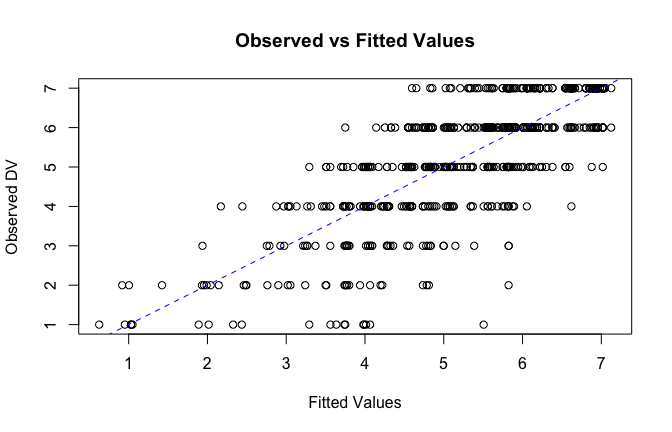
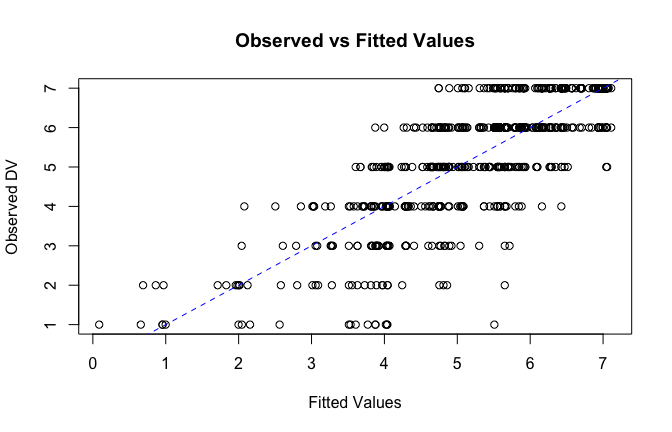
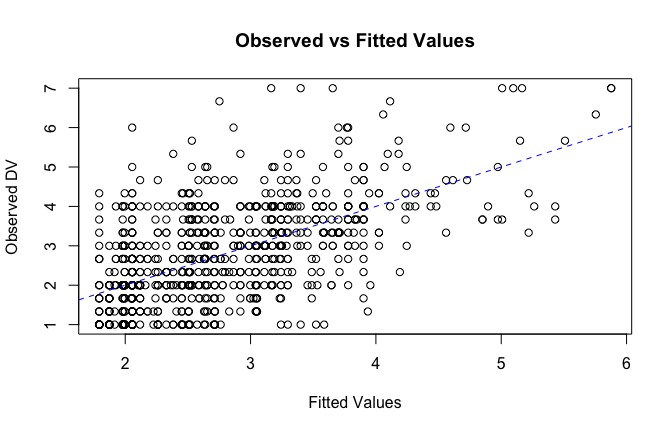
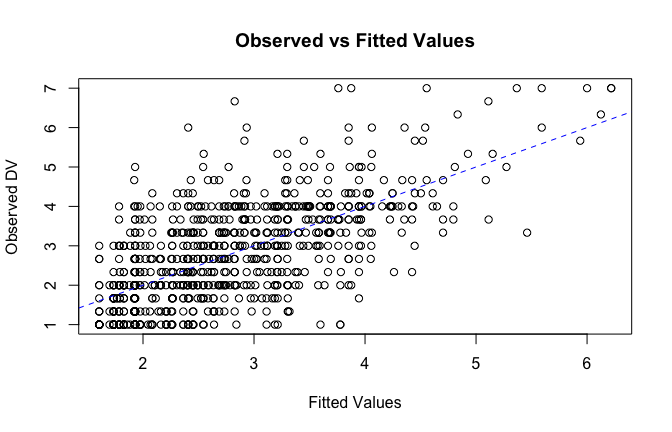
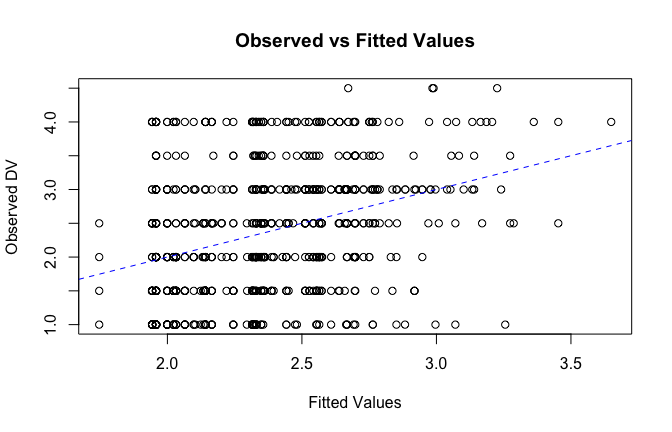
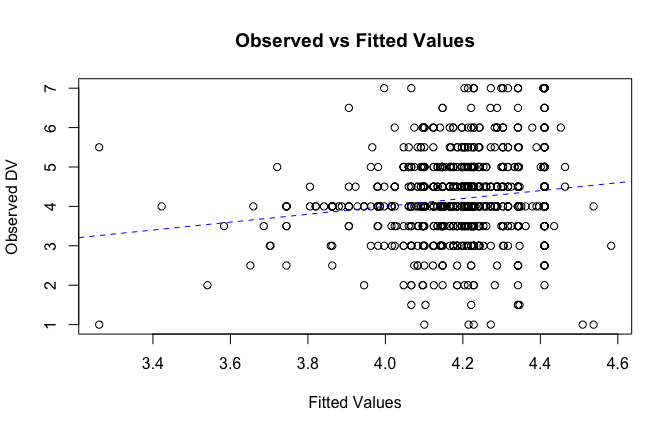
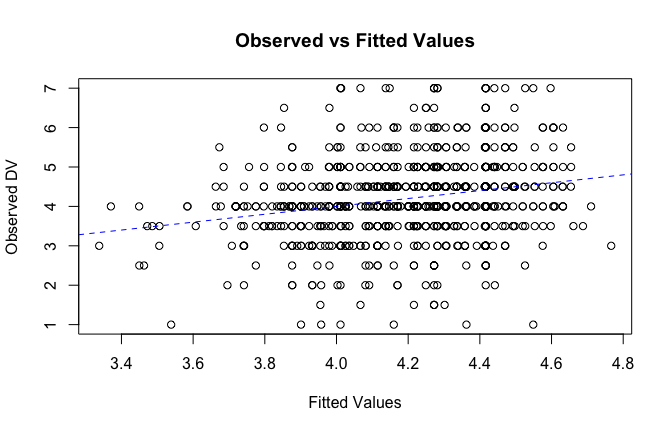
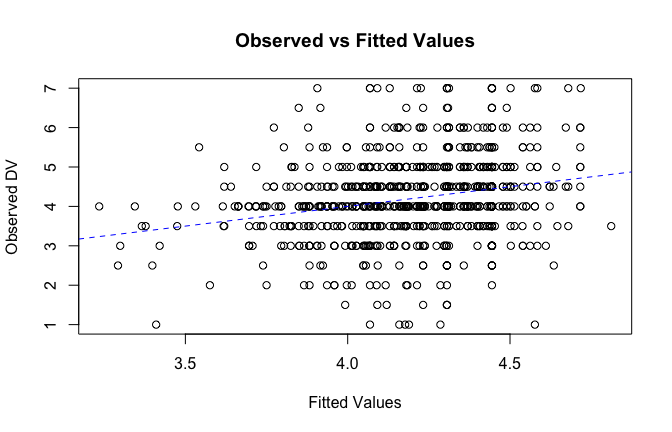
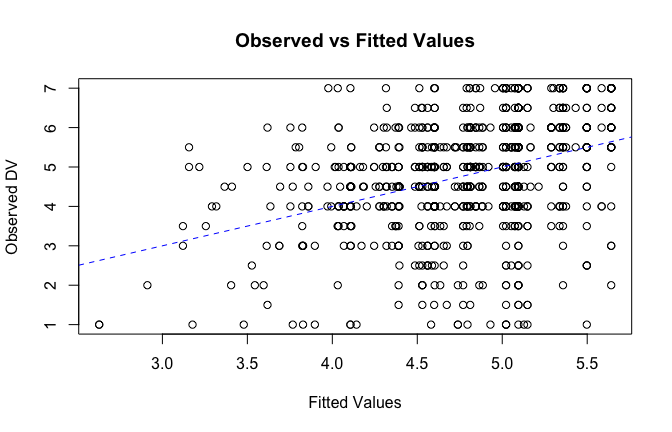
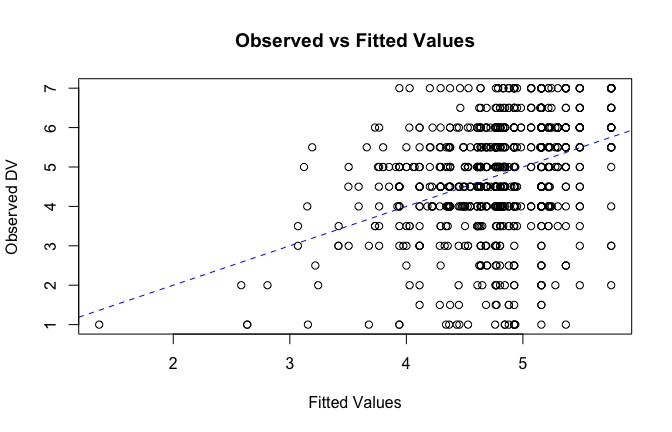
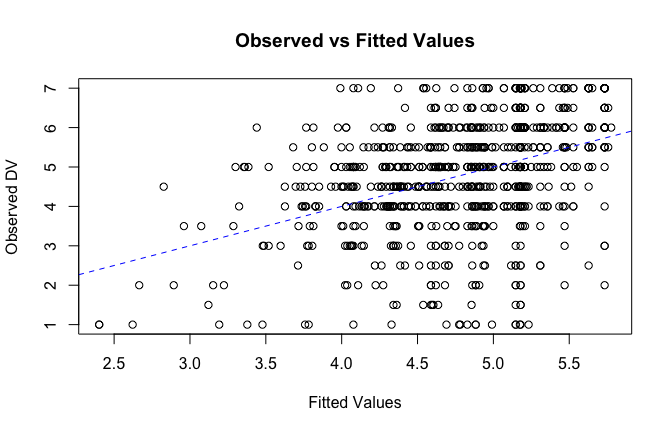
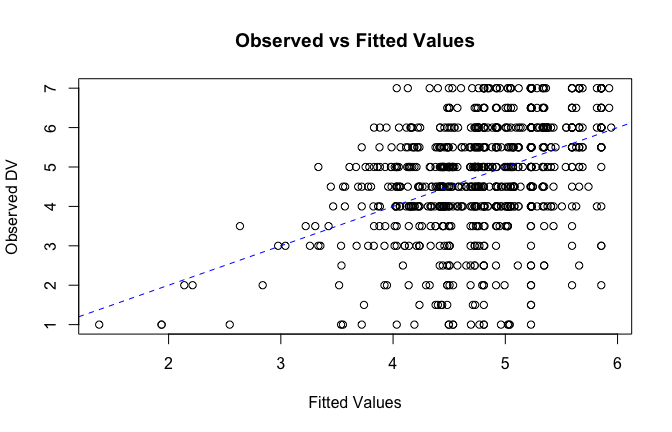
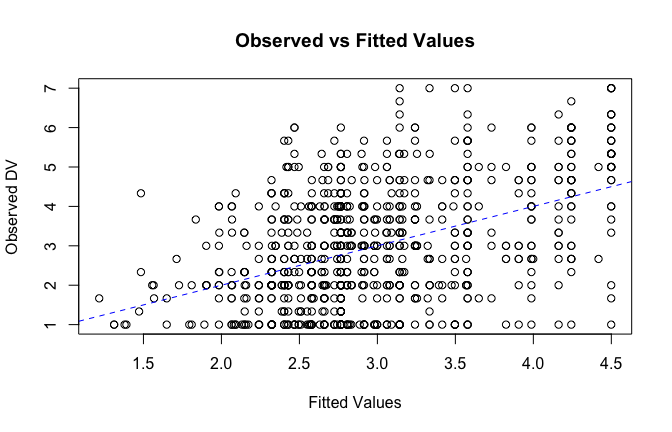
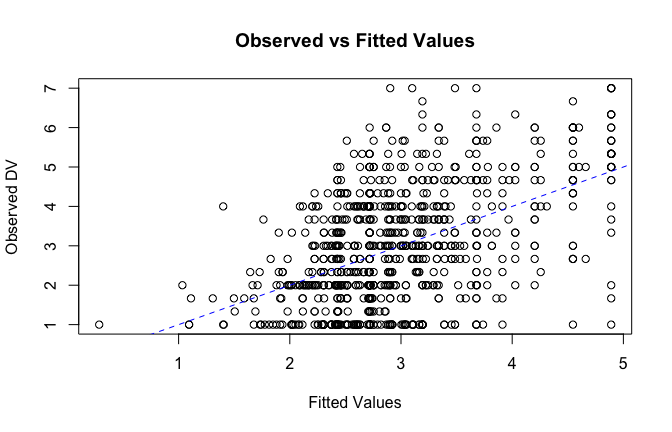
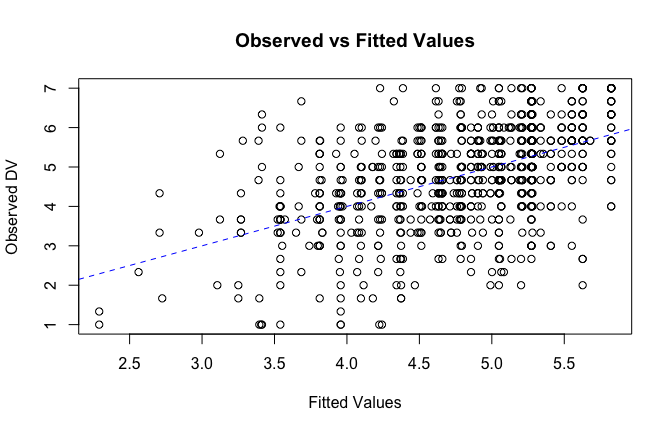
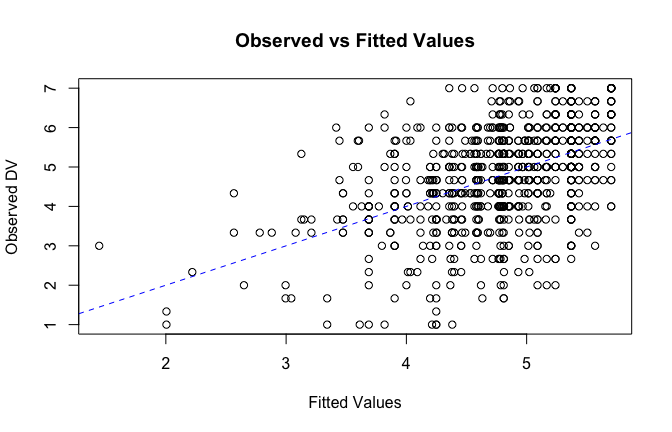
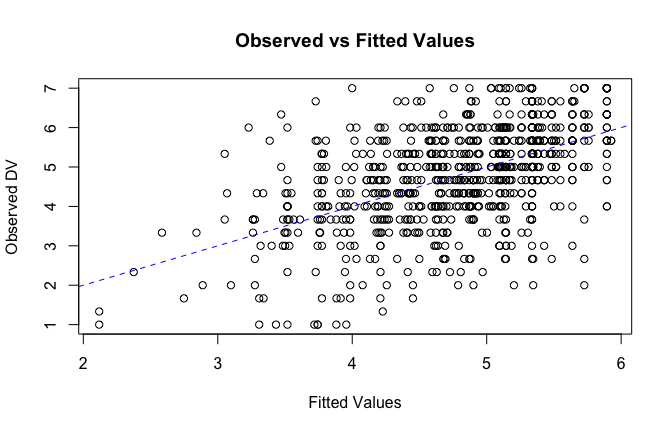
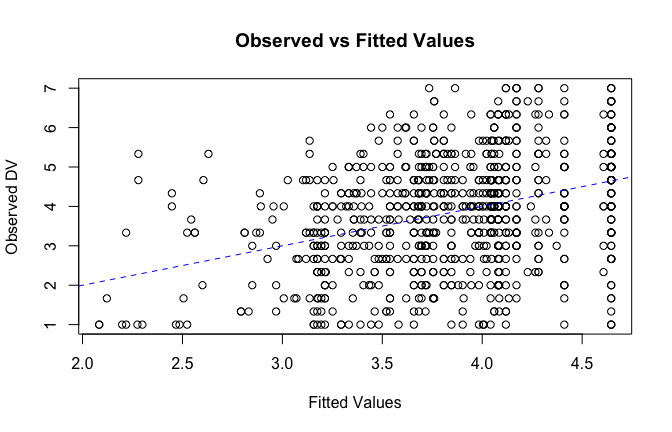
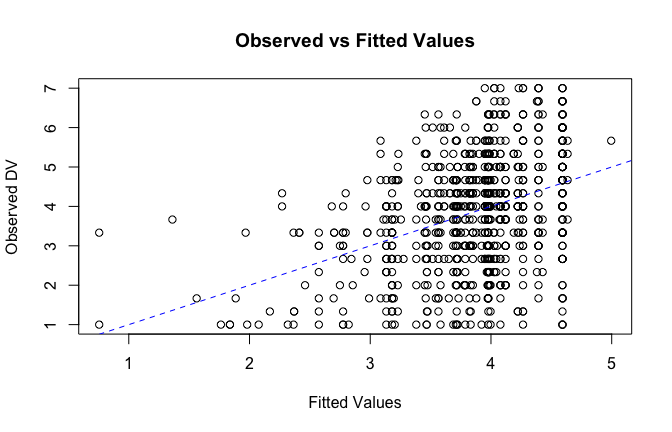
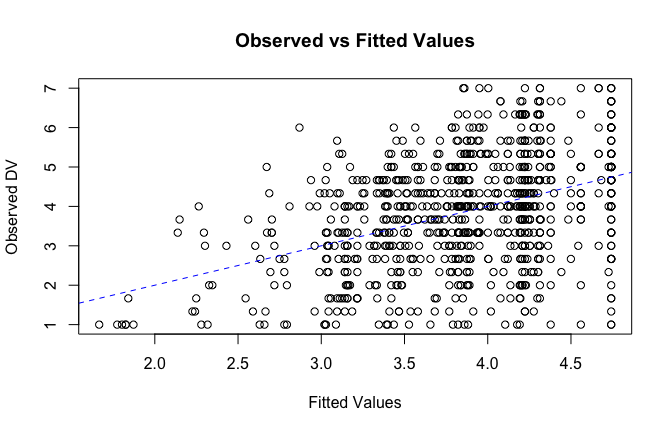
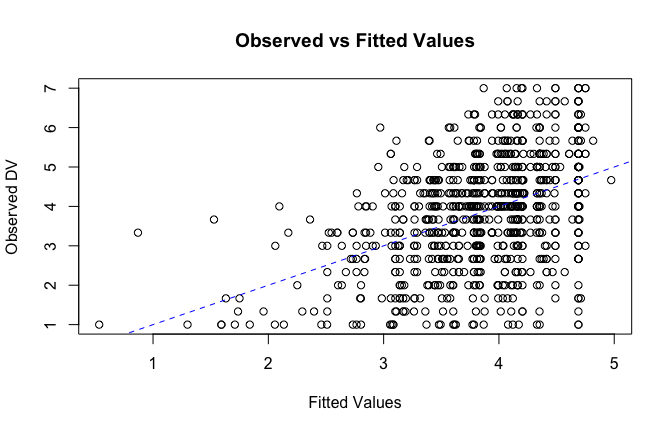
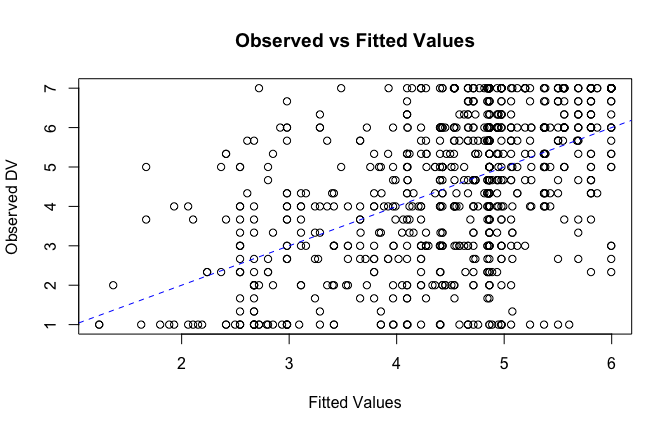
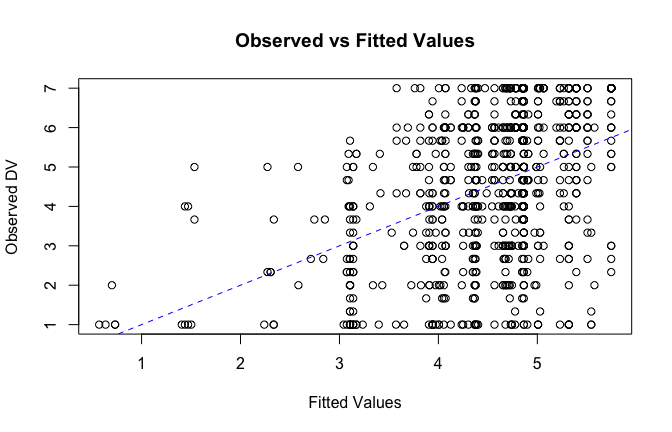
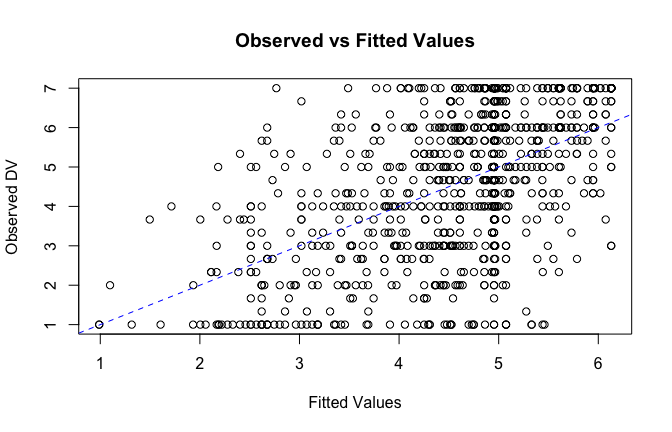
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
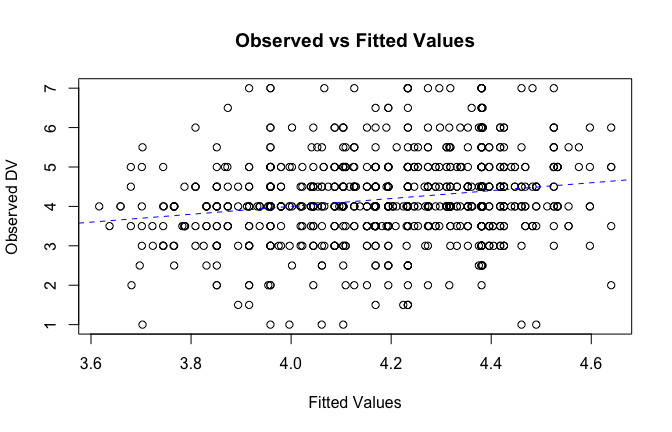
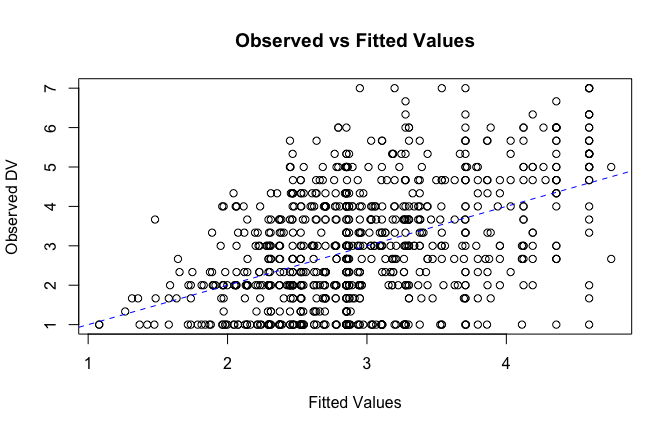
plot(fitted_vals, scale_scores$Gratitude_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)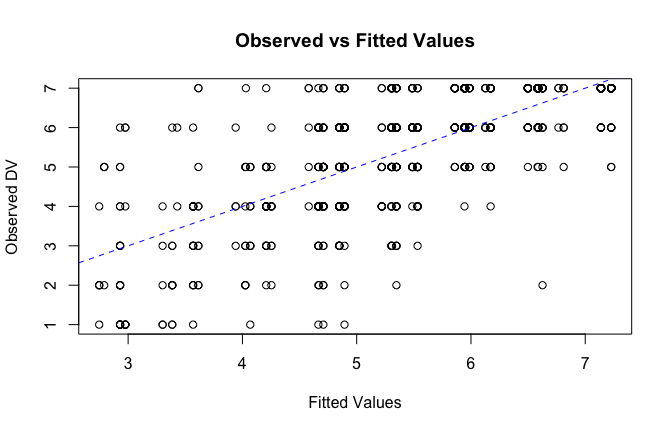
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(Gratitude_G_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(Gratitude_G_mean ~ Heroism * Cond, data = scale_scores)
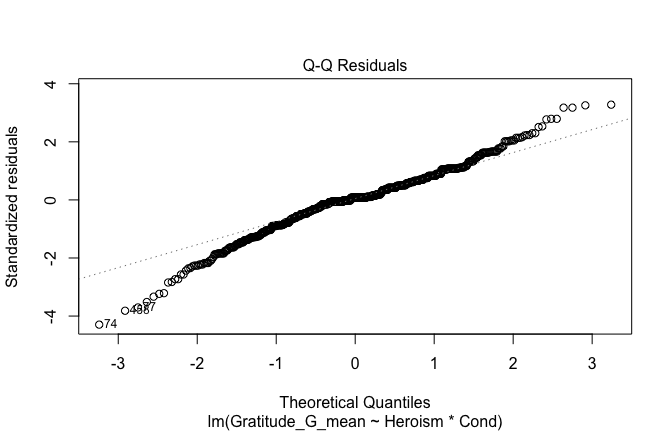
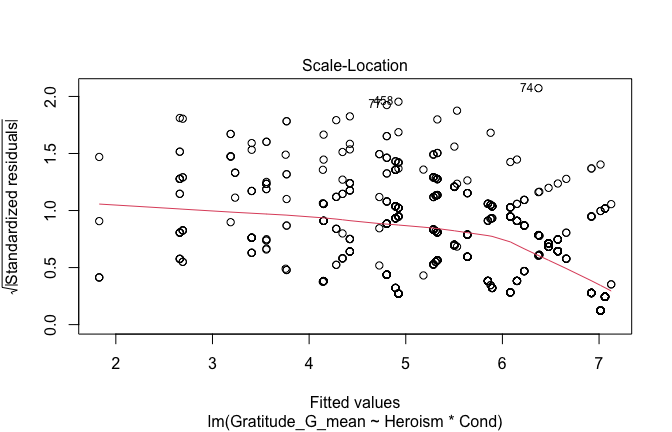
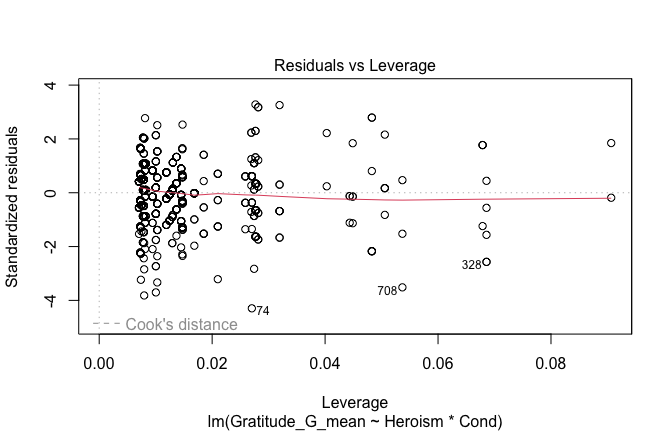
plot(mod1)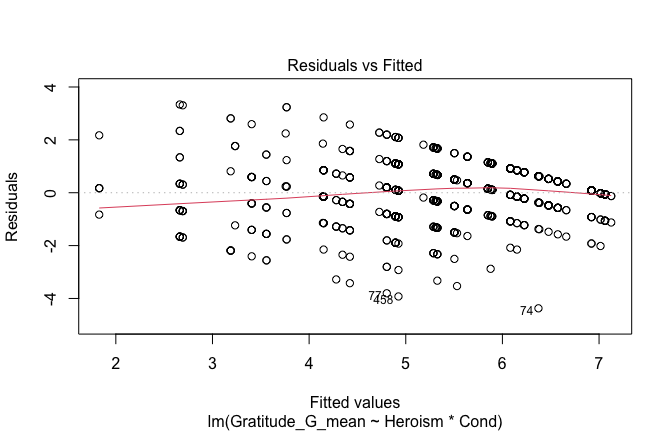
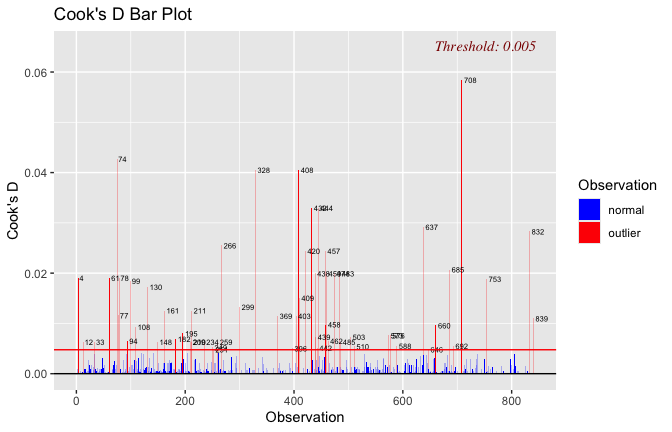
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.611 | 2.596 |
| (0.133) | (0.210) | |
| 19.674 | 12.379 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.607 | 0.626 |
| (0.025) | (0.037) | |
| 24.080 | 17.059 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 1.877 | 2.536 |
| (0.397) | (0.440) | |
| 4.731 | 5.760 | |
| p = <0.001 | p = <0.001 | |
| Cond2 | −0.693 | −0.929 |
| (0.226) | (0.323) | |
| −3.071 | −2.875 | |
| p = 0.002 | p = 0.004 | |
| Cond3 | 0.364 | 0.667 |
| (0.295) | (0.546) | |
| 1.233 | 1.222 | |
| p = 0.218 | p = 0.222 | |
| Cond4 | −0.001 | −0.592 |
| (0.266) | (0.605) | |
| −0.004 | −0.978 | |
| p = 0.996 | p = 0.328 | |
| Cond5 | −1.647 | −1.794 |
| (0.265) | (0.344) | |
| −6.205 | −5.220 | |
| p = <0.001 | p = <0.001 | |
| Heroism × Cond1 | −0.259 | −0.372 |
| (0.067) | (0.070) | |
| −3.891 | −5.324 | |
| p = <0.001 | p = <0.001 | |
| Heroism × Cond2 | 0.137 | 0.175 |
| (0.054) | (0.067) | |
| 2.559 | 2.596 | |
| p = 0.011 | p = 0.010 | |
| Heroism × Cond3 | −0.023 | −0.089 |
| (0.052) | (0.086) | |
| −0.448 | −1.035 | |
| p = 0.654 | p = 0.301 | |
| Heroism × Cond4 | −0.028 | 0.082 |
| (0.055) | (0.114) | |
| −0.515 | 0.717 | |
| p = 0.607 | p = 0.473 | |
| Heroism × Cond5 | 0.258 | 0.273 |
| (0.050) | (0.055) | |
| 5.168 | 4.941 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.567 | 0.660 |
| R2 Adj. | 0.562 | 0.655 |
| RMSE | 1.02 | 1.03 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)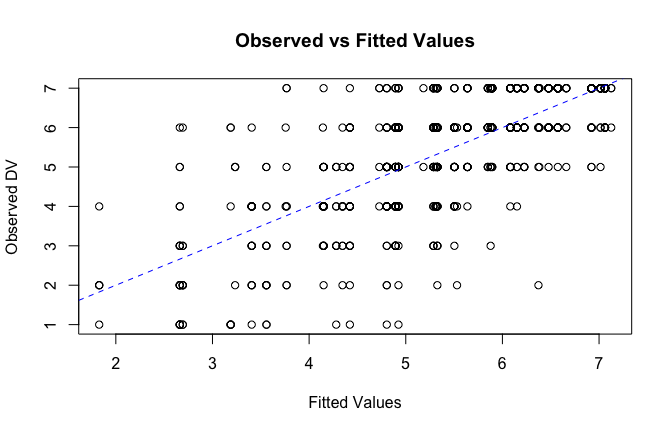
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Gratitude_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Gratitude_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)## Warning in lmrob.S(x, y, control = control): S-estimated scale == 0: Probably
## exact fit; check your data## Warning in lmrob.fit(x, y, control, init = init): initial estim. 'init' not
## converged -- will be return()ed basically unchanged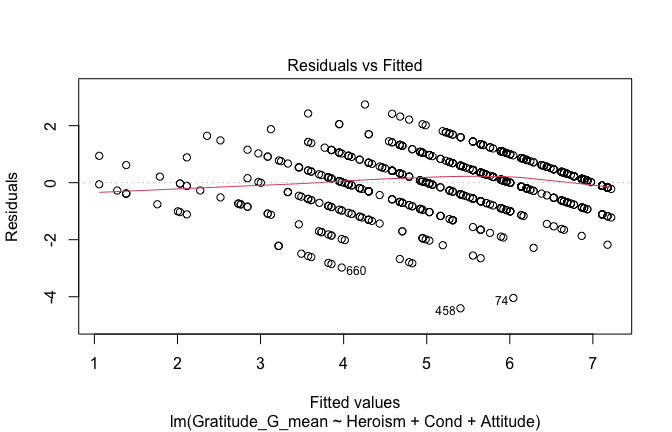
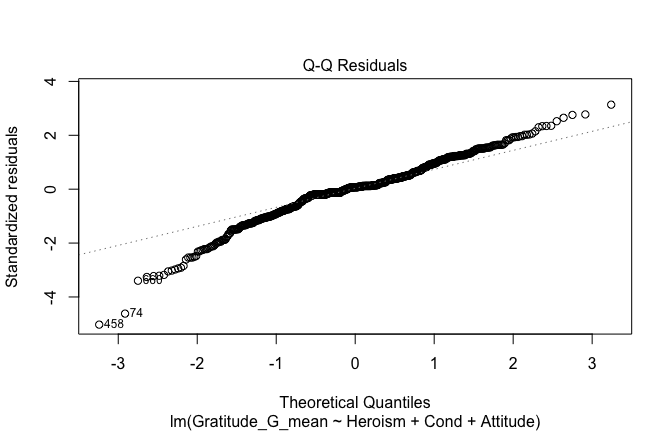
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.337 | 5.839 |
| (0.148) | (0.000) | |
| 29.250 | ||
| p = <0.001 | ||
| Heroism | 0.243 | −0.000 |
| (0.029) | (0.000) | |
| 8.249 | ||
| p = <0.001 | ||
| Cond1 | 0.169 | −0.167 |
| (0.072) | (0.000) | |
| 2.363 | ||
| p = 0.018 | ||
| Cond2 | 0.213 | 0.833 |
| (0.075) | (0.000) | |
| 2.831 | ||
| p = 0.005 | ||
| Cond3 | 0.106 | −0.167 |
| (0.070) | (0.000) | |
| 1.511 | ||
| p = 0.131 | ||
| Cond4 | −0.142 | −0.167 |
| (0.068) | (0.000) | |
| −2.071 | ||
| p = 0.039 | ||
| Cond5 | −0.112 | −0.167 |
| (0.069) | (0.000) | |
| −1.620 | ||
| p = 0.106 | ||
| Attitude | 0.943 | 1.291 |
| (0.049) | (0.000) | |
| 19.073 | ||
| p = <0.001 | ||
| Num.Obs. | 840 | 840 |
| R2 | 0.684 | 1.000 |
| R2 Adj. | 0.681 | 1.000 |
| RMSE | 0.88 | 1.02 |
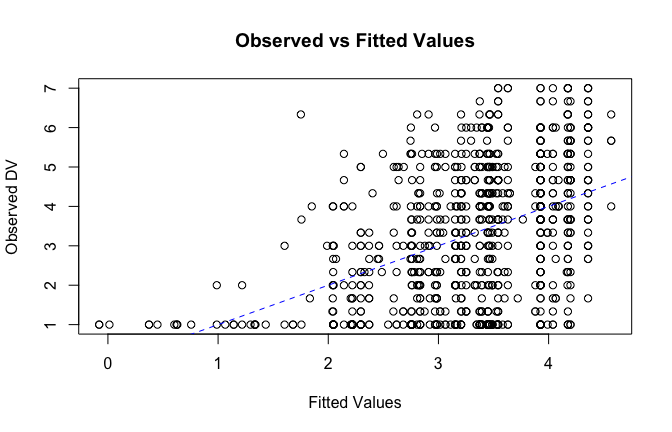
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
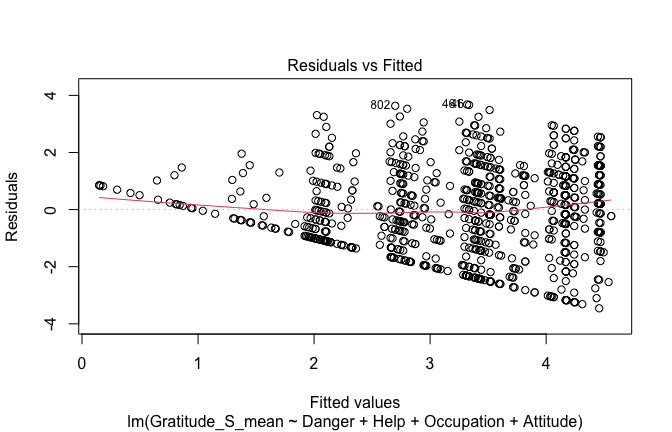
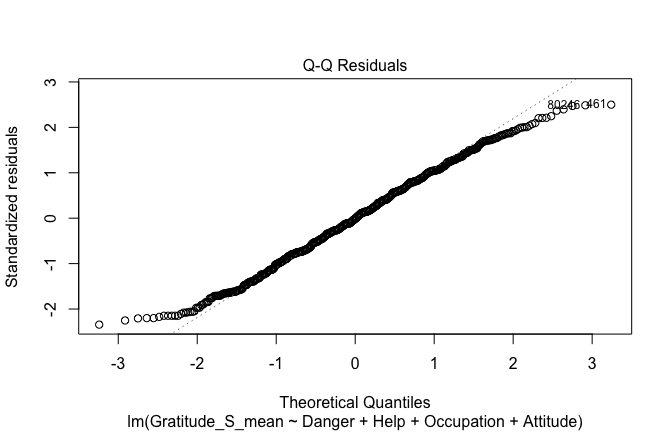
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Gratitude_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Gratitude_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)## Warning in lmrob.S(x, y, control = control): find_scale() did not converge in
## 'maxit.scale' (= 200) iterations with tol=1e-10, last rel.diff=0## Warning in lmrob.S(x, y, control = control): find_scale() did not converge in
## 'maxit.scale' (= 200) iterations with tol=1e-10, last rel.diff=0## Warning in lmrob.fit(x, y, control, init = init): M-step did NOT converge.
## Returning unconverged SM-estimate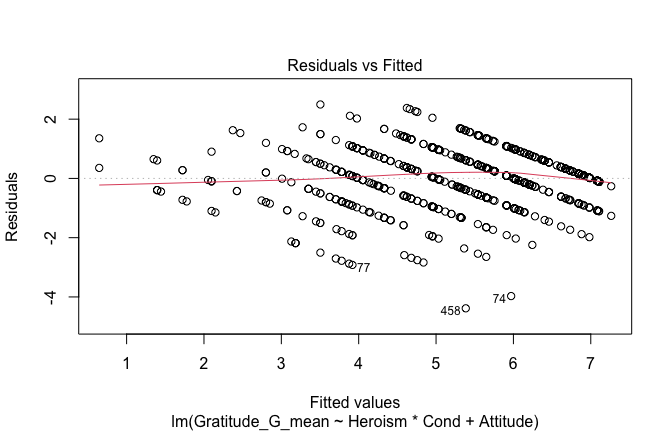
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.391 | 4.892 |
| (0.150) | ||
| 29.367 | ||
| p = <0.001 | ||
| Heroism | 0.239 | 0.165 |
| (0.030) | ||
| 8.105 | ||
| p = <0.001 | ||
| Cond1 | 1.163 | 0.786 |
| (0.338) | ||
| 3.435 | ||
| p = <0.001 | ||
| Cond2 | 0.015 | −0.470 |
| (0.195) | ||
| 0.079 | ||
| p = 0.937 | ||
| Cond3 | 0.104 | 0.142 |
| (0.251) | ||
| 0.413 | ||
| p = 0.680 | ||
| Cond4 | −0.295 | 0.360 |
| (0.226) | ||
| −1.306 | ||
| p = 0.192 | ||
| Cond5 | −0.832 | −0.680 |
| (0.229) | ||
| −3.626 | ||
| p = <0.001 | ||
| Attitude | 0.908 | 0.963 |
| (0.050) | ||
| 18.063 | ||
| p = <0.001 | ||
| Heroism × Cond1 | −0.168 | −0.116 |
| (0.057) | ||
| −2.972 | ||
| p = 0.003 | ||
| Heroism × Cond2 | 0.036 | 0.111 |
| (0.046) | ||
| 0.780 | ||
| p = 0.435 | ||
| Heroism × Cond3 | −0.002 | −0.022 |
| (0.044) | ||
| −0.056 | ||
| p = 0.955 | ||
| Heroism × Cond4 | 0.025 | −0.083 |
| (0.047) | ||
| 0.545 | ||
| p = 0.586 | ||
| Heroism × Cond5 | 0.134 | 0.113 |
| (0.043) | ||
| 3.138 | ||
| p = 0.002 | ||
| Num.Obs. | 840 | 840 |
| R2 | 0.690 | 0.849 |
| R2 Adj. | 0.685 | 0.846 |
| RMSE | 0.87 | 0.90 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: Gratitude_G_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 833)
## = 653.30, p < .001; Eta2 (partial) = 0.44, 95% CI [0.40, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 833) =
## 8.16, p < .001; Eta2 (partial) = 0.05, 95% CI [0.02, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: Gratitude_G_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 828)
## = 579.85, p < .001; Eta2 (partial) = 0.41, 95% CI [0.37, 1.00])
## - The main effect of Cond is statistically significant and medium (F(5, 828) =
## 11.07, p < .001; Eta2 (partial) = 0.06, 95% CI [0.03, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 828) = 8.31, p < .001; Eta2 (partial) = 0.05, 95% CI [0.02, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: Gratitude_G_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(Gratitude_G_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 832)
## = 68.04, p < .001; Eta2 (partial) = 0.08, 95% CI [0.05, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 832) =
## 6.24, p < .001; Eta2 (partial) = 0.04, 95% CI [0.01, 1.00])
## - The main effect of scale(Attitude) is statistically significant and large
## (F(1, 832) = 363.78, p < .001; Eta2 (partial) = 0.30, 95% CI [0.26, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: Gratitude_G_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(Gratitude_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 827)
## = 65.69, p < .001; Eta2 (partial) = 0.07, 95% CI [0.05, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 827) =
## 4.21, p < .001; Eta2 (partial) = 0.02, 95% CI [6.49e-03, 1.00])
## - The main effect of scale(Attitude) is statistically significant and large
## (F(1, 827) = 326.28, p < .001; Eta2 (partial) = 0.28, 95% CI [0.24, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 827) = 3.14, p = 0.008; Eta2 (partial) = 0.02, 95% CI [2.75e-03,
## 1.00])
##
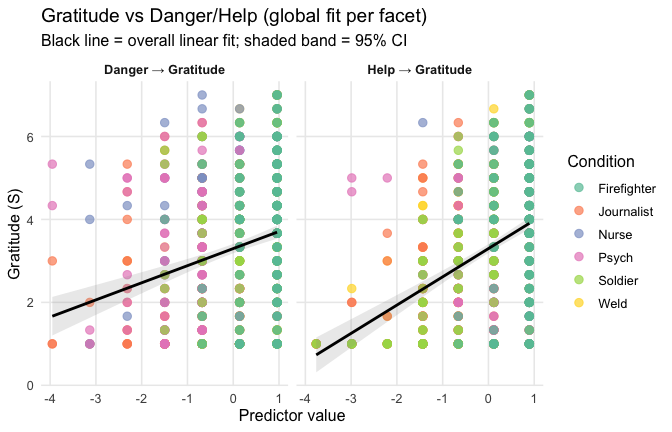
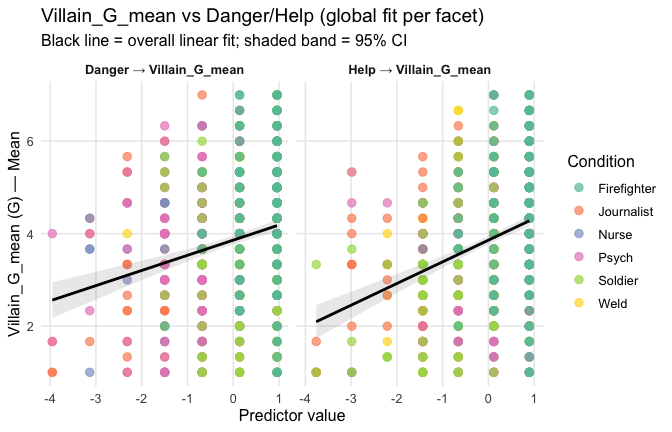
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = Gratitude_G_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Gratitude (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Gratitude (G), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'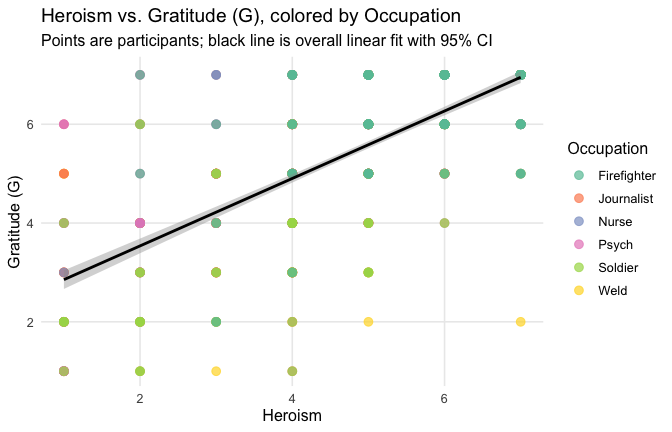
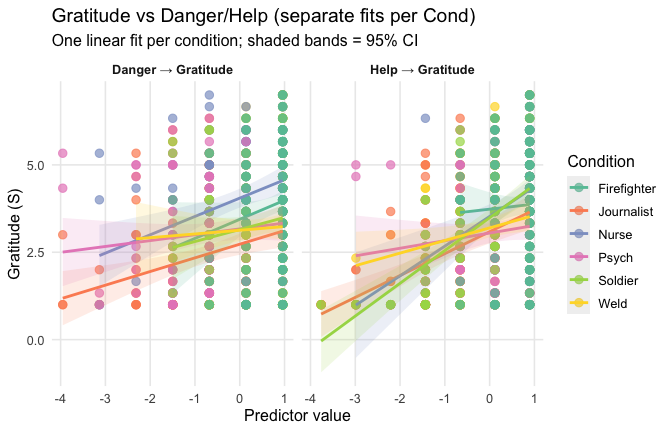
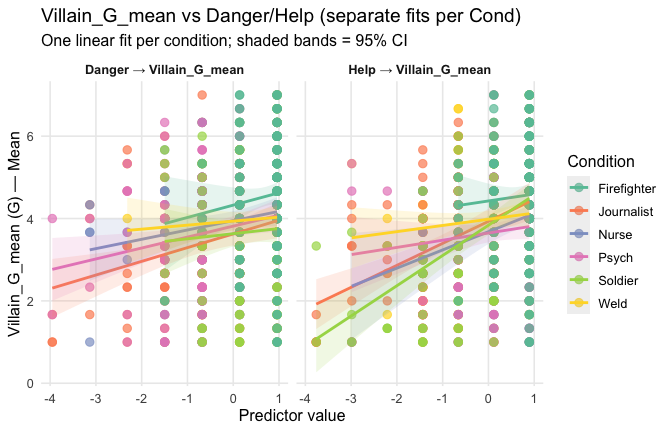
ggplot(scale_scores, aes(y = Gratitude_G_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Gratitude (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Gratitude (G) with per-occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'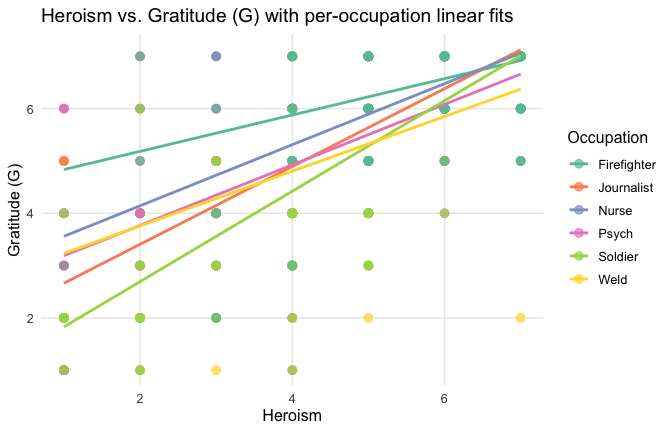
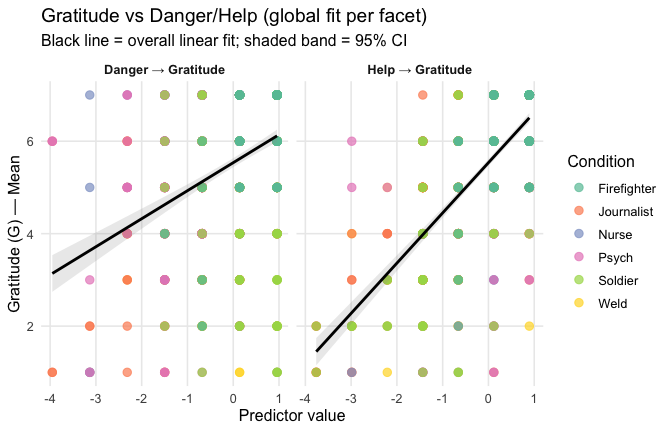
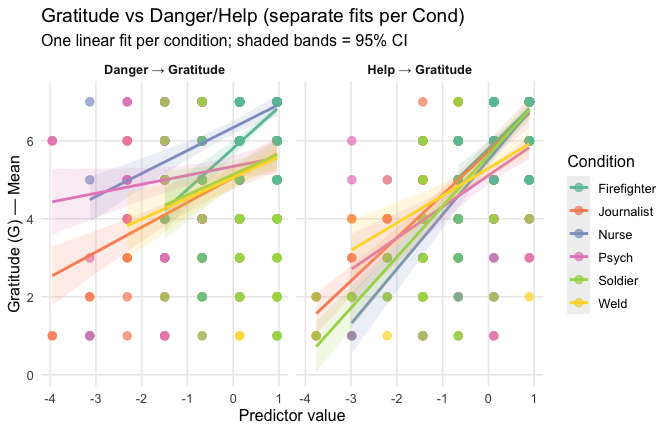
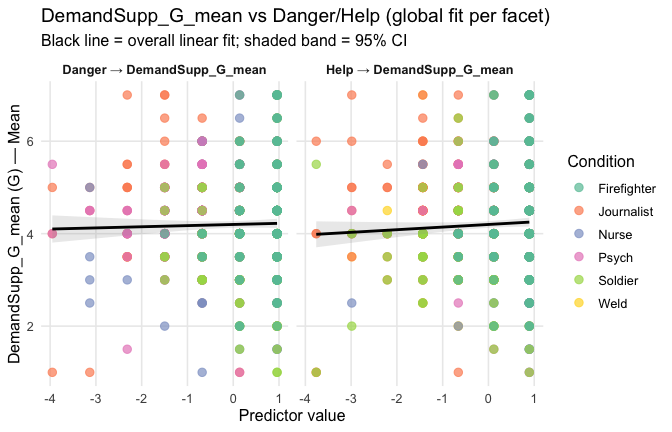
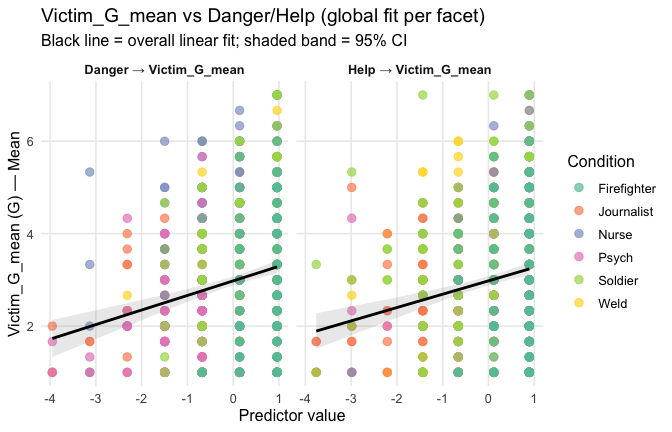
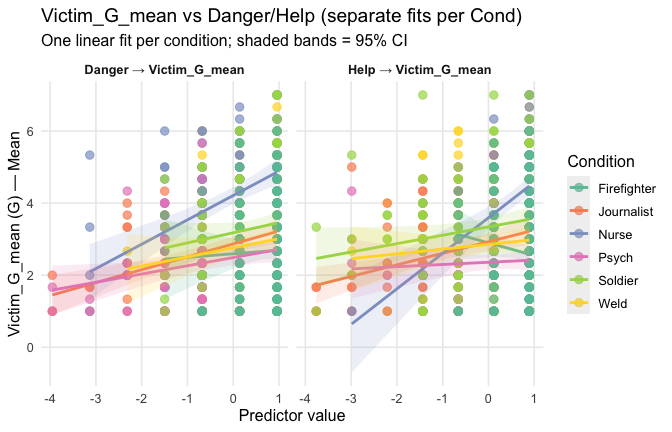
Overall: Heroism predict general gratitude. This is true above and beyond attitude (see Model 3). It is true when controlling for normative effects of occupations (Model 2), and when controlling for both occupations and attitude (Model 4). See Summary tables:
Model 1: “~Heroism + Occupation”
# Make sure Cond is a factor
scale_scores <- scale_scores %>% mutate(Cond = as.factor(Cond))
scale_scores$Occupation <- scale_scores$Cond
scale_scores$Occupation <- as.factor(scale_scores$Occupation)
contrasts(scale_scores$Occupation) <- contr.sum(nlevels(scale_scores$Occupation))
# Partial eta^2 from F and dfs (works for any df1)
eta_p2_fromF <- function(Fval, df1, df2) (Fval * df1) / (Fval * df1 + df2)
tidy_type3 <- function(mod, caption) {
a <- car::Anova(mod, type = "III")
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
names(tab) <- sub(" ", "_", names(tab)) # "Sum Sq" -> "Sum_Sq", etc.
resid_df2 <- tab$Df[tab$Term == "Residuals"]
out <- tab %>%
dplyr::filter(!(Term %in% c("(Intercept)","Residuals"))) %>%
dplyr::transmute(
Term,
df1 = Df,
df2 = resid_df2,
F = round(F_value, 2),
p = ifelse(`Pr(>F)` < .001, "< .001", sprintf("= %.3f", `Pr(>F)`)),
eta2p = round((F_value * Df) / (F_value * Df + resid_df2), 3)
)
kbl <- knitr::kable(out, format = "html", align = "lrrrcr", caption = caption)
# If kableExtra is installed, add a vertical separator + padding between p and eta2p
if ("column_spec" %in% getNamespaceExports("kableExtra")) {
kbl <- kbl %>%
kableExtra::kable_styling(full_width = FALSE, bootstrap_options = c("striped","hover")) %>%
# p is column 5 → add a right border and a bit of right padding
kableExtra::column_spec(5, border_right = "1px solid #ddd",
extra_css = "padding-right: 10px;") %>%
# eta2p is column 6 → add left padding so it breathes
kableExtra::column_spec(6, extra_css = "padding-left: 10px;")
}
kbl
}
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(Gratitude_G_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(Gratitude_G_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(Gratitude_G_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(Gratitude_G_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 653.30 | < .001 | 0.440 |
| Occupation | Occupation | 5 | 833 | 8.16 | < .001 | 0.047 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 579.85 | < .001 | 0.412 |
| Occupation | Occupation | 5 | 828 | 11.07 | < .001 | 0.063 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 8.31 | < .001 | 0.048 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 68.04 | < .001 | 0.076 |
| Occupation | Occupation | 5 | 832 | 6.24 | < .001 | 0.036 |
| Attitude | Attitude | 1 | 832 | 363.78 | < .001 | 0.304 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 65.69 | < .001 | 0.074 |
| Occupation | Occupation | 5 | 827 | 4.21 | < .001 | 0.025 |
| Attitude | Attitude | 1 | 827 | 326.28 | < .001 | 0.283 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 3.14 | = 0.008 | 0.019 |
Comparison of main effect sizes in each model
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "Gratitude_G_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(Gratitude_G_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(Gratitude_G_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(Gratitude_G_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(Gratitude_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | Gratitude_G_mean | Heroism | 1 | 833 | 653.30 | < .001 | 0.440 |
| ~ Heroism * Occupation | Gratitude_G_mean | Heroism | 1 | 828 | 579.85 | < .001 | 0.412 |
| ~ Heroism + Cond + Attitude | Gratitude_G_mean | Heroism | 1 | 832 | 68.04 | < .001 | 0.076 |
| ~ Heroism * Occupation + Attitude | Gratitude_G_mean | Heroism | 1 | 827 | 65.69 | < .001 | 0.074 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
Specific level
[If there were a public campaign in support of journalists, how likely would you be to do each of these things in response?] Sharing a supportive post about journalists on my social media
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
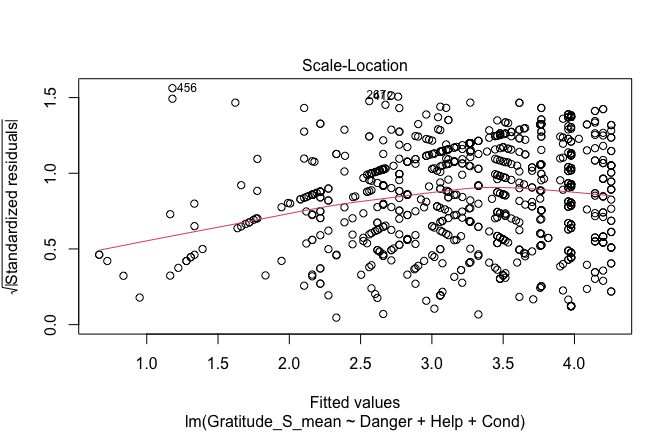
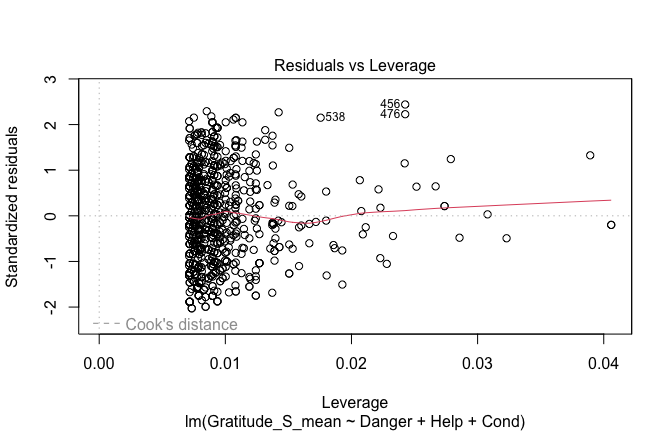
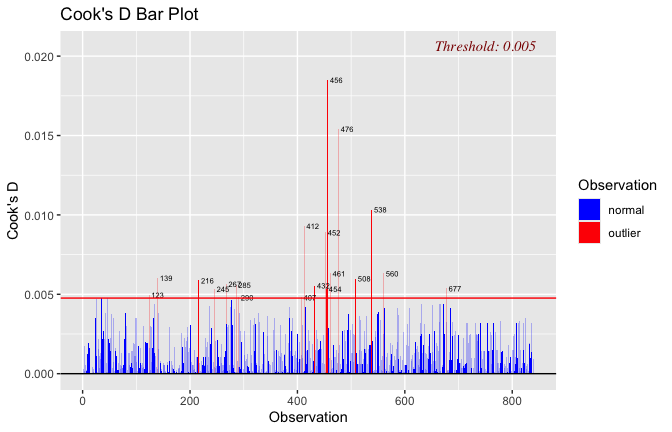
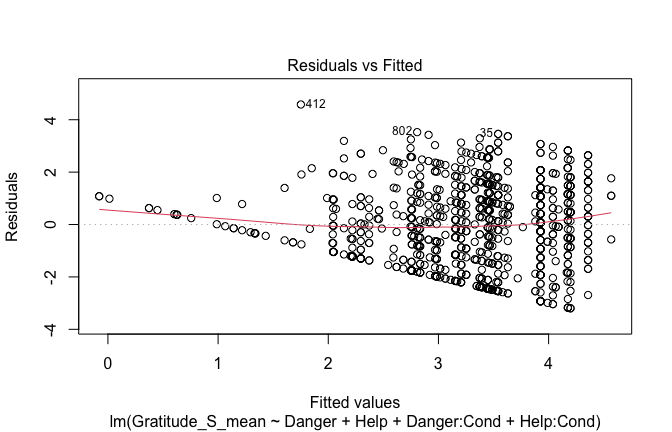
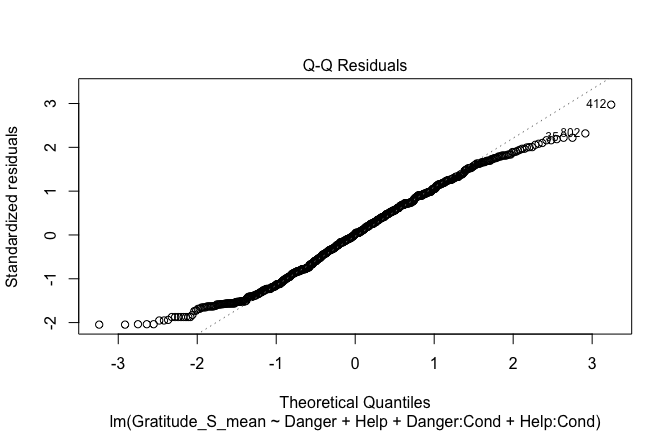
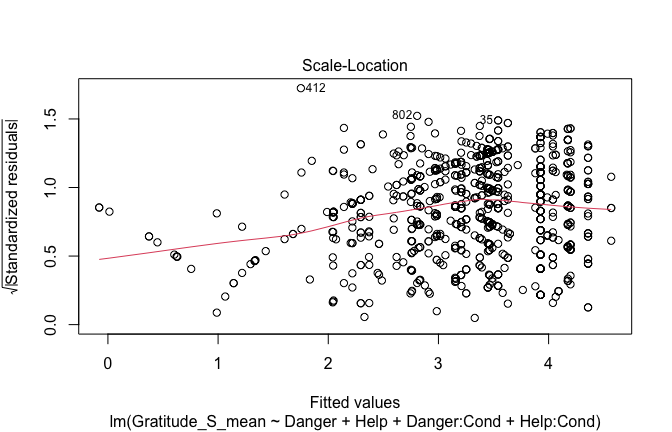
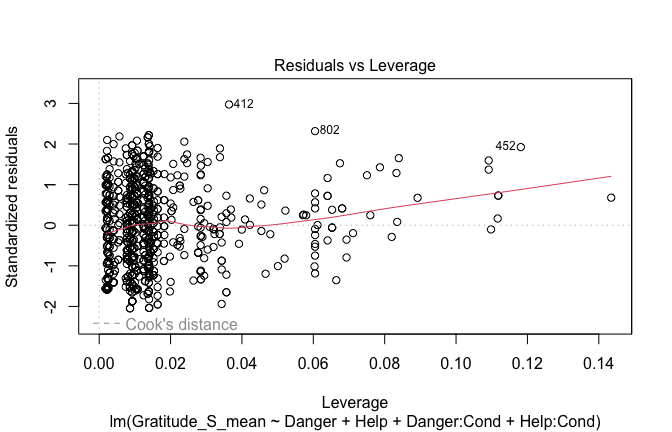
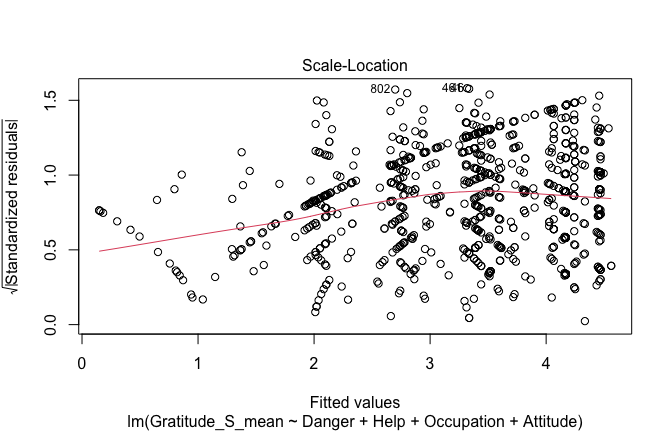
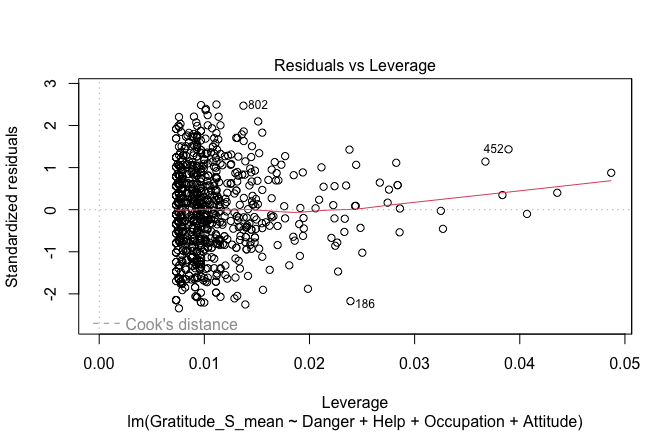
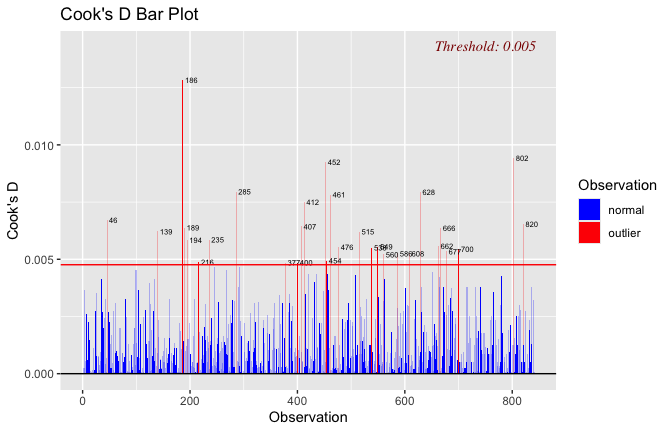
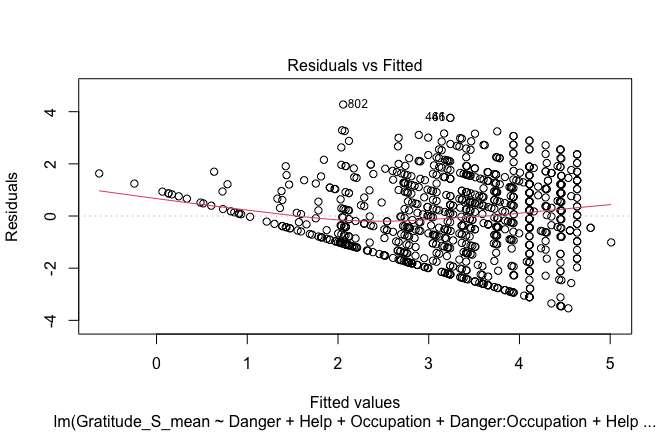
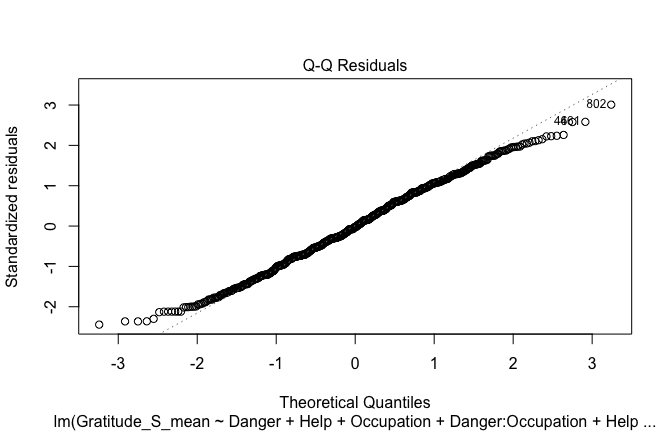
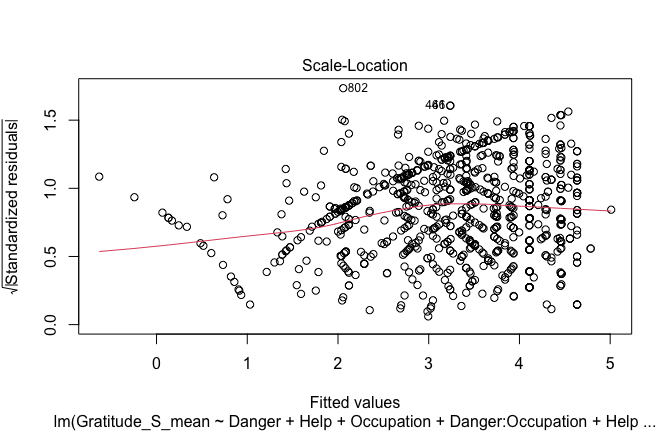
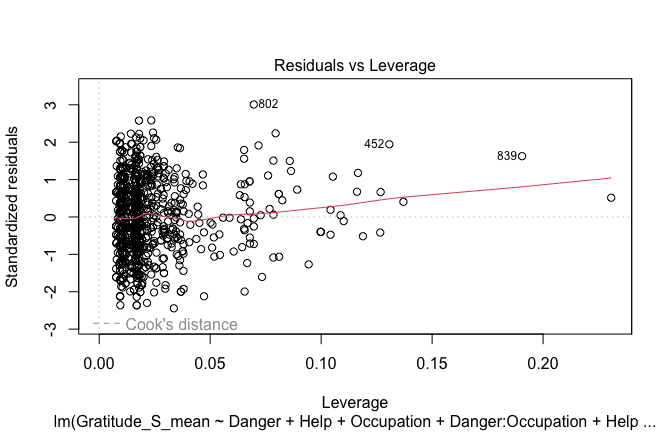
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(Gratitude_S_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(Gratitude_S_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)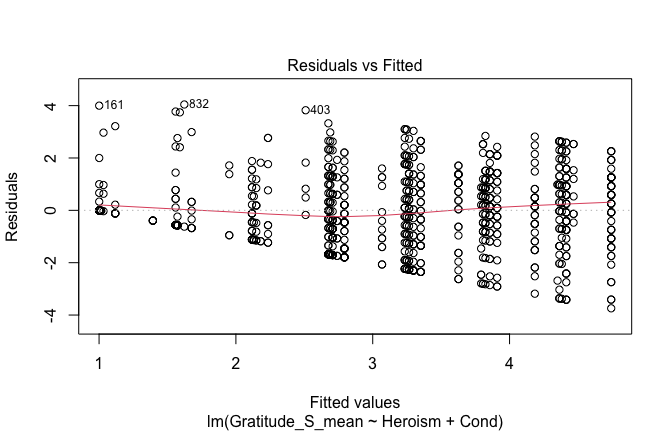
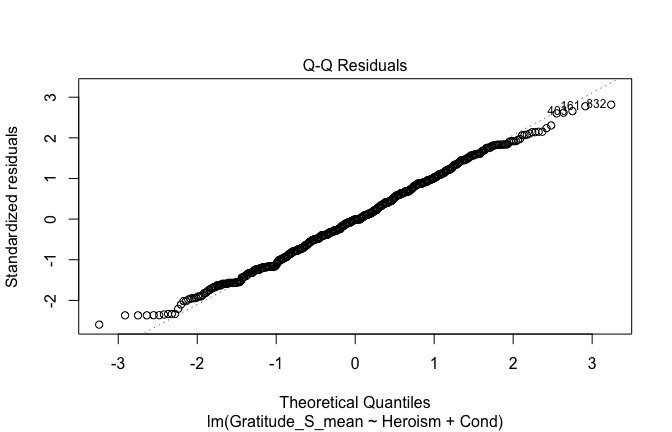
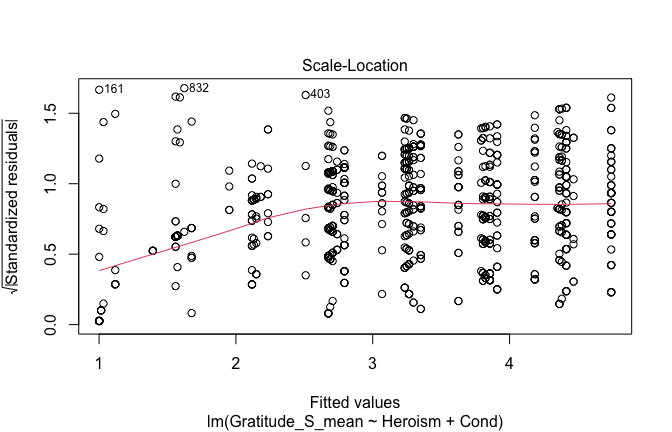
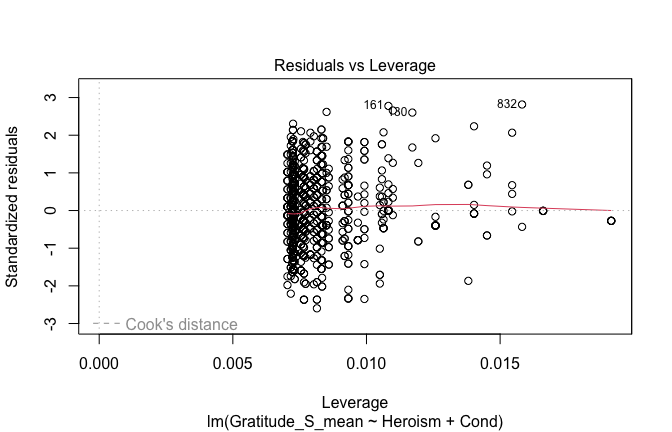
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 0.546 | 0.337 |
| (0.176) | (0.163) | |
| 3.096 | 2.069 | |
| p = 0.002 | p = 0.039 | |
| Heroism | 0.558 | 0.600 |
| (0.034) | (0.034) | |
| 16.262 | 17.539 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.039 | −0.054 |
| (0.116) | (0.127) | |
| −0.337 | −0.427 | |
| p = 0.736 | p = 0.670 | |
| Cond2 | −0.103 | −0.094 |
| (0.121) | (0.130) | |
| −0.850 | −0.722 | |
| p = 0.395 | p = 0.470 | |
| Cond3 | 0.289 | 0.314 |
| (0.114) | (0.118) | |
| 2.538 | 2.653 | |
| p = 0.011 | p = 0.008 | |
| Cond4 | 0.014 | 0.006 |
| (0.112) | (0.117) | |
| 0.126 | 0.049 | |
| p = 0.900 | p = 0.961 | |
| Cond5 | −0.089 | −0.094 |
| (0.112) | (0.120) | |
| −0.795 | −0.788 | |
| p = 0.427 | p = 0.431 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.307 | 0.332 |
| R2 Adj. | 0.302 | 0.328 |
| RMSE | 1.44 | 1.44 |
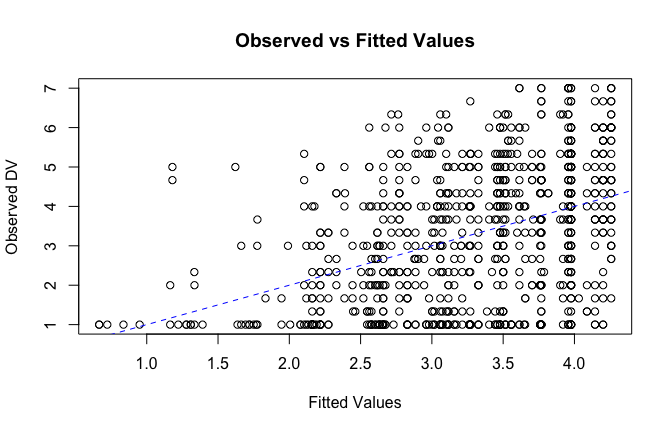
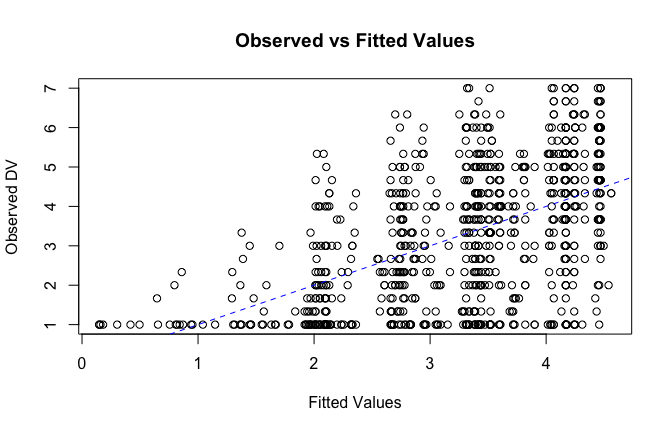
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)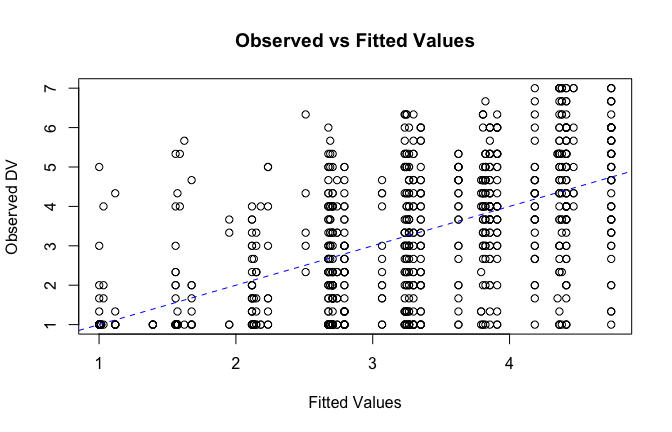
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(Gratitude_S_mean ~ Heroism * Cond, data = scale_scores)
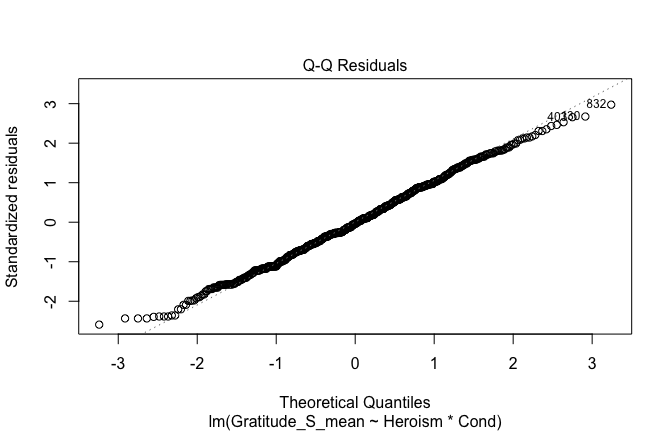
mod1r <- lmrob(Gratitude_S_mean ~ Heroism * Cond, data = scale_scores)
plot(mod1)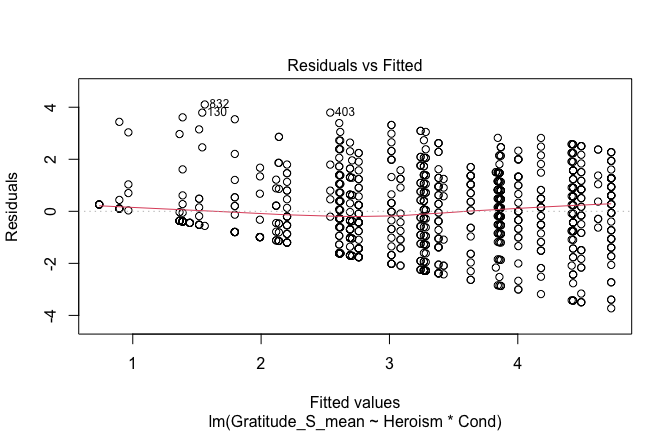
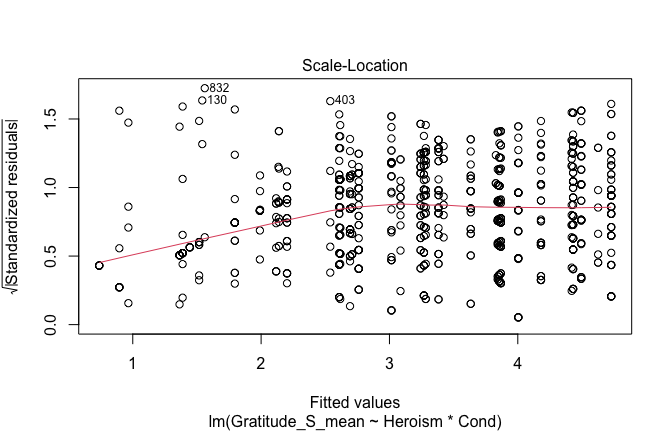
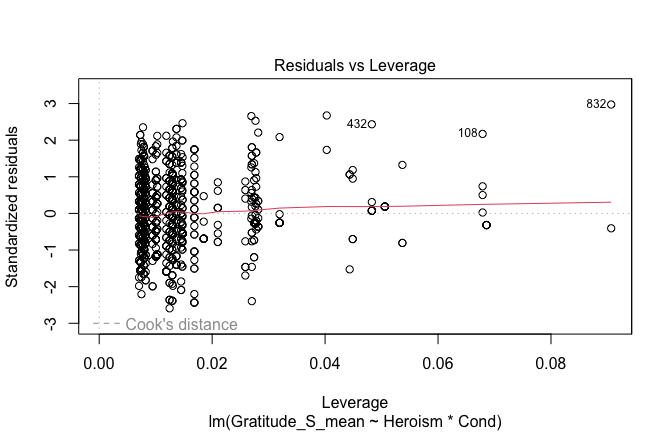
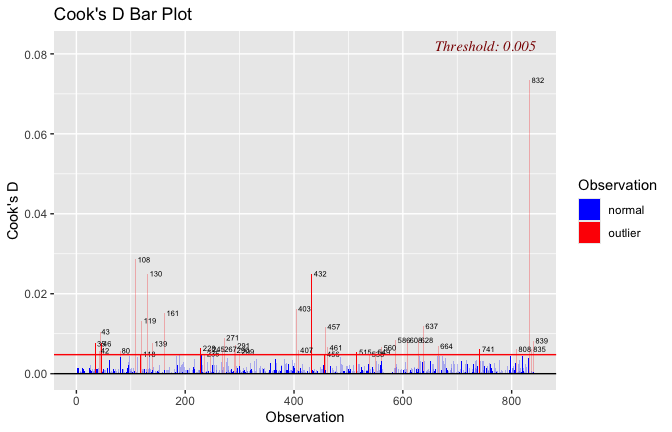
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 0.511 | 0.234 |
| (0.186) | (0.198) | |
| 2.748 | 1.181 | |
| p = 0.006 | p = 0.238 | |
| Heroism | 0.559 | 0.609 |
| (0.035) | (0.039) | |
| 15.802 | 15.807 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.098 | −0.461 |
| (0.556) | (0.662) | |
| −0.176 | −0.696 | |
| p = 0.860 | p = 0.486 | |
| Cond2 | 0.470 | 0.622 |
| (0.316) | (0.276) | |
| 1.487 | 2.253 | |
| p = 0.137 | p = 0.025 | |
| Cond3 | 0.386 | 0.488 |
| (0.414) | (0.354) | |
| 0.931 | 1.378 | |
| p = 0.352 | p = 0.168 | |
| Cond4 | −0.238 | −0.176 |
| (0.374) | (0.328) | |
| −0.637 | −0.536 | |
| p = 0.525 | p = 0.592 | |
| Cond5 | −0.399 | −0.317 |
| (0.372) | (0.304) | |
| −1.071 | −1.042 | |
| p = 0.284 | p = 0.298 | |
| Heroism × Cond1 | 0.015 | 0.076 |
| (0.093) | (0.110) | |
| 0.165 | 0.689 | |
| p = 0.869 | p = 0.491 | |
| Heroism × Cond2 | −0.152 | −0.192 |
| (0.075) | (0.078) | |
| −2.022 | −2.448 | |
| p = 0.043 | p = 0.015 | |
| Heroism × Cond3 | −0.011 | −0.022 |
| (0.072) | (0.065) | |
| −0.156 | −0.335 | |
| p = 0.876 | p = 0.738 | |
| Heroism × Cond4 | 0.063 | 0.054 |
| (0.077) | (0.071) | |
| 0.821 | 0.754 | |
| p = 0.412 | p = 0.451 | |
| Heroism × Cond5 | 0.067 | 0.057 |
| (0.070) | (0.065) | |
| 0.964 | 0.878 | |
| p = 0.335 | p = 0.380 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.312 | 0.345 |
| R2 Adj. | 0.302 | 0.336 |
| RMSE | 1.44 | 1.44 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)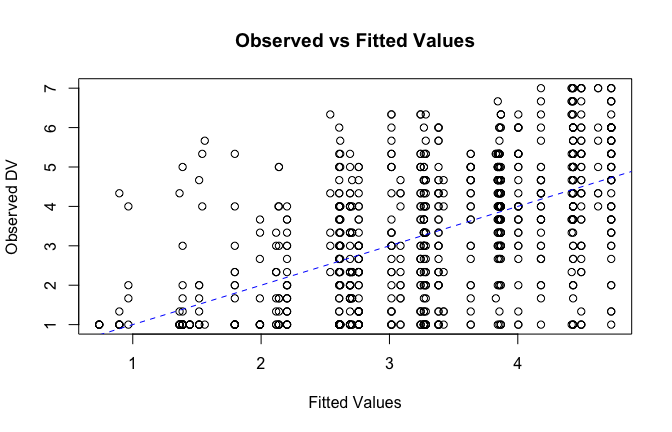
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Gratitude_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Gratitude_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)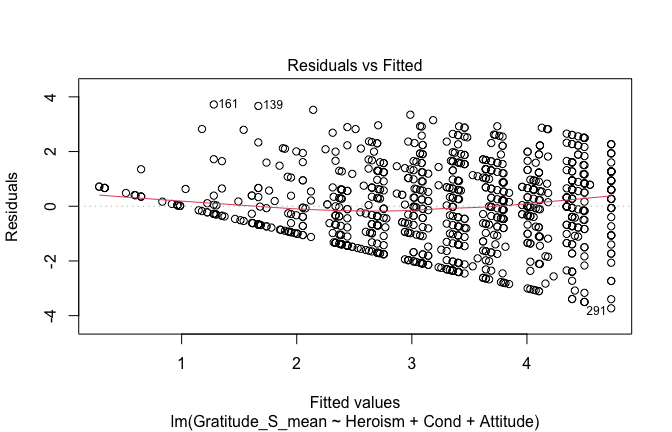
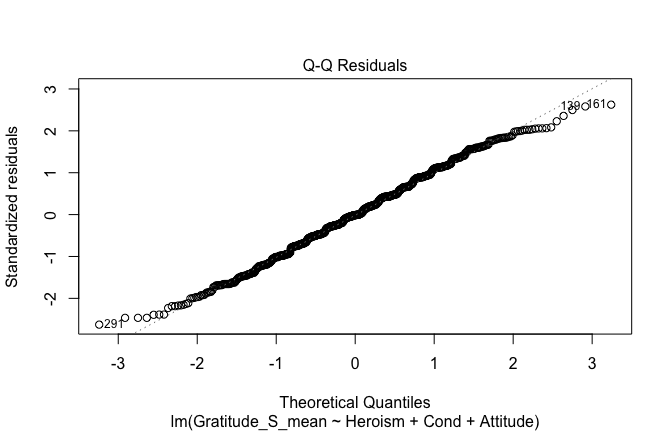
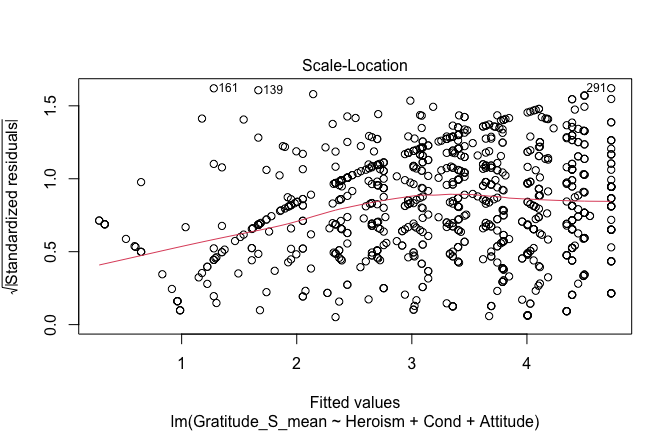
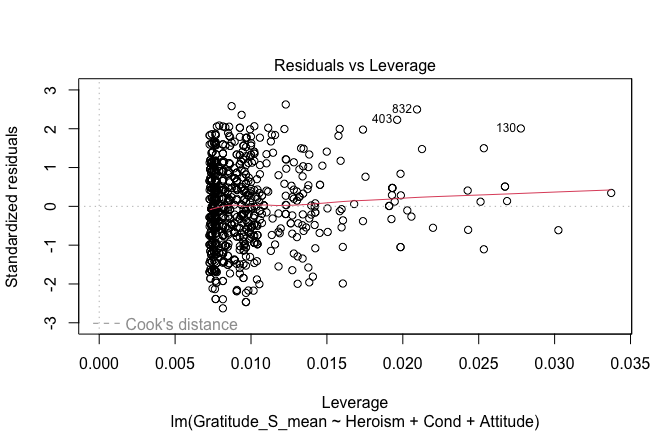
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 1.391 | 1.220 |
| (0.240) | (0.278) | |
| 5.790 | 4.393 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.387 | 0.423 |
| (0.048) | (0.056) | |
| 8.104 | 7.590 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.126 | −0.137 |
| (0.116) | (0.131) | |
| −1.082 | −1.051 | |
| p = 0.279 | p = 0.293 | |
| Cond2 | 0.030 | 0.031 |
| (0.122) | (0.129) | |
| 0.242 | 0.239 | |
| p = 0.809 | p = 0.811 | |
| Cond3 | 0.214 | 0.242 |
| (0.113) | (0.119) | |
| 1.891 | 2.030 | |
| p = 0.059 | p = 0.043 | |
| Cond4 | −0.027 | −0.042 |
| (0.111) | (0.117) | |
| −0.242 | −0.359 | |
| p = 0.809 | p = 0.720 | |
| Cond5 | −0.018 | −0.012 |
| (0.112) | (0.120) | |
| −0.164 | −0.096 | |
| p = 0.869 | p = 0.923 | |
| Attitude | 0.408 | 0.396 |
| (0.080) | (0.087) | |
| 5.094 | 4.553 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.328 | 0.345 |
| R2 Adj. | 0.323 | 0.340 |
| RMSE | 1.42 | 1.42 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)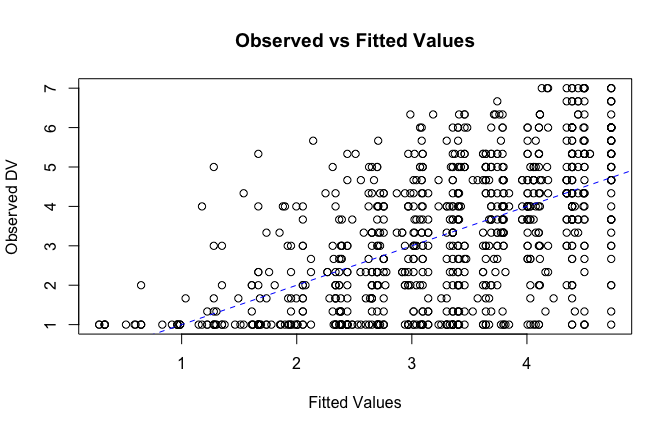
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Gratitude_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
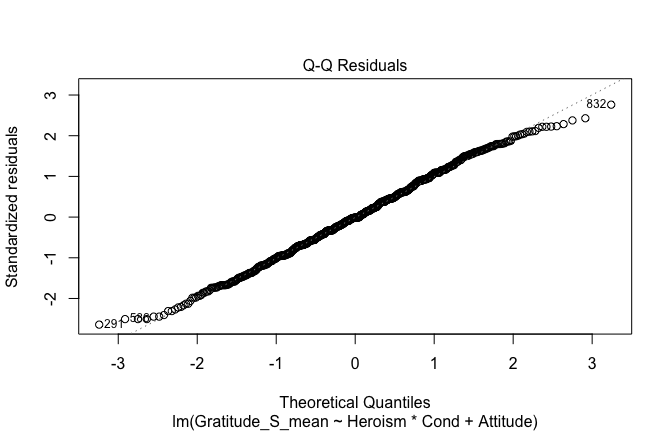
mod1r <- lmrob(Gratitude_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)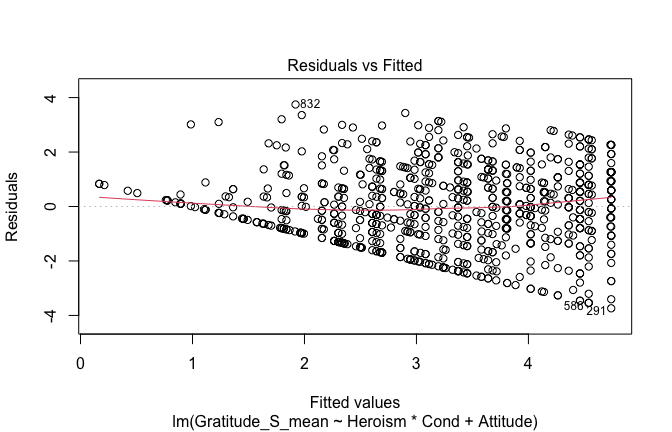
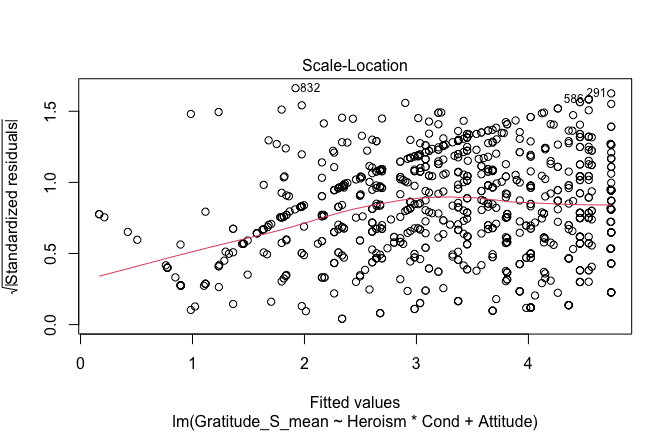
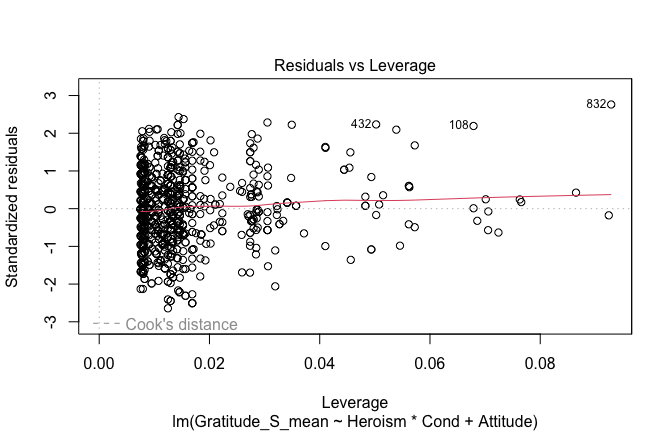
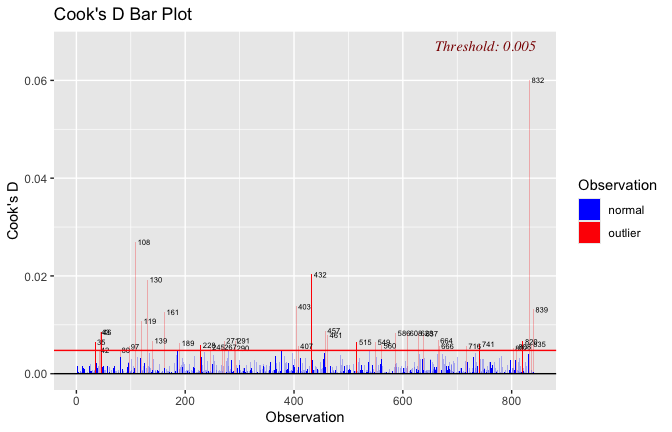
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 1.372 | 1.145 |
| (0.243) | (0.296) | |
| 5.637 | 3.873 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.381 | 0.425 |
| (0.048) | (0.058) | |
| 7.926 | 7.366 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.443 | −0.761 |
| (0.551) | (0.668) | |
| −0.805 | −1.139 | |
| p = 0.421 | p = 0.255 | |
| Cond2 | 0.813 | 0.893 |
| (0.318) | (0.274) | |
| 2.559 | 3.261 | |
| p = 0.011 | p = 0.001 | |
| Cond3 | 0.260 | 0.374 |
| (0.408) | (0.369) | |
| 0.636 | 1.013 | |
| p = 0.525 | p = 0.311 | |
| Cond4 | −0.380 | −0.332 |
| (0.368) | (0.331) | |
| −1.032 | −1.002 | |
| p = 0.302 | p = 0.317 | |
| Cond5 | −0.005 | 0.037 |
| (0.373) | (0.315) | |
| −0.012 | 0.116 | |
| p = 0.990 | p = 0.908 | |
| Attitude | 0.439 | 0.423 |
| (0.082) | (0.087) | |
| 5.365 | 4.854 | |
| p = <0.001 | p = <0.001 | |
| Heroism × Cond1 | 0.059 | 0.112 |
| (0.092) | (0.110) | |
| 0.643 | 1.014 | |
| p = 0.521 | p = 0.311 | |
| Heroism × Cond2 | −0.201 | −0.226 |
| (0.074) | (0.076) | |
| −2.699 | −2.957 | |
| p = 0.007 | p = 0.003 | |
| Heroism × Cond3 | −0.001 | −0.014 |
| (0.071) | (0.066) | |
| −0.018 | −0.208 | |
| p = 0.985 | p = 0.835 | |
| Heroism × Cond4 | 0.089 | 0.081 |
| (0.076) | (0.072) | |
| 1.175 | 1.130 | |
| p = 0.240 | p = 0.259 | |
| Heroism × Cond5 | 0.008 | 0.005 |
| (0.070) | (0.066) | |
| 0.112 | 0.081 | |
| p = 0.911 | p = 0.935 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.335 | 0.358 |
| R2 Adj. | 0.325 | 0.348 |
| RMSE | 1.41 | 1.41 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Gratitude_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)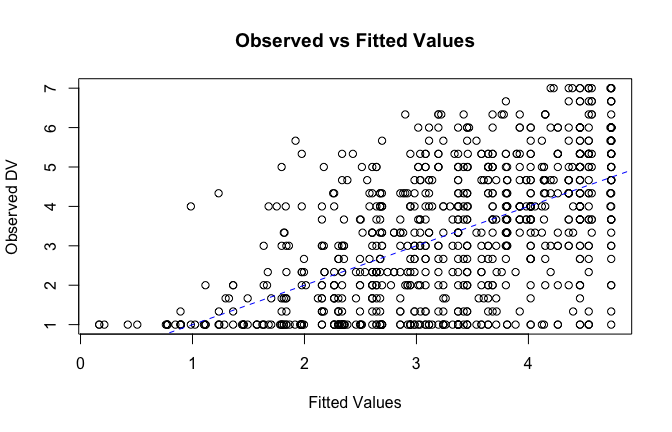
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: Gratitude_S_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 833)
## = 264.46, p < .001; Eta2 (partial) = 0.24, 95% CI [0.20, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 833) = 1.39, p = 0.224; Eta2 (partial) = 8.30e-03, 95% CI [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: Gratitude_S_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 828)
## = 249.71, p < .001; Eta2 (partial) = 0.23, 95% CI [0.19, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 828) = 0.87, p = 0.500; Eta2 (partial) = 5.23e-03, 95% CI [0.00, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 828) = 1.00, p = 0.419; Eta2 (partial) = 5.98e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: Gratitude_S_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(Gratitude_S_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 832)
## = 65.67, p < .001; Eta2 (partial) = 0.07, 95% CI [0.05, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 832) = 0.95, p = 0.445; Eta2 (partial) = 5.70e-03, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 832) = 25.95, p < .001; Eta2 (partial) = 0.03, 95% CI [0.01, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: Gratitude_S_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(Gratitude_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 827)
## = 62.81, p < .001; Eta2 (partial) = 0.07, 95% CI [0.05, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 827) = 1.60, p = 0.158; Eta2 (partial) = 9.56e-03, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 827) = 28.78, p < .001; Eta2 (partial) = 0.03, 95% CI [0.02, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 827) = 1.58, p = 0.163; Eta2 (partial) = 9.46e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = Gratitude_S_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Gratitude (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Gratitude (S), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'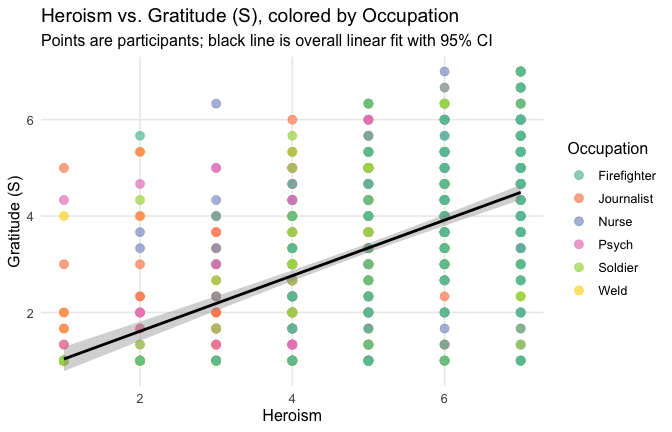
ggplot(scale_scores, aes(y = Gratitude_S_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Gratitude (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Gratitude (S) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'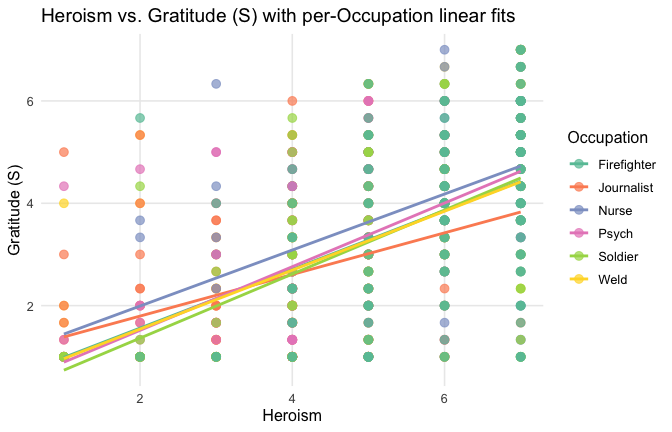
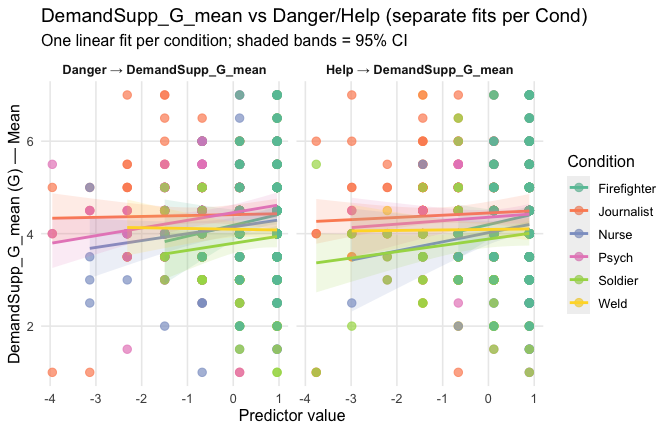
Overall: Heroism predict specific gratitude. This is true above and beyond attitude (see Model 3). It is true when controlling for normative effects of occupations (Model 2), and when controlling for both occupations and attitude (Model 4). See Summary table:
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(Gratitude_S_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(Gratitude_S_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(Gratitude_S_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(Gratitude_S_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 264.46 | < .001 | 0.241 |
| Occupation | Occupation | 5 | 833 | 1.39 | = 0.224 | 0.008 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 249.71 | < .001 | 0.232 |
| Occupation | Occupation | 5 | 828 | 0.87 | = 0.500 | 0.005 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 1.00 | = 0.419 | 0.006 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 65.67 | < .001 | 0.073 |
| Occupation | Occupation | 5 | 832 | 0.95 | = 0.445 | 0.006 |
| Attitude | Attitude | 1 | 832 | 25.95 | < .001 | 0.030 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 62.81 | < .001 | 0.071 |
| Occupation | Occupation | 5 | 827 | 1.60 | = 0.158 | 0.010 |
| Attitude | Attitude | 1 | 827 | 28.78 | < .001 | 0.034 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 1.58 | = 0.163 | 0.009 |
==> Full support for our hypotheses. Across all occupations Heroism predict general- and specific-level gratitude, with or without controlling for attitude.
Comparison of main effects across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "Gratitude_S_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(Gratitude_S_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(Gratitude_S_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(Gratitude_S_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(Gratitude_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | Gratitude_S_mean | Heroism | 1 | 833 | 264.46 | < .001 | 0.241 |
| ~ Heroism * Occupation | Gratitude_S_mean | Heroism | 1 | 828 | 249.71 | < .001 | 0.232 |
| ~ Heroism + Cond + Attitude | Gratitude_S_mean | Heroism | 1 | 832 | 65.67 | < .001 | 0.073 |
| ~ Heroism * Occupation + Attitude | Gratitude_S_mean | Heroism | 1 | 827 | 62.81 | < .001 | 0.071 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
H2: Heroism is associated with reduced criticism acceptability
Criticism of those granted moral goodness through the ‘hero’ status might be seen as a violation of sacred values (Tetlock, 2003). As such, people should report that people should not criticise the heroised workers at the general level. At the specific level, they should be more likely to approve for prosecutions and bans imposed to people who openly criticised the target workers.
General level
People should think twice before they criticize journalists
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
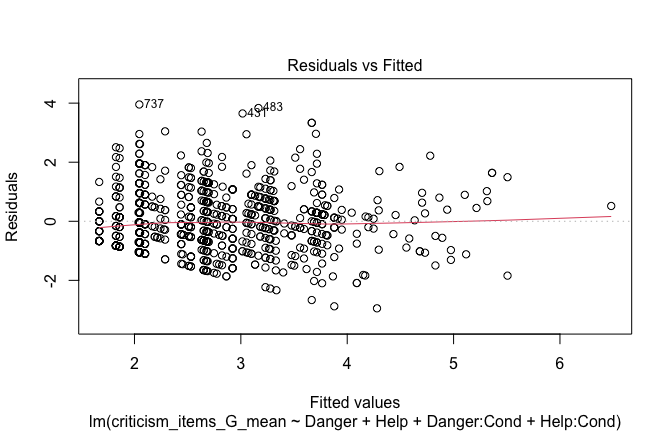
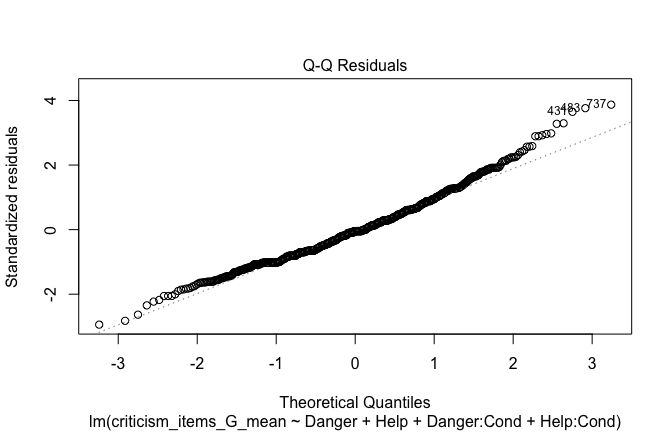
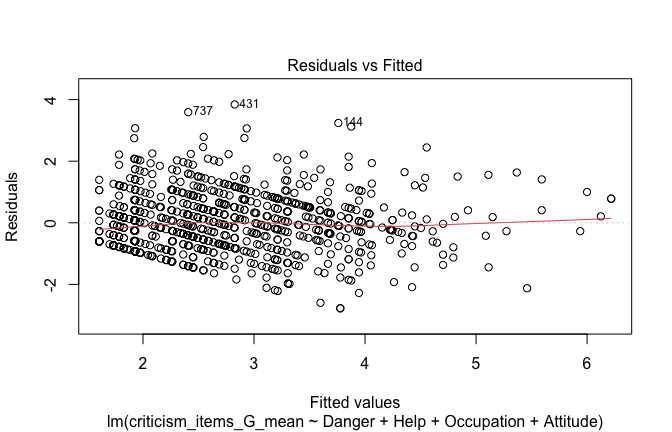
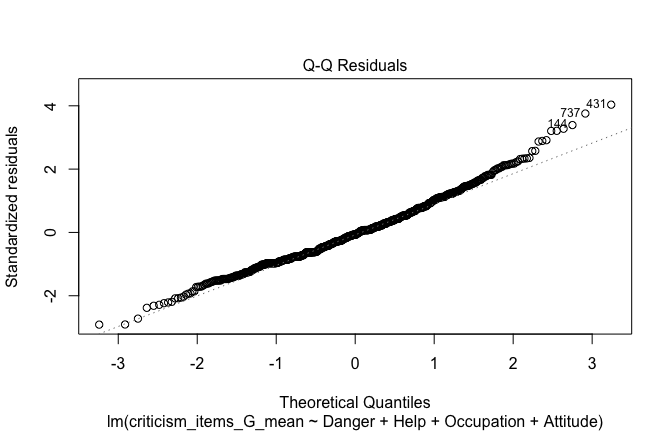
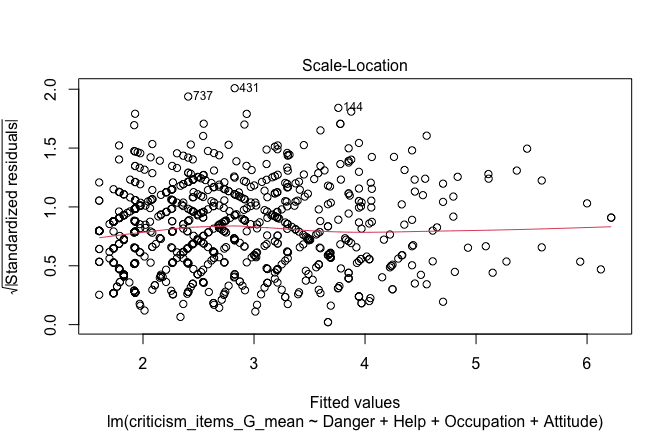
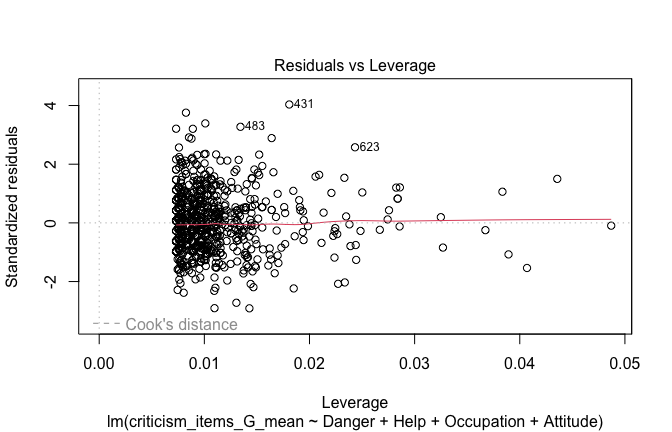
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(criticism_items_G_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(criticism_items_G_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
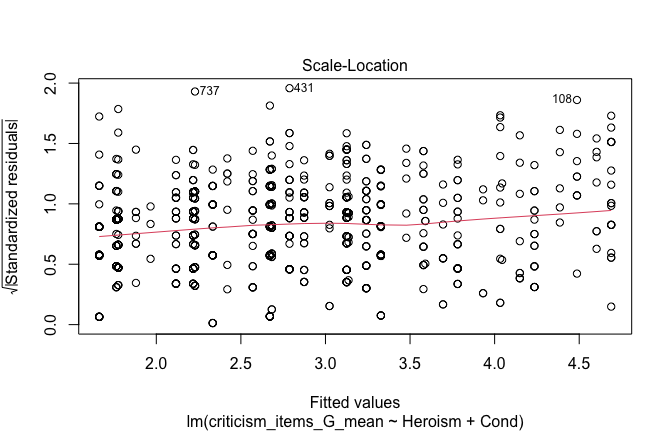
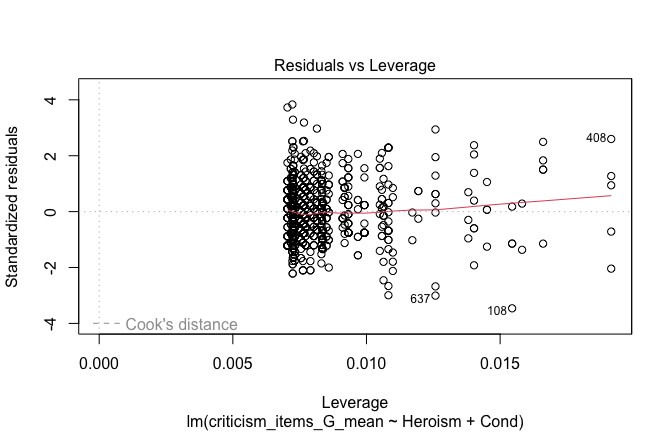
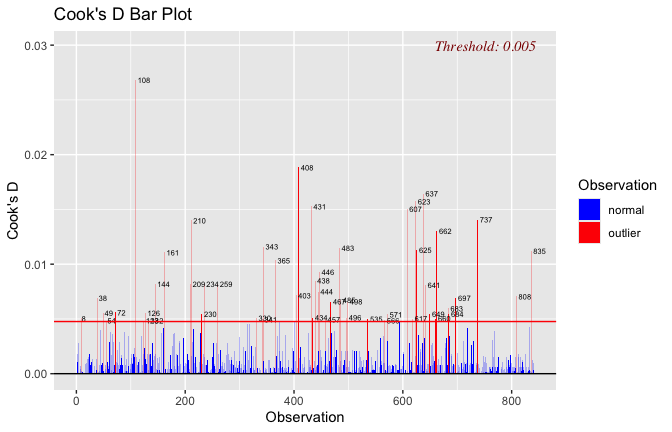
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.979 | 5.045 |
| (0.124) | (0.172) | |
| 40.247 | 29.258 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.454 | −0.473 |
| (0.024) | (0.032) | |
| −18.840 | −14.819 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.027 | −0.039 |
| (0.082) | (0.072) | |
| −0.328 | −0.542 | |
| p = 0.743 | p = 0.588 | |
| Cond2 | 0.164 | 0.171 |
| (0.085) | (0.094) | |
| 1.932 | 1.823 | |
| p = 0.054 | p = 0.069 | |
| Cond3 | −0.139 | −0.136 |
| (0.080) | (0.079) | |
| −1.742 | −1.734 | |
| p = 0.082 | p = 0.083 | |
| Cond4 | 0.078 | 0.072 |
| (0.079) | (0.082) | |
| 0.989 | 0.873 | |
| p = 0.323 | p = 0.383 | |
| Cond5 | −0.038 | −0.042 |
| (0.079) | (0.085) | |
| −0.482 | −0.489 | |
| p = 0.630 | p = 0.625 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.381 | 0.411 |
| R2 Adj. | 0.376 | 0.407 |
| RMSE | 1.01 | 1.01 |
fitted_vals <- fitted(mod1)
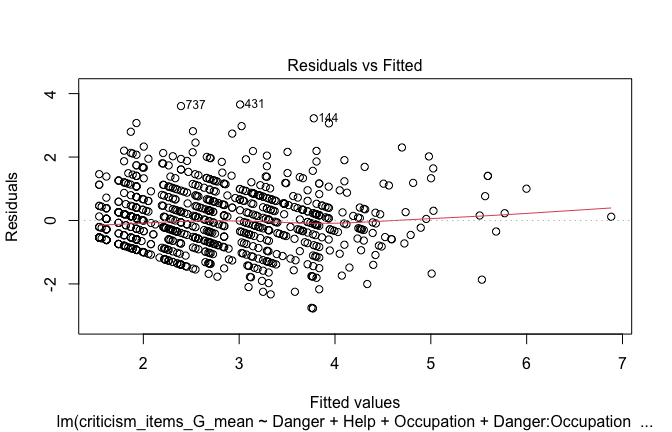
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)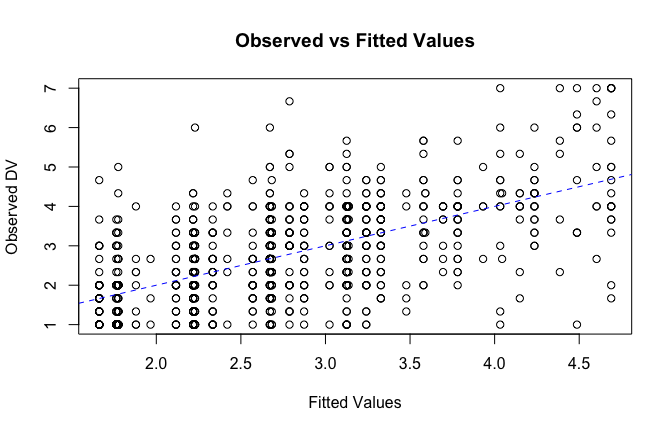
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(criticism_items_G_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(criticism_items_G_mean ~ Heroism * Cond, data = scale_scores)
plot(mod1)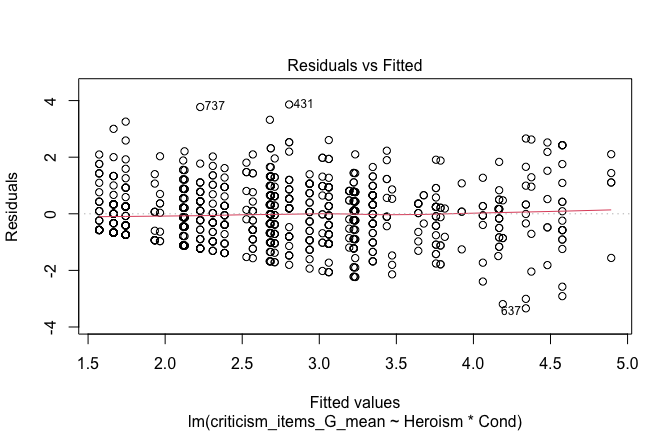
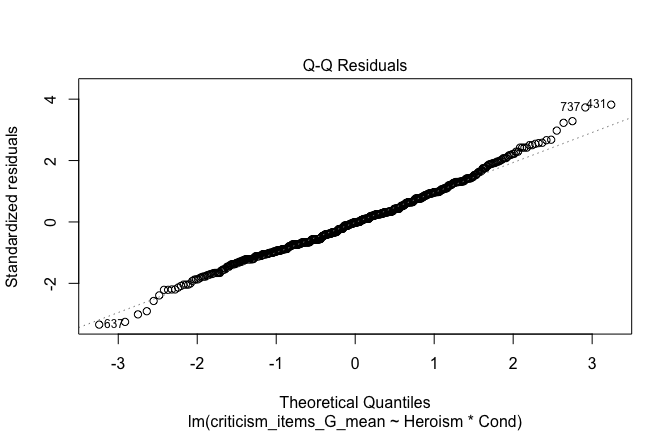
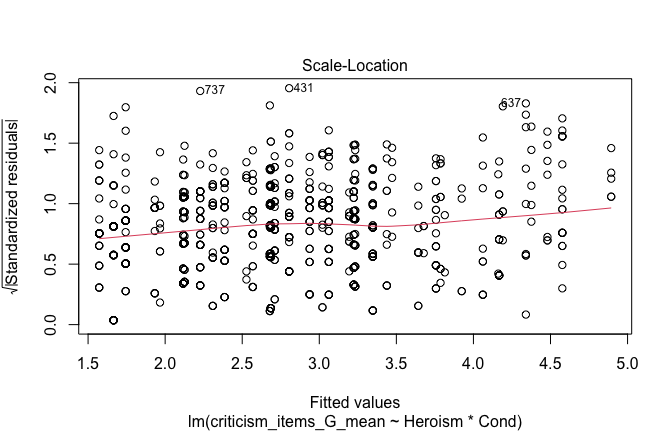
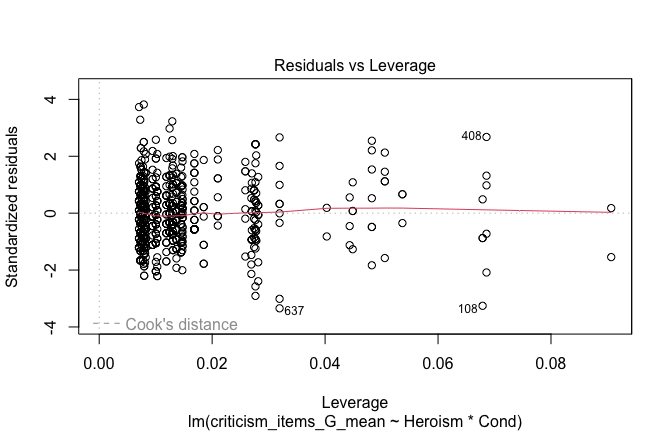
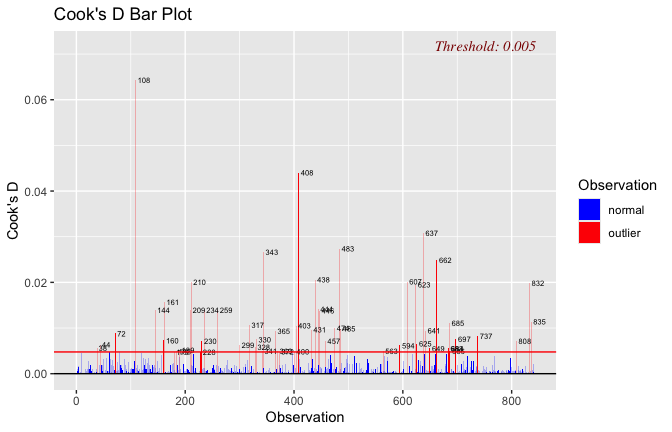
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.976 | 5.087 |
| (0.130) | (0.163) | |
| 38.136 | 31.248 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.449 | −0.474 |
| (0.025) | (0.030) | |
| −18.115 | −15.937 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.152 | 0.244 |
| (0.390) | (0.359) | |
| 0.390 | 0.680 | |
| p = 0.696 | p = 0.497 | |
| Cond2 | 0.011 | −0.200 |
| (0.222) | (0.289) | |
| 0.048 | −0.690 | |
| p = 0.962 | p = 0.490 | |
| Cond3 | −0.148 | −0.245 |
| (0.290) | (0.449) | |
| −0.511 | −0.546 | |
| p = 0.610 | p = 0.585 | |
| Cond4 | −0.077 | −0.177 |
| (0.262) | (0.328) | |
| −0.294 | −0.540 | |
| p = 0.769 | p = 0.589 | |
| Cond5 | 0.471 | 0.691 |
| (0.261) | (0.387) | |
| 1.806 | 1.785 | |
| p = 0.071 | p = 0.075 | |
| Heroism × Cond1 | −0.034 | −0.054 |
| (0.066) | (0.059) | |
| −0.526 | −0.917 | |
| p = 0.599 | p = 0.359 | |
| Heroism × Cond2 | 0.039 | 0.090 |
| (0.053) | (0.068) | |
| 0.743 | 1.322 | |
| p = 0.458 | p = 0.186 | |
| Heroism × Cond3 | −0.003 | 0.012 |
| (0.051) | (0.072) | |
| −0.054 | 0.160 | |
| p = 0.957 | p = 0.873 | |
| Heroism × Cond4 | 0.030 | 0.046 |
| (0.054) | (0.066) | |
| 0.558 | 0.699 | |
| p = 0.577 | p = 0.485 | |
| Heroism × Cond5 | −0.105 | −0.144 |
| (0.049) | (0.067) | |
| −2.135 | −2.134 | |
| p = 0.033 | p = 0.033 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.385 | 0.429 |
| R2 Adj. | 0.377 | 0.421 |
| RMSE | 1.01 | 1.01 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)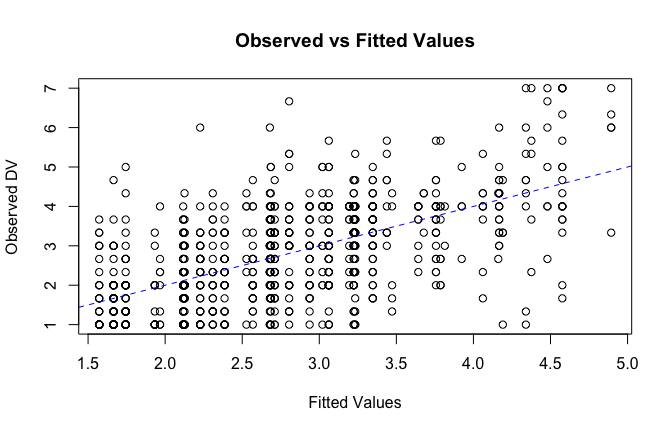
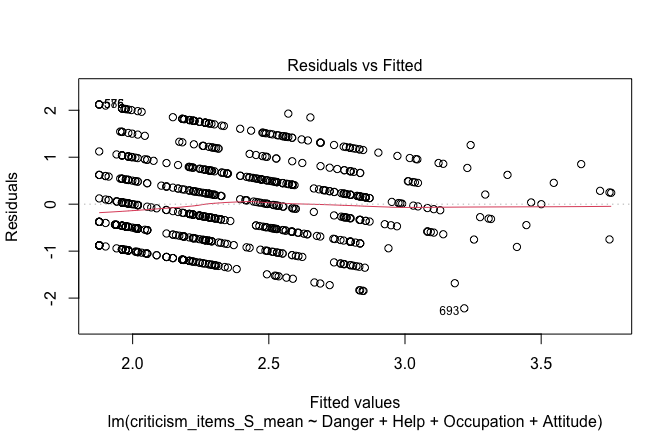
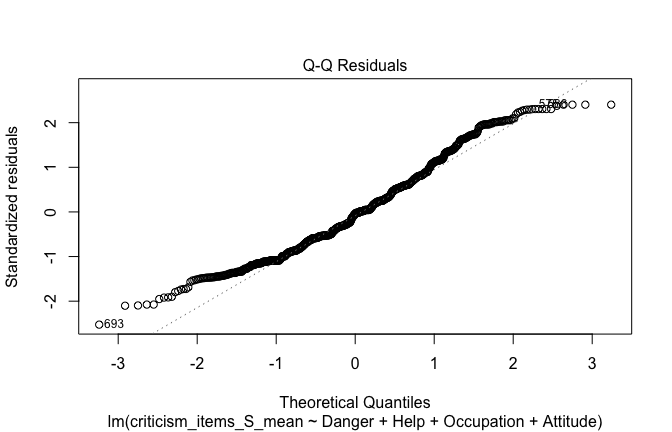
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(criticism_items_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(criticism_items_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)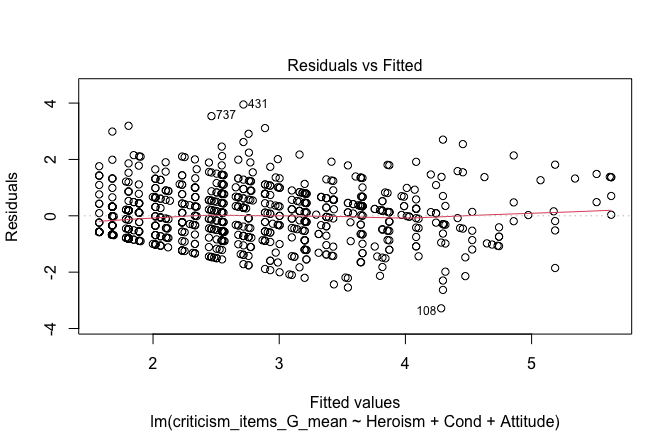
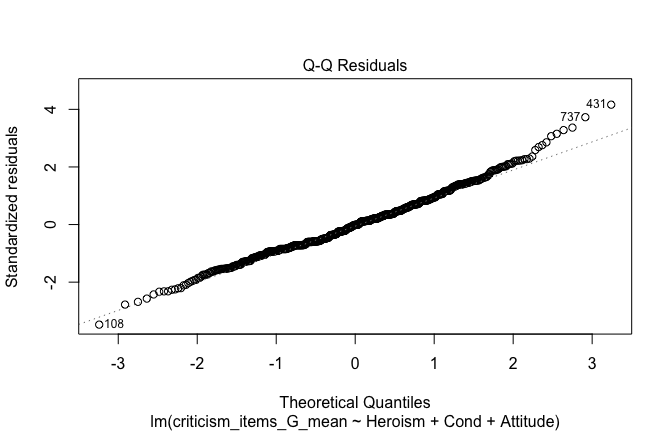
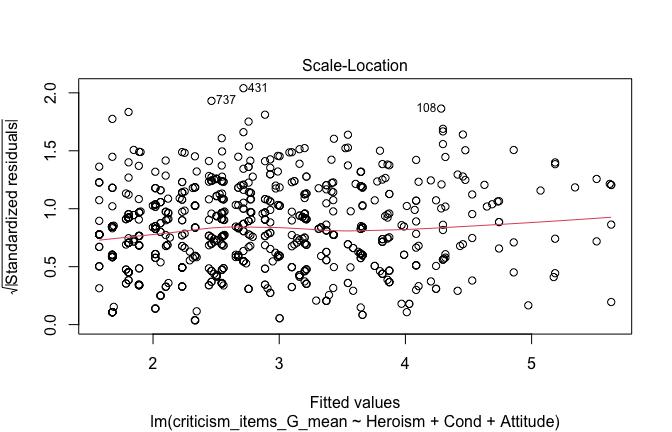
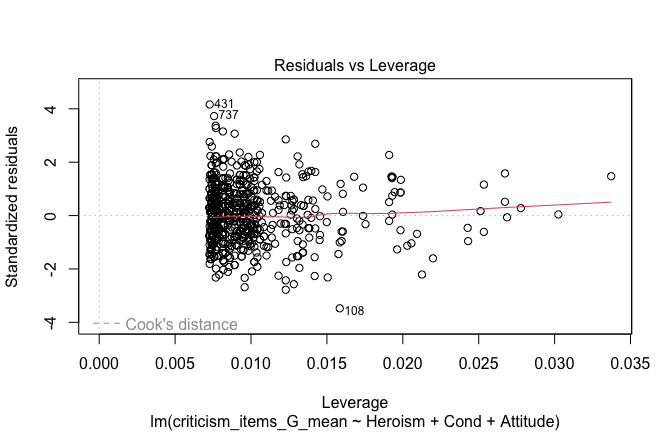
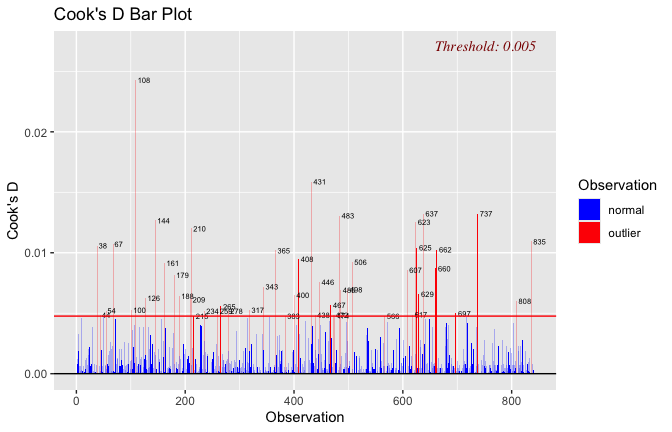
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.789 | 3.855 |
| (0.160) | (0.181) | |
| 23.612 | 21.314 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.213 | −0.232 |
| (0.032) | (0.035) | |
| −6.668 | −6.565 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.095 | 0.088 |
| (0.077) | (0.072) | |
| 1.222 | 1.228 | |
| p = 0.222 | p = 0.220 | |
| Cond2 | −0.022 | −0.030 |
| (0.082) | (0.087) | |
| −0.274 | −0.341 | |
| p = 0.784 | p = 0.733 | |
| Cond3 | −0.034 | −0.036 |
| (0.076) | (0.071) | |
| −0.445 | −0.516 | |
| p = 0.656 | p = 0.606 | |
| Cond4 | 0.136 | 0.123 |
| (0.074) | (0.076) | |
| 1.830 | 1.621 | |
| p = 0.068 | p = 0.105 | |
| Cond5 | −0.138 | −0.126 |
| (0.075) | (0.074) | |
| −1.849 | −1.696 | |
| p = 0.065 | p = 0.090 | |
| Attitude | −0.574 | −0.585 |
| (0.053) | (0.059) | |
| −10.731 | −9.984 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.456 | 0.497 |
| R2 Adj. | 0.451 | 0.492 |
| RMSE | 0.95 | 0.95 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)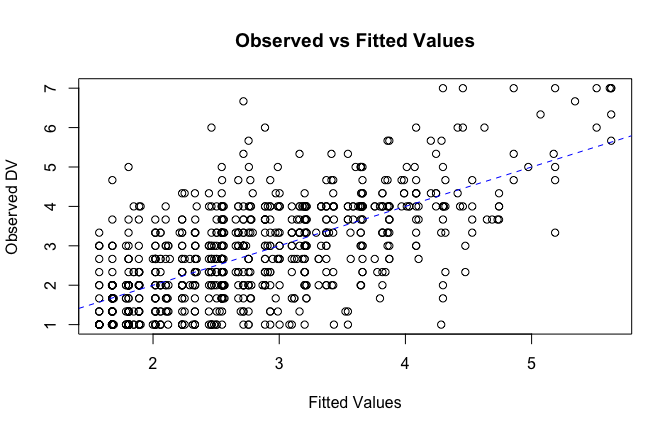
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(criticism_items_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(criticism_items_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)## Warning in lmrob.S(x, y, control = control): S refinements did not converge (to
## refine.tol=1e-07) in 200 (= k.max) steps
## Warning in lmrob.S(x, y, control = control): S refinements did not converge (to
## refine.tol=1e-07) in 200 (= k.max) steps## Warning in lmrob.fit(x, y, control, init = init): initial estim. 'init' not
## converged -- will be return()ed basically unchanged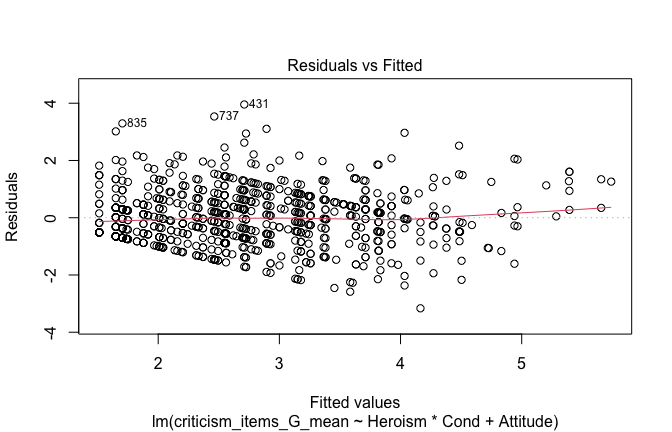
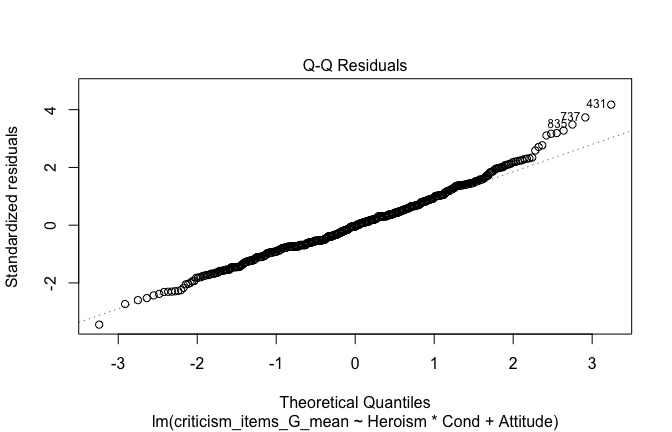
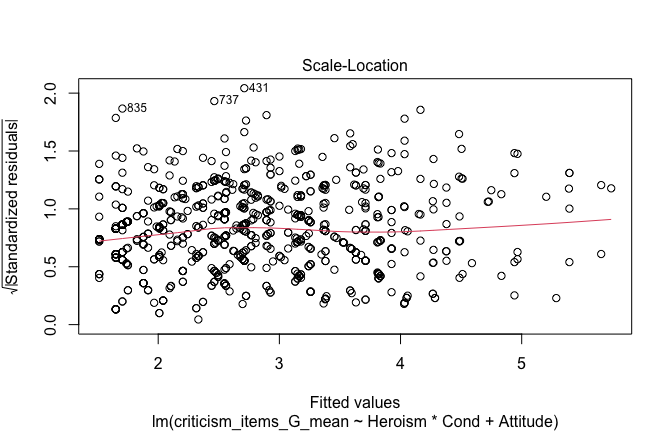
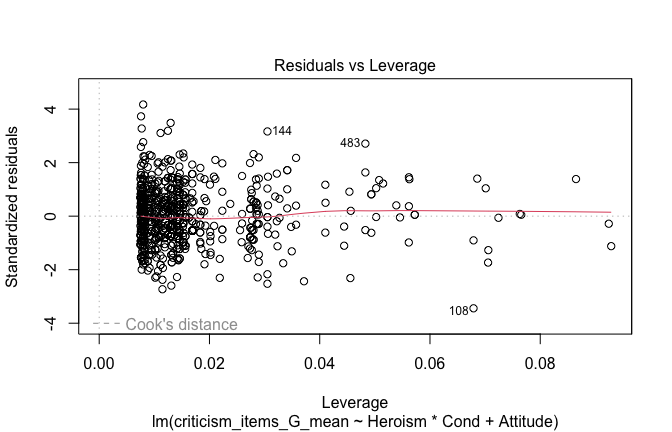
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.828 | 4.385 |
| (0.163) | ||
| 23.526 | ||
| p = <0.001 | ||
| Heroism | −0.212 | −0.324 |
| (0.032) | ||
| −6.598 | ||
| p = <0.001 | ||
| Cond1 | 0.612 | 0.895 |
| (0.368) | ||
| 1.663 | ||
| p = 0.097 | ||
| Cond2 | −0.446 | −0.960 |
| (0.212) | ||
| −2.100 | ||
| p = 0.036 | ||
| Cond3 | 0.020 | 0.424 |
| (0.273) | ||
| 0.072 | ||
| p = 0.943 | ||
| Cond4 | 0.113 | −0.412 |
| (0.246) | ||
| 0.458 | ||
| p = 0.647 | ||
| Cond5 | −0.054 | 0.232 |
| (0.250) | ||
| −0.217 | ||
| p = 0.828 | ||
| Attitude | −0.586 | −0.560 |
| (0.055) | ||
| −10.699 | ||
| p = <0.001 | ||
| Heroism × Cond1 | −0.093 | −0.145 |
| (0.062) | ||
| −1.508 | ||
| p = 0.132 | ||
| Heroism × Cond2 | 0.104 | 0.231 |
| (0.050) | ||
| 2.100 | ||
| p = 0.036 | ||
| Heroism × Cond3 | −0.016 | −0.094 |
| (0.048) | ||
| −0.338 | ||
| p = 0.735 | ||
| Heroism × Cond4 | −0.004 | 0.126 |
| (0.051) | ||
| −0.089 | ||
| p = 0.929 | ||
| Heroism × Cond5 | −0.025 | −0.093 |
| (0.047) | ||
| −0.540 | ||
| p = 0.589 | ||
| Num.Obs. | 840 | 840 |
| R2 | 0.460 | 0.824 |
| R2 Adj. | 0.452 | 0.821 |
| RMSE | 0.94 | 0.97 |
fitted_vals <- fitted(mod1)
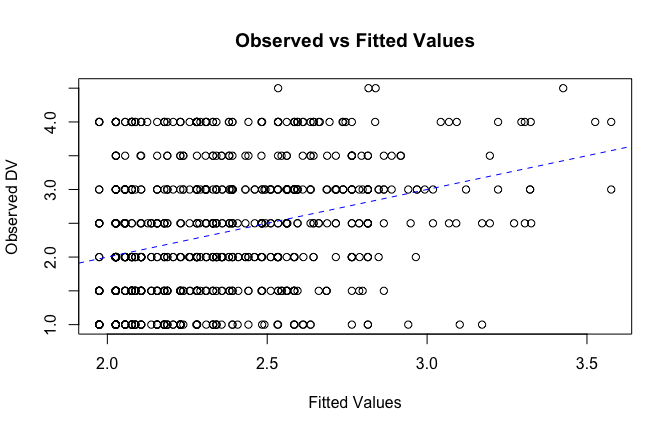
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: criticism_items_G_mean ~ Heroism"report(Anova(mod1 <- lm(criticism_items_G_mean ~ Heroism + Cond, data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 833)
## = 354.95, p < .001; Eta2 (partial) = 0.30, 95% CI [0.26, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 833) = 1.28, p = 0.271; Eta2 (partial) = 7.62e-03, 95% CI [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: criticism_items_G_mean ~ Heroism * Cond"report(Anova(mod2 <- lm(criticism_items_G_mean ~ Heroism * Cond, data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 828)
## = 328.15, p < .001; Eta2 (partial) = 0.28, 95% CI [0.24, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 828) = 0.97, p = 0.433; Eta2 (partial) = 5.84e-03, 95% CI [0.00, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 828) = 1.25, p = 0.286; Eta2 (partial) = 7.47e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: criticism_items_G_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(criticism_items_G_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 832)
## = 44.46, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 832) = 1.48, p = 0.195; Eta2 (partial) = 8.80e-03, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and medium
## (F(1, 832) = 115.16, p < .001; Eta2 (partial) = 0.12, 95% CI [0.09, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: criticism_items_G_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(criticism_items_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 827)
## = 43.54, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 827) = 1.30, p = 0.263; Eta2 (partial) = 7.78e-03, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and medium
## (F(1, 827) = 114.47, p < .001; Eta2 (partial) = 0.12, 95% CI [0.09, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 827) = 1.24, p = 0.286; Eta2 (partial) = 7.47e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = criticism_items_G_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Criticism accept. (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Criticism accept. (G), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'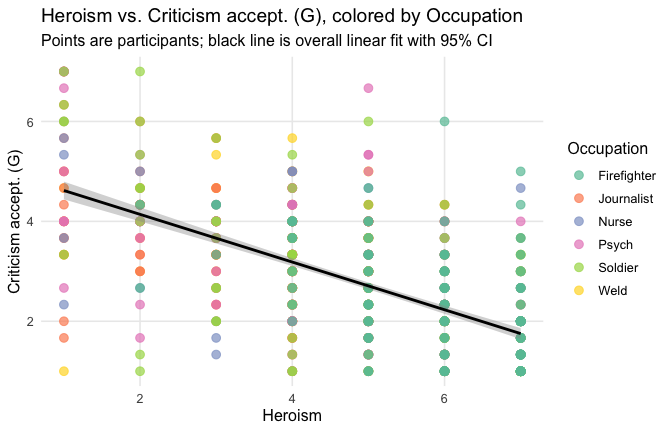
ggplot(scale_scores, aes(y = criticism_items_G_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Criticism accept. (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Criticism accept. (G) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'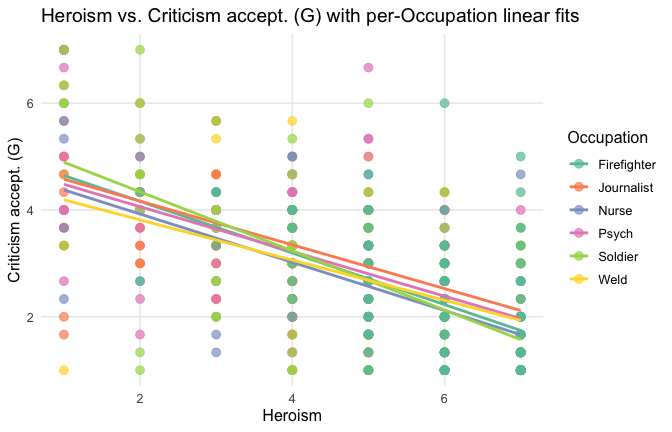
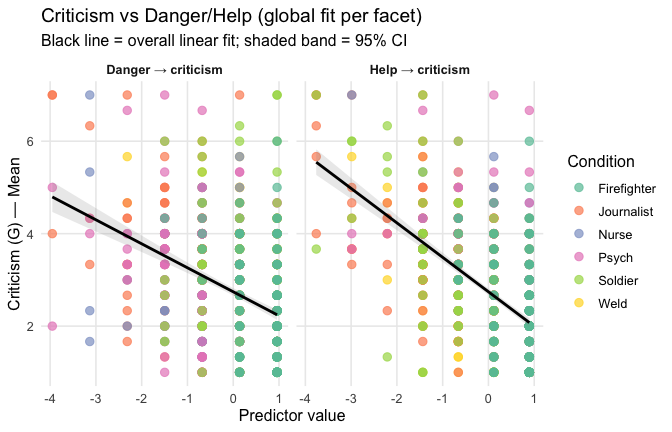
pal6 <- c("#800020", "#4E5BA6", "#1B7F79", "#4F718E", "#7A8F3E", "#B38E22")
pal6_alpha <- ggplot2::alpha(pal6, 0.7) # <- bake in transparency
ggplot(scale_scores, aes(x = Heroism, y = Gratitude_G_mean)) +
# 1) PER-CONDITION lines FIRST (go behind; already semi-transparent)
stat_smooth(
aes(color = Cond),
method = "lm", se = FALSE, fullrange = TRUE,
linewidth = 0.9, lineend = "round"
) +
# 2) OVERALL black line + grey CI on top
stat_smooth(
method = "lm", se = TRUE, fullrange = TRUE,
color = "black", fill = "grey30",
alpha = 0.22, linewidth = 1.6
) +
scale_color_manual(values = pal6_alpha, name = "Occupation") +
# keep legend lines opaque for readability there
guides(color = guide_legend(override.aes = list(alpha = 1, linewidth = 1.2))) +
labs(
x = "Heroism", y = "Gratitude",
) +
geom_point(size = 2, alpha = 0.25, color = "black", show.legend = FALSE) +
theme_minimal(base_size = 18) +
theme(
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
plot.title = element_text(face = "bold")
)## `geom_smooth()` using formula = 'y ~ x'
## `geom_smooth()` using formula = 'y ~ x'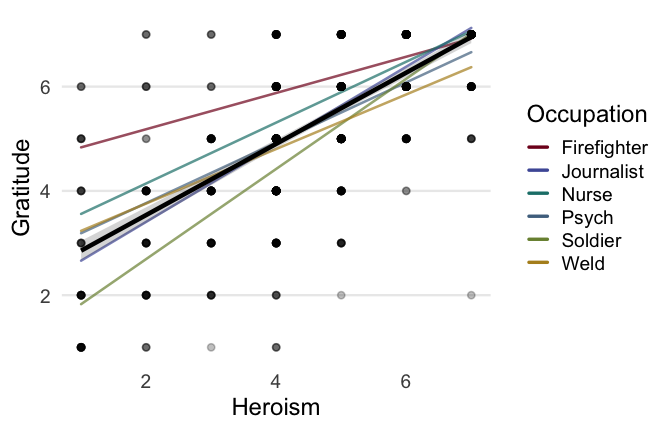
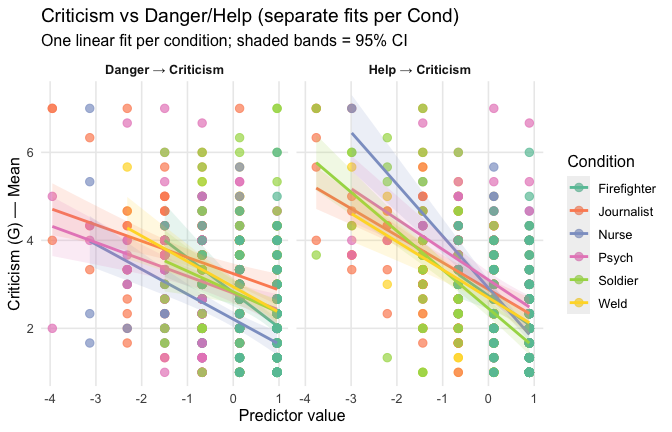
Overall: Heroism predict decreased general acceptability of criticism. This is true above and beyond attitude (see Model 3). It is true when controlling for normative effects of occupations (Model 2), and when controlling for both occupations and attitude (Model 4). See Summary table:
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(criticism_items_G_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(criticism_items_G_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(criticism_items_G_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(criticism_items_G_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 354.95 | < .001 | 0.299 |
| Occupation | Occupation | 5 | 833 | 1.28 | = 0.271 | 0.008 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 328.15 | < .001 | 0.284 |
| Occupation | Occupation | 5 | 828 | 0.97 | = 0.433 | 0.006 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 1.25 | = 0.286 | 0.007 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 44.46 | < .001 | 0.051 |
| Occupation | Occupation | 5 | 832 | 1.48 | = 0.195 | 0.009 |
| Attitude | Attitude | 1 | 832 | 115.16 | < .001 | 0.122 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 43.54 | < .001 | 0.050 |
| Occupation | Occupation | 5 | 827 | 1.30 | = 0.263 | 0.008 |
| Attitude | Attitude | 1 | 827 | 114.47 | < .001 | 0.122 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 1.24 | = 0.286 | 0.007 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "criticism_items_G_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(criticism_items_G_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(criticism_items_G_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(criticism_items_G_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(criticism_items_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | criticism_items_G_mean | Heroism | 1 | 833 | 354.95 | < .001 | 0.299 |
| ~ Heroism * Occupation | criticism_items_G_mean | Heroism | 1 | 828 | 328.15 | < .001 | 0.284 |
| ~ Heroism + Cond + Attitude | criticism_items_G_mean | Heroism | 1 | 832 | 44.46 | < .001 | 0.051 |
| ~ Heroism * Occupation + Attitude | criticism_items_G_mean | Heroism | 1 | 827 | 43.54 | < .001 | 0.050 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
Specific level
[An online post that says: “Journalists are evil and wish harm on other people”] The person making this post should be prosecuted using the UK laws against “grossly offensive” public messaging
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(criticism_items_S_mean ~ Heroism + Cond, data = scale_scores, na.action = na.exclude)
mod1r <- lmrob(criticism_items_S_mean ~ Heroism + Cond, data = scale_scores, na.action = na.exclude)
plot(mod1)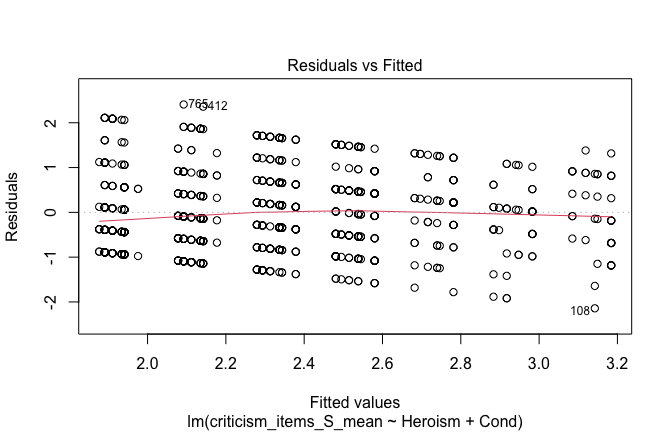
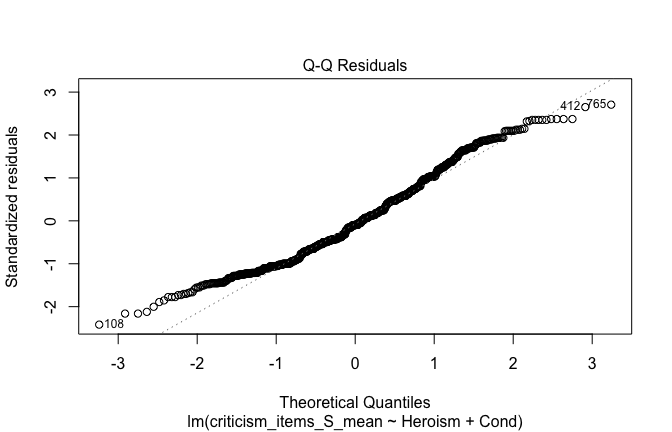
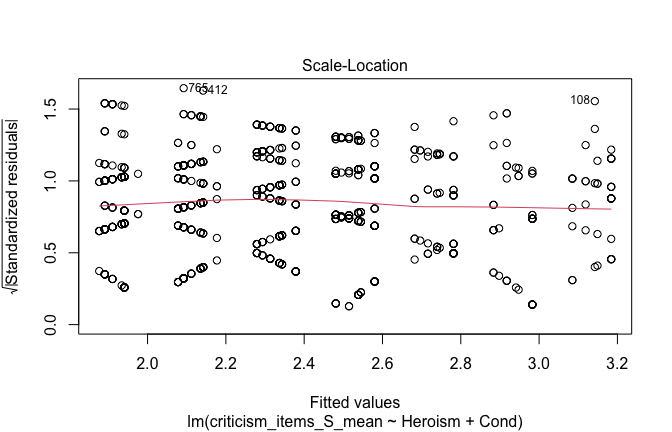
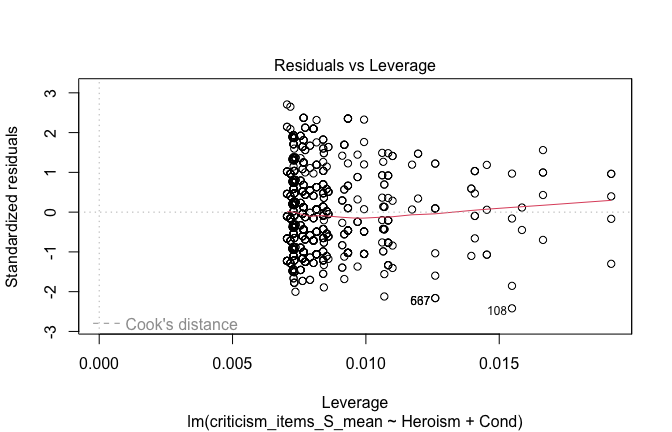
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)## Warning in w * res^2: longer object length is not a multiple of shorter object
## length## Warning in log(w) - (log(2 * pi) + log(s2) + (w * res^2)/s2): longer object
## length is not a multiple of shorter object length| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.331 | 3.397 |
| (0.109) | (0.117) | |
| 30.608 | 28.949 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.201 | −0.223 |
| (0.021) | (0.023) | |
| −9.496 | −9.776 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.031 | −0.047 |
| (0.072) | (0.082) | |
| −0.425 | −0.573 | |
| p = 0.671 | p = 0.567 | |
| Cond2 | 0.054 | 0.070 |
| (0.075) | (0.073) | |
| 0.725 | 0.951 | |
| p = 0.469 | p = 0.342 | |
| Cond3 | 0.019 | 0.041 |
| (0.070) | (0.068) | |
| 0.275 | 0.598 | |
| p = 0.784 | p = 0.550 | |
| Cond4 | −0.045 | −0.037 |
| (0.069) | (0.075) | |
| −0.645 | −0.497 | |
| p = 0.519 | p = 0.619 | |
| Cond5 | −0.011 | −0.022 |
| (0.069) | (0.080) | |
| −0.158 | −0.280 | |
| p = 0.874 | p = 0.780 | |
| Num.Obs. | 838 | 838 |
| R2 | 0.129 | 0.151 |
| R2 Adj. | 0.123 | 0.145 |
| RMSE | 0.89 | 0.89 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)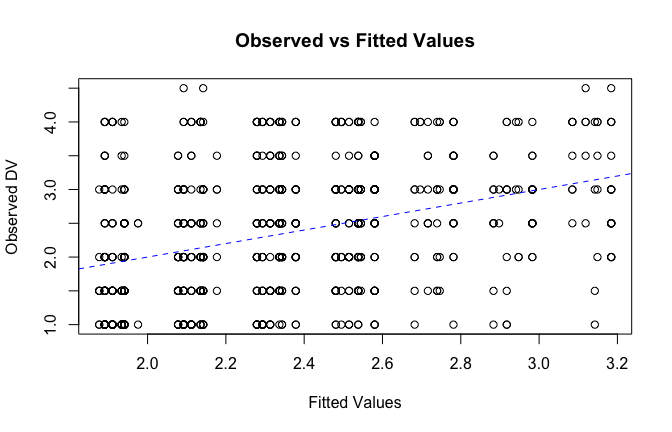
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(criticism_items_S_mean ~ Heroism * Cond, data = scale_scores, na.action = na.exclude)
mod1r <- lmrob(criticism_items_S_mean ~ Heroism * Cond, data = scale_scores, na.action = na.exclude)
plot(mod1)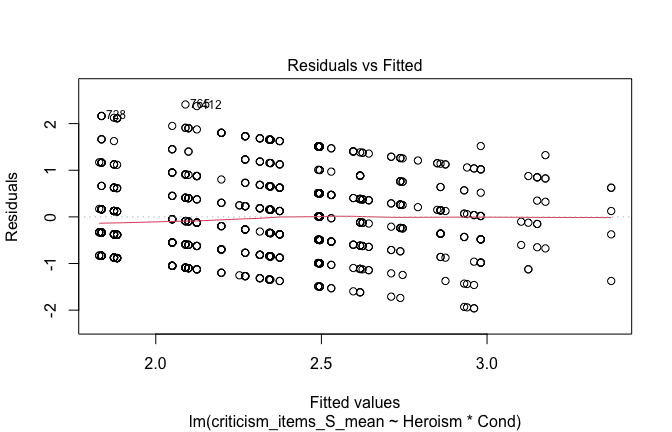
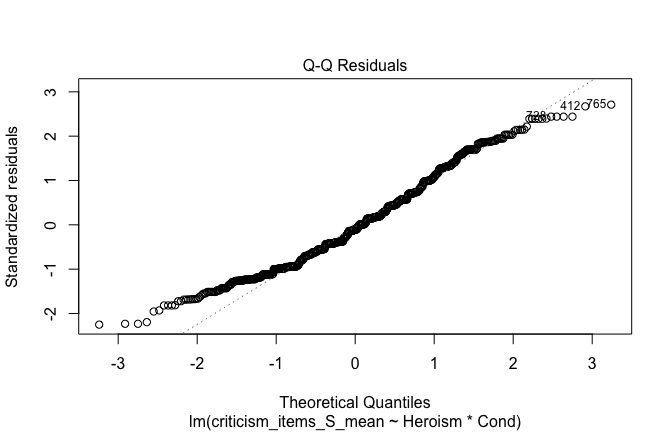
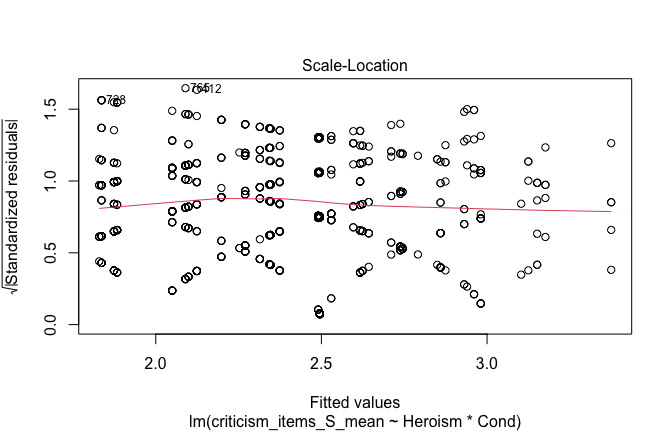
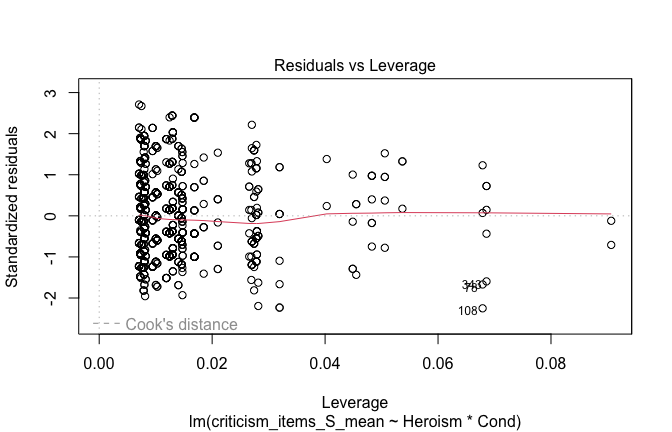
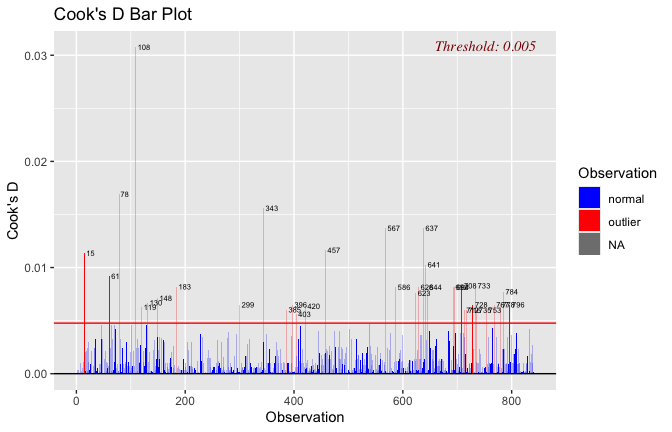
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)## Warning in w * res^2: longer object length is not a multiple of shorter object
## length
## Warning in w * res^2: longer object length is not a multiple of shorter object
## length| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.365 | 3.450 |
| (0.115) | (0.130) | |
| 29.315 | 26.547 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.202 | −0.226 |
| (0.022) | (0.024) | |
| −9.232 | −9.318 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.245 | 0.236 |
| (0.343) | (0.406) | |
| 0.714 | 0.582 | |
| p = 0.475 | p = 0.561 | |
| Cond2 | −0.262 | −0.365 |
| (0.196) | (0.186) | |
| −1.340 | −1.963 | |
| p = 0.181 | p = 0.050 | |
| Cond3 | 0.260 | 0.203 |
| (0.255) | (0.263) | |
| 1.019 | 0.770 | |
| p = 0.309 | p = 0.441 | |
| Cond4 | 0.007 | −0.026 |
| (0.230) | (0.222) | |
| 0.030 | −0.117 | |
| p = 0.976 | p = 0.907 | |
| Cond5 | 0.027 | 0.143 |
| (0.230) | (0.263) | |
| 0.117 | 0.543 | |
| p = 0.907 | p = 0.587 | |
| Heroism × Cond1 | −0.052 | −0.054 |
| (0.058) | (0.066) | |
| −0.899 | −0.820 | |
| p = 0.369 | p = 0.412 | |
| Heroism × Cond2 | 0.080 | 0.112 |
| (0.047) | (0.043) | |
| 1.717 | 2.565 | |
| p = 0.086 | p = 0.010 | |
| Heroism × Cond3 | −0.049 | −0.035 |
| (0.045) | (0.045) | |
| −1.088 | −0.791 | |
| p = 0.277 | p = 0.429 | |
| Heroism × Cond4 | −0.019 | −0.012 |
| (0.047) | (0.044) | |
| −0.397 | −0.266 | |
| p = 0.692 | p = 0.790 | |
| Heroism × Cond5 | −0.014 | −0.041 |
| (0.043) | (0.049) | |
| −0.324 | −0.838 | |
| p = 0.746 | p = 0.402 | |
| Num.Obs. | 838 | 838 |
| R2 | 0.134 | 0.162 |
| R2 Adj. | 0.123 | 0.151 |
| RMSE | 0.89 | 0.89 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(criticism_items_S_mean ~ Heroism + Cond + Attitude, data = scale_scores, na.action = na.exclude)
mod1r <- lmrob(criticism_items_S_mean ~ Heroism + Cond + Attitude, data = scale_scores, na.action = na.exclude)
plot(mod1)
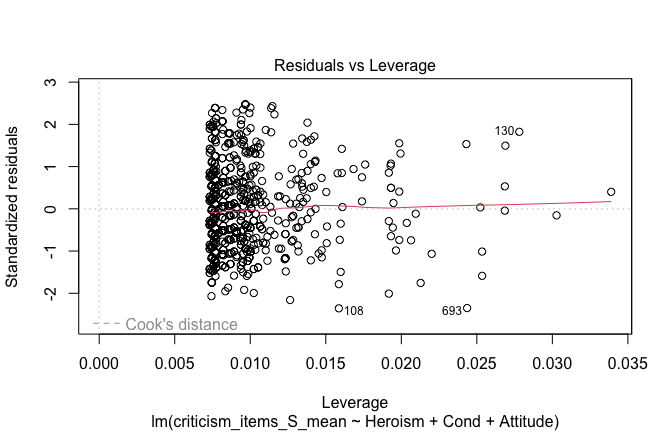
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)## Warning in w * res^2: longer object length is not a multiple of shorter object
## length
## Warning in w * res^2: longer object length is not a multiple of shorter object
## length| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.849 | 2.850 |
| (0.149) | (0.178) | |
| 19.175 | 15.994 | |
| p = <0.001 | p = <0.001 | |
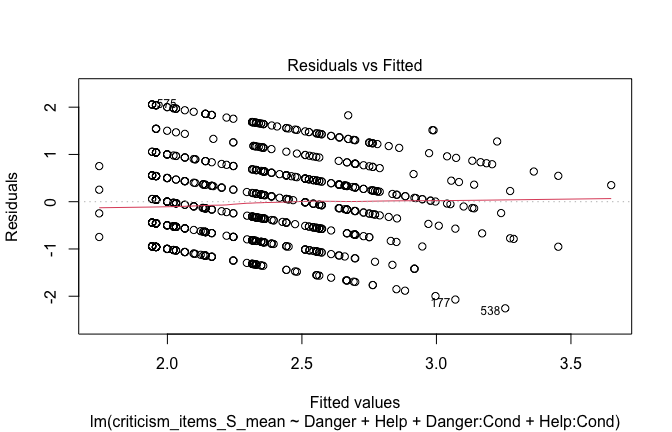
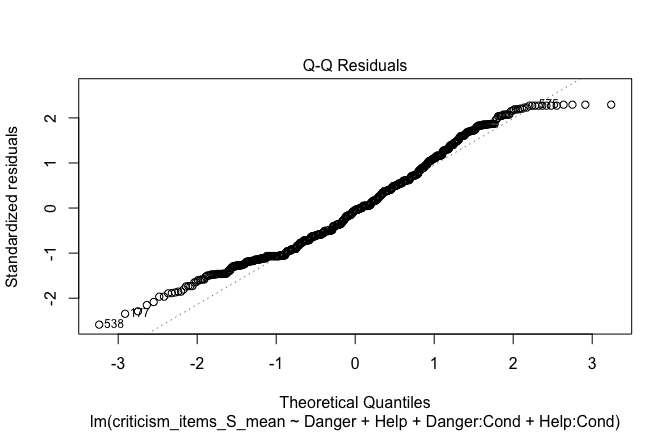
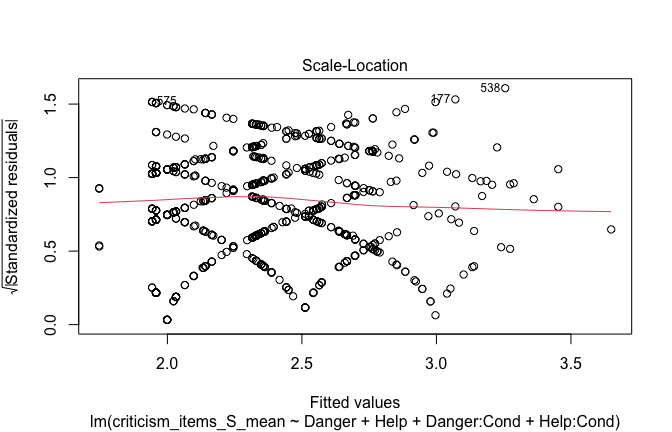
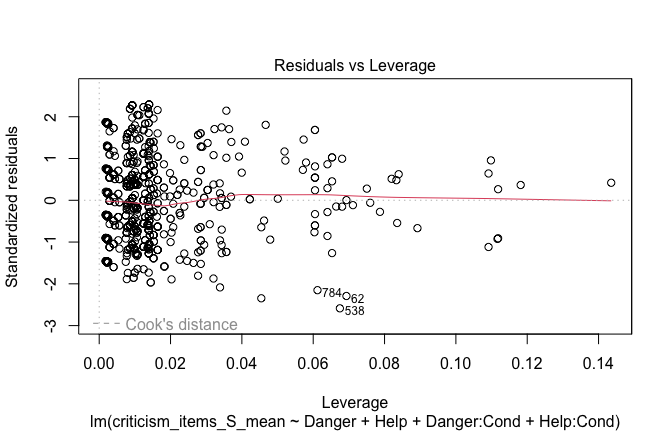
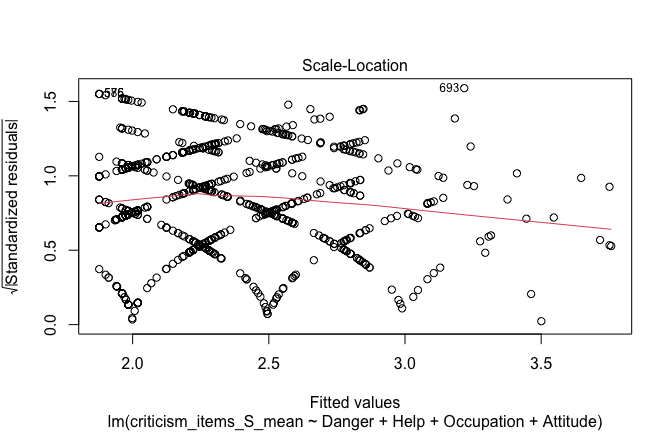
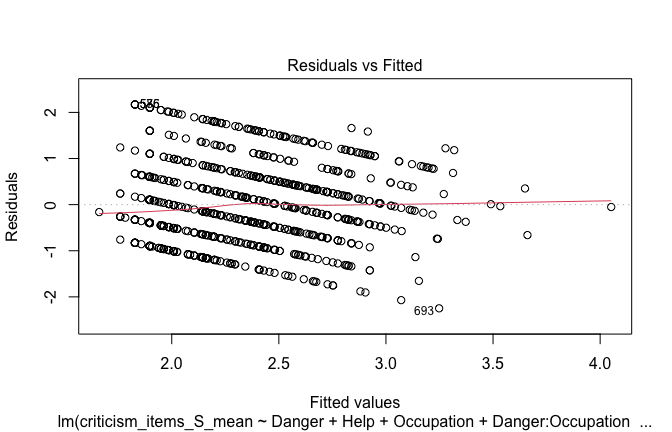
| Heroism | −0.104 | −0.112 |
| (0.030) | (0.035) | |
| −3.508 | −3.167 | |
| p = <0.001 | p = 0.002 | |
| Cond1 | 0.019 | 0.004 |
| (0.072) | (0.081) | |
| 0.267 | 0.045 | |
| p = 0.789 | p = 0.964 | |
| Cond2 | −0.023 | −0.015 |
| (0.076) | (0.074) | |
| −0.306 | −0.208 | |
| p = 0.759 | p = 0.835 | |
| Cond3 | 0.063 | 0.086 |
| (0.070) | (0.068) | |
| 0.892 | 1.272 | |
| p = 0.372 | p = 0.204 | |
| Cond4 | −0.020 | −0.002 |
| (0.069) | (0.075) | |
| −0.295 | −0.029 | |
| p = 0.768 | p = 0.977 | |
| Cond5 | −0.051 | −0.070 |
| (0.069) | (0.078) | |
| −0.745 | −0.895 | |
| p = 0.456 | p = 0.371 | |
| Attitude | −0.233 | −0.256 |
| (0.050) | (0.057) | |
| −4.705 | −4.467 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 838 | 838 |
| R2 | 0.152 | 0.176 |
| R2 Adj. | 0.144 | 0.169 |
| RMSE | 0.88 | 0.88 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(criticism_items_S_mean ~ Heroism*Cond + Attitude, data = scale_scores, na.action = na.exclude)
mod1r <- lmrob(criticism_items_S_mean ~ Heroism*Cond + Attitude, data = scale_scores, na.action = na.exclude)
plot(mod1)
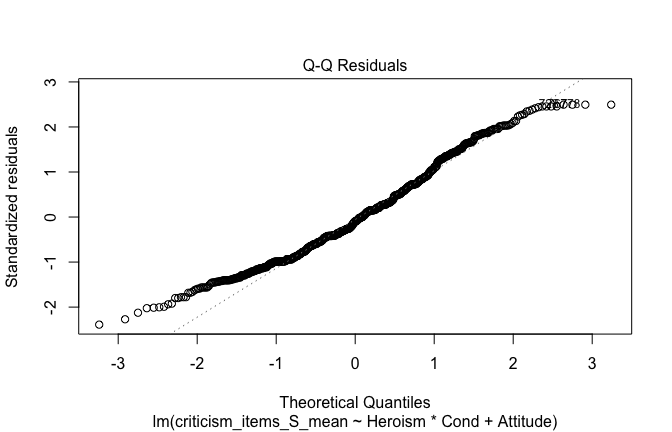
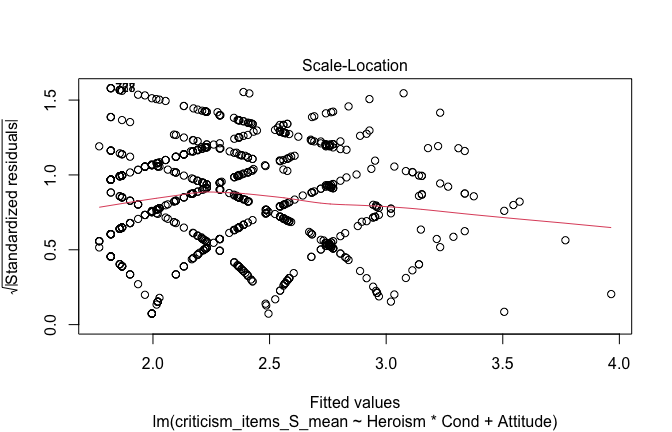
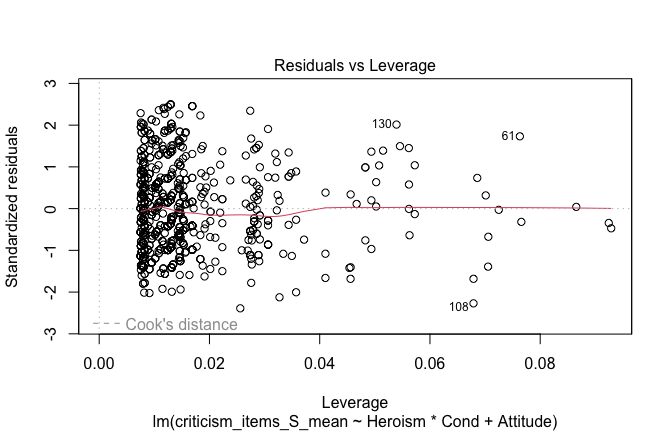
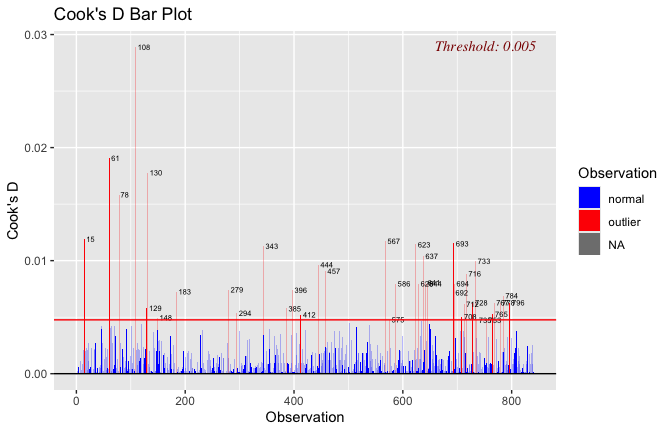
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)## Warning in w * res^2: longer object length is not a multiple of shorter object
## length
## Warning in w * res^2: longer object length is not a multiple of shorter object
## length| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.868 | 2.892 |
| (0.150) | (0.184) | |
| 19.064 | 15.746 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.099 | −0.111 |
| (0.030) | (0.036) | |
| −3.333 | −3.088 | |
| p = <0.001 | p = 0.002 | |
| Cond1 | 0.444 | 0.459 |
| (0.340) | (0.394) | |
| 1.303 | 1.166 | |
| p = 0.193 | p = 0.244 | |
| Cond2 | −0.457 | −0.549 |
| (0.197) | (0.169) | |
| −2.323 | −3.249 | |
| p = 0.020 | p = 0.001 | |
| Cond3 | 0.332 | 0.261 |
| (0.252) | (0.255) | |
| 1.318 | 1.022 | |
| p = 0.188 | p = 0.307 | |
| Cond4 | 0.088 | 0.056 |
| (0.228) | (0.224) | |
| 0.389 | 0.251 | |
| p = 0.698 | p = 0.802 | |
| Cond5 | −0.201 | −0.105 |
| (0.231) | (0.240) | |
| −0.872 | −0.437 | |
| p = 0.383 | p = 0.662 | |
| Attitude | −0.254 | −0.276 |
| (0.051) | (0.058) | |
| −5.006 | −4.766 | |
| p = <0.001 | p = <0.001 | |
| Heroism × Cond1 | −0.077 | −0.083 |
| (0.057) | (0.064) | |
| −1.350 | −1.294 | |
| p = 0.177 | p = 0.196 | |
| Heroism × Cond2 | 0.107 | 0.135 |
| (0.046) | (0.039) | |
| 2.316 | 3.412 | |
| p = 0.021 | p = <0.001 | |
| Heroism × Cond3 | −0.054 | −0.038 |
| (0.044) | (0.043) | |
| −1.230 | −0.875 | |
| p = 0.219 | p = 0.382 | |
| Heroism × Cond4 | −0.033 | −0.024 |
| (0.047) | (0.045) | |
| −0.712 | −0.535 | |
| p = 0.477 | p = 0.593 | |
| Heroism × Cond5 | 0.021 | −0.004 |
| (0.043) | (0.045) | |
| 0.479 | −0.084 | |
| p = 0.632 | p = 0.933 | |
| Num.Obs. | 838 | 838 |
| R2 | 0.160 | 0.190 |
| R2 Adj. | 0.148 | 0.178 |
| RMSE | 0.87 | 0.88 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$criticism_items_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)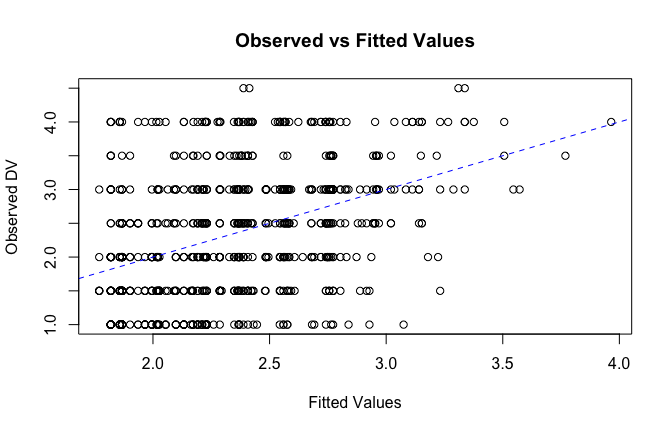
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: criticism_items_S_mean ~ Heroism"report(Anova(mod1 <- lm(criticism_items_S_mean ~ Heroism + Cond, data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 831)
## = 90.18, p < .001; Eta2 (partial) = 0.10, 95% CI [0.07, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 831) = 0.22, p = 0.955; Eta2 (partial) = 1.30e-03, 95% CI [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: criticism_items_S_mean ~ Heroism * Cond"report(Anova(mod2 <- lm(criticism_items_S_mean ~ Heroism * Cond, data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 826)
## = 85.23, p < .001; Eta2 (partial) = 0.09, 95% CI [0.06, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 826) = 0.75, p = 0.585; Eta2 (partial) = 4.53e-03, 95% CI [0.00, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 826) = 1.05, p = 0.386; Eta2 (partial) = 6.33e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: criticism_items_S_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(criticism_items_S_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 830)
## = 12.31, p < .001; Eta2 (partial) = 0.01, 95% CI [4.13e-03, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 830) = 0.26, p = 0.935; Eta2 (partial) = 1.56e-03, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 830) = 22.14, p < .001; Eta2 (partial) = 0.03, 95% CI [0.01, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: criticism_items_S_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(criticism_items_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 825)
## = 11.11, p < .001; Eta2 (partial) = 0.01, 95% CI [3.42e-03, 1.00])
## - The main effect of Cond is statistically not significant and small (F(5, 825)
## = 1.67, p = 0.139; Eta2 (partial) = 0.01, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 825) = 25.06, p < .001; Eta2 (partial) = 0.03, 95% CI [0.01, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 825) = 1.65, p = 0.144; Eta2 (partial) = 9.90e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = criticism_items_S_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Criticism accept. (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Criticism accept. (S), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'## Warning: Removed 2 rows containing non-finite outside the scale range
## (`stat_smooth()`).## Warning: Removed 2 rows containing missing values or values outside the scale range
## (`geom_point()`).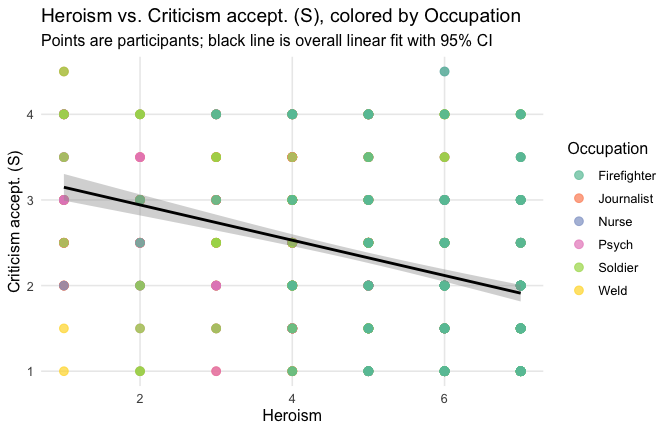
ggplot(scale_scores, aes(y = criticism_items_S_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Criticism accept. (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Criticism accept. (S) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'## Warning: Removed 2 rows containing non-finite outside the scale range (`stat_smooth()`).
## Removed 2 rows containing missing values or values outside the scale range
## (`geom_point()`).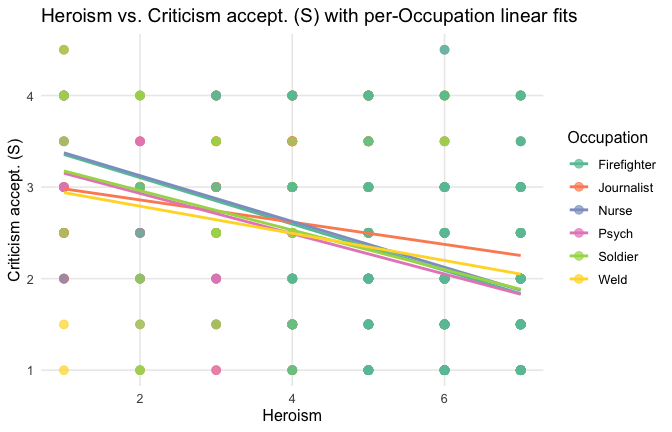
Overall: Heroism predict decreased specific acceptability of criticism. This is true above and beyond attitude (see Model 3)– Although effect sizes are drastically reduced when accounting for attitude in the case of specific acceptability of criticism. It is true when controlling for normative effects of occupations (Model 2), and when controlling for both occupations and attitude (Model 4). See Summary table:
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(criticism_items_S_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(criticism_items_S_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(criticism_items_S_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(criticism_items_S_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 831 | 90.18 | < .001 | 0.098 |
| Occupation | Occupation | 5 | 831 | 0.22 | = 0.955 | 0.001 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 826 | 85.23 | < .001 | 0.094 |
| Occupation | Occupation | 5 | 826 | 0.75 | = 0.585 | 0.005 |
| Heroism:Occupation | Heroism:Occupation | 5 | 826 | 1.05 | = 0.386 | 0.006 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 830 | 12.31 | < .001 | 0.015 |
| Occupation | Occupation | 5 | 830 | 0.26 | = 0.935 | 0.002 |
| Attitude | Attitude | 1 | 830 | 22.14 | < .001 | 0.026 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 825 | 11.11 | < .001 | 0.013 |
| Occupation | Occupation | 5 | 825 | 1.67 | = 0.139 | 0.010 |
| Attitude | Attitude | 1 | 825 | 25.06 | < .001 | 0.029 |
| Heroism:Occupation | Heroism:Occupation | 5 | 825 | 1.65 | = 0.144 | 0.010 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "criticism_items_S_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(criticism_items_S_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(criticism_items_S_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(criticism_items_S_mean ~ Heroism + Cond+ scale(Attitude), data = scale_scores)
mod4 <- lm(criticism_items_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | criticism_items_S_mean | Heroism | 1 | 831 | 90.18 | < .001 | 0.098 |
| ~ Heroism * Occupation | criticism_items_S_mean | Heroism | 1 | 826 | 85.23 | < .001 | 0.094 |
| ~ Heroism + Cond + Attitude | criticism_items_S_mean | Heroism | 1 | 830 | 12.31 | < .001 | 0.015 |
| ~ Heroism * Occupation + Attitude | criticism_items_S_mean | Heroism | 1 | 825 | 11.11 | < .001 | 0.013 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
==> Full support for our hypotheses. Across all occupations Heroism predict general- and specific-level acceptability of criticism, with or without controlling for attitude.
H3: Heroism is associated with reduced support for demands from workers
Because it is expected from heroes to be selfless, demands from workers are incompatible with the hero status and should be evaluated negatively. This is a backlash from the heroic status that parallels previous findings on the exploitation of heroes (see Stanley & Kay, 2024). At the general level, it means reporting that it is justified for workers to take the lead (vs the government to take the lead) on pushing demands to improve their situation. At the specific level, it means supporting the right for workers to protest and make demands to improve their working situation.
General level
[it is justified for] XXX, and not the government, to take the lead on improvements that benefit the profession
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(DemandSupp_G_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(DemandSupp_G_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
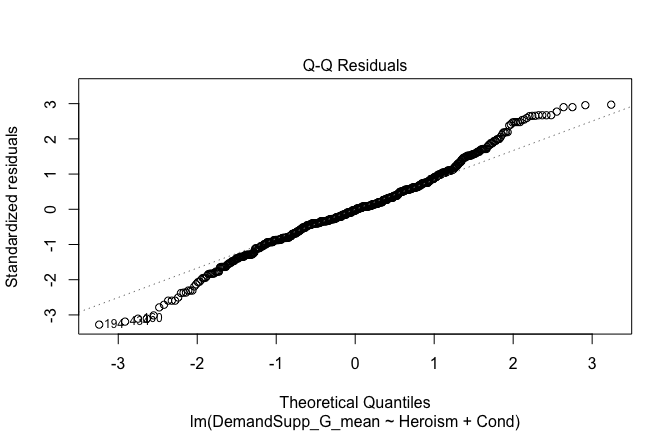
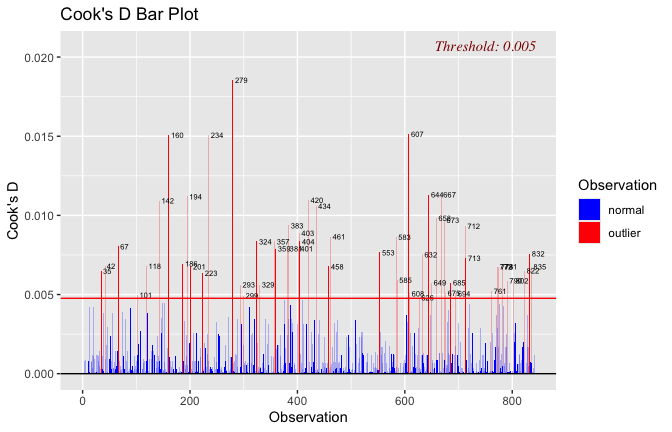
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.897 | 3.920 |
| (0.128) | (0.121) | |
| 30.509 | 32.351 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.061 | 0.052 |
| (0.025) | (0.025) | |
| 2.447 | 2.088 | |
| p = 0.015 | p = 0.037 | |
| Cond1 | 0.089 | 0.021 |
| (0.084) | (0.087) | |
| 1.053 | 0.237 | |
| p = 0.293 | p = 0.813 | |
| Cond2 | 0.282 | 0.308 |
| (0.088) | (0.077) | |
| 3.217 | 3.992 | |
| p = 0.001 | p = <0.001 | |
| Cond3 | −0.113 | −0.074 |
| (0.083) | (0.087) | |
| −1.363 | −0.856 | |
| p = 0.173 | p = 0.392 | |
| Cond4 | 0.193 | 0.203 |
| (0.081) | (0.070) | |
| 2.375 | 2.897 | |
| p = 0.018 | p = 0.004 | |
| Cond5 | −0.352 | −0.356 |
| (0.081) | (0.078) | |
| −4.315 | −4.554 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.040 | 0.047 |
| R2 Adj. | 0.033 | 0.040 |
| RMSE | 1.04 | 1.05 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)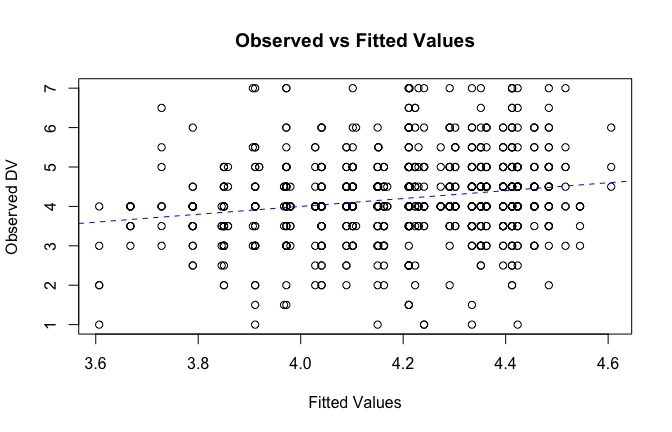
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(DemandSupp_G_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(DemandSupp_G_mean ~ Heroism * Cond, data = scale_scores)## Warning in lmrob.S(x, y, control = control): S refinements did not converge (to
## refine.tol=1e-07) in 200 (= k.max) steps
## Warning in lmrob.S(x, y, control = control): S refinements did not converge (to
## refine.tol=1e-07) in 200 (= k.max) steps## Warning in lmrob.fit(x, y, control, init = init): initial estim. 'init' not
## converged -- will be return()ed basically unchanged
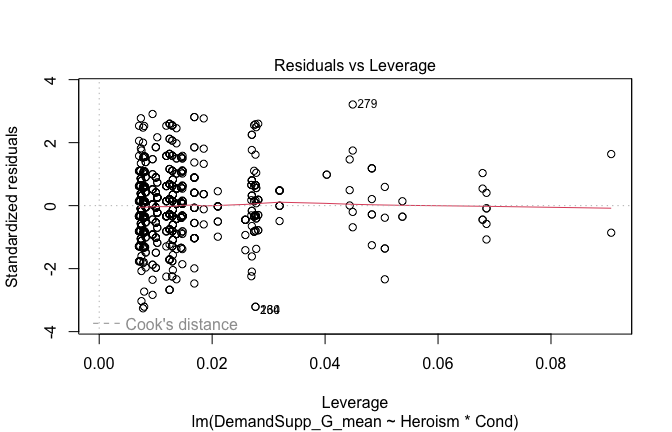
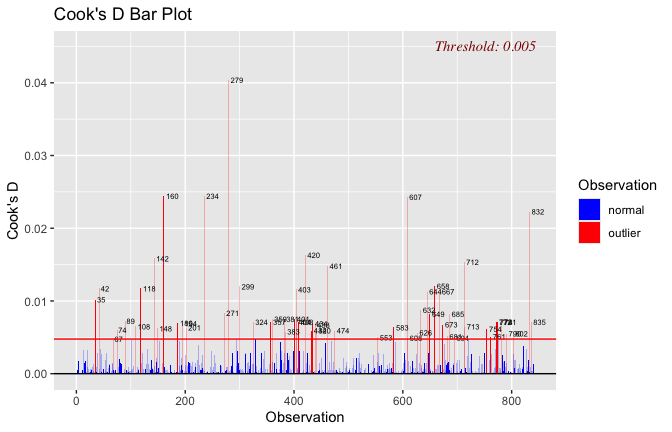
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.932 | 3.686 |
| (0.135) | ||
| 29.131 | ||
| p = <0.001 | ||
| Heroism | 0.052 | 0.095 |
| (0.026) | ||
| 2.043 | ||
| p = 0.041 | ||
| Cond1 | 0.435 | 0.119 |
| (0.403) | ||
| 1.077 | ||
| p = 0.282 | ||
| Cond2 | 0.363 | 0.490 |
| (0.229) | ||
| 1.583 | ||
| p = 0.114 | ||
| Cond3 | −0.460 | −0.372 |
| (0.300) | ||
| −1.532 | ||
| p = 0.126 | ||
| Cond4 | 0.332 | 0.263 |
| (0.271) | ||
| 1.227 | ||
| p = 0.220 | ||
| Cond5 | −0.653 | −0.235 |
| (0.270) | ||
| −2.419 | ||
| p = 0.016 | ||
| Heroism × Cond1 | −0.055 | −0.045 |
| (0.068) | ||
| −0.817 | ||
| p = 0.414 | ||
| Heroism × Cond2 | −0.024 | −0.068 |
| (0.054) | ||
| −0.439 | ||
| p = 0.661 | ||
| Heroism × Cond3 | 0.064 | 0.071 |
| (0.053) | ||
| 1.219 | ||
| p = 0.223 | ||
| Heroism × Cond4 | −0.030 | −0.021 |
| (0.056) | ||
| −0.538 | ||
| p = 0.591 | ||
| Heroism × Cond5 | 0.061 | 0.014 |
| (0.051) | ||
| 1.205 | ||
| p = 0.228 | ||
| Num.Obs. | 840 | 840 |
| R2 | 0.044 | 0.142 |
| R2 Adj. | 0.031 | 0.131 |
| RMSE | 1.04 | 1.05 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(DemandSupp_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(DemandSupp_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)
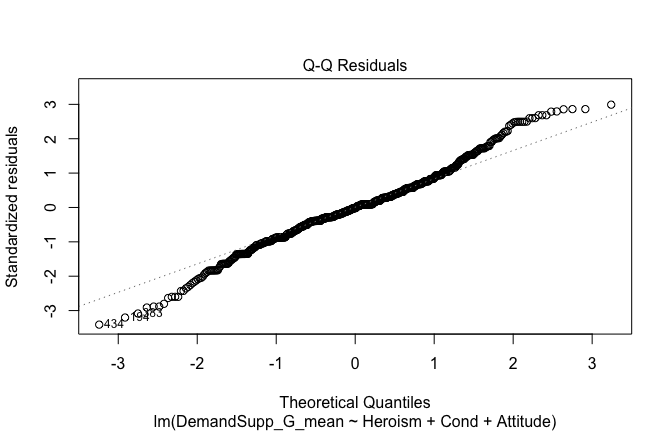
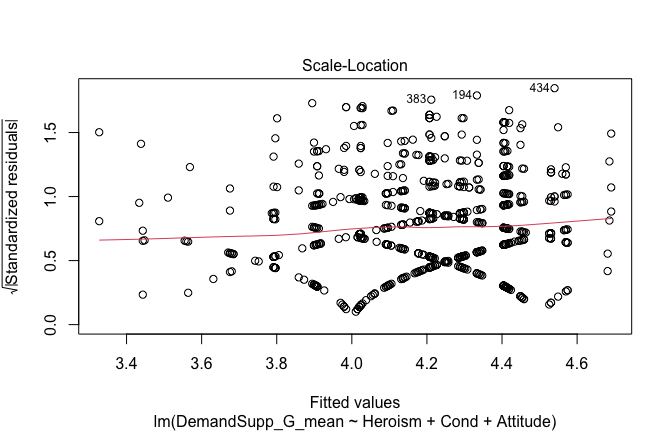
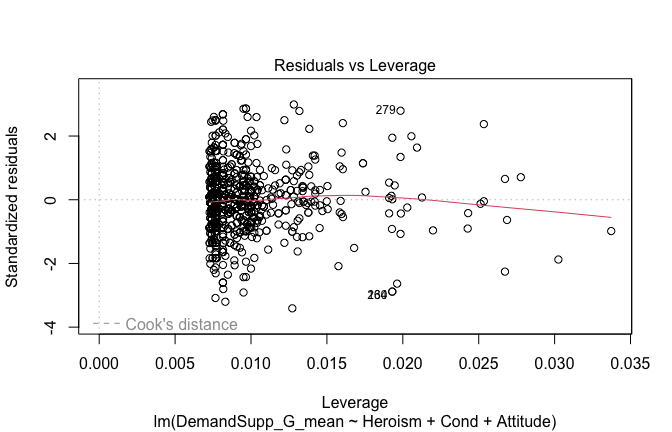
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.221 | 4.258 |
| (0.176) | (0.185) | |
| 23.974 | 23.021 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.005 | −0.016 |
| (0.035) | (0.037) | |
| −0.135 | −0.425 | |
| p = 0.893 | p = 0.671 | |
| Cond1 | 0.056 | −0.015 |
| (0.085) | (0.086) | |
| 0.657 | −0.168 | |
| p = 0.511 | p = 0.867 | |
| Cond2 | 0.333 | 0.345 |
| (0.090) | (0.077) | |
| 3.721 | 4.506 | |
| p = <0.001 | p = <0.001 | |
| Cond3 | −0.141 | −0.097 |
| (0.083) | (0.087) | |
| −1.703 | −1.117 | |
| p = 0.089 | p = 0.264 | |
| Cond4 | 0.178 | 0.196 |
| (0.081) | (0.069) | |
| 2.184 | 2.825 | |
| p = 0.029 | p = 0.005 | |
| Cond5 | −0.324 | −0.320 |
| (0.082) | (0.080) | |
| −3.965 | −3.979 | |
| p = <0.001 | p = <0.001 | |
| Attitude | 0.156 | 0.160 |
| (0.059) | (0.063) | |
| 2.659 | 2.529 | |
| p = 0.008 | p = 0.012 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.048 | 0.056 |
| R2 Adj. | 0.040 | 0.048 |
| RMSE | 1.04 | 1.04 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)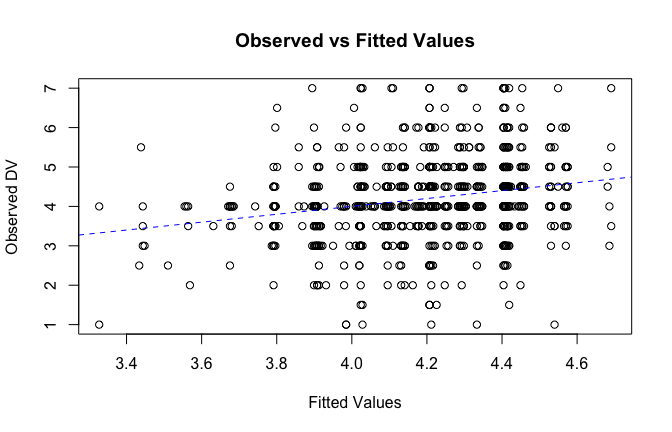
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(DemandSupp_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(DemandSupp_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)
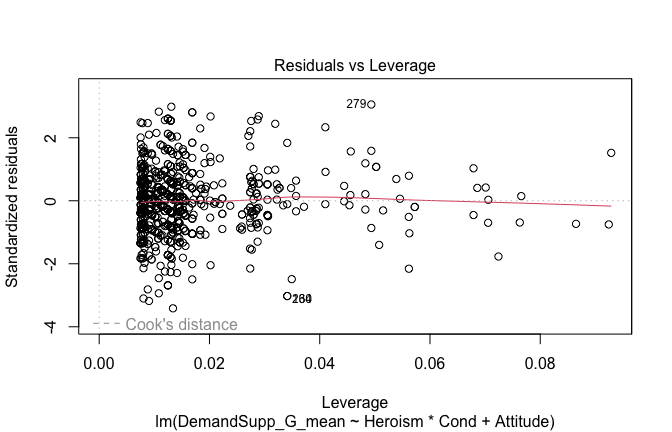
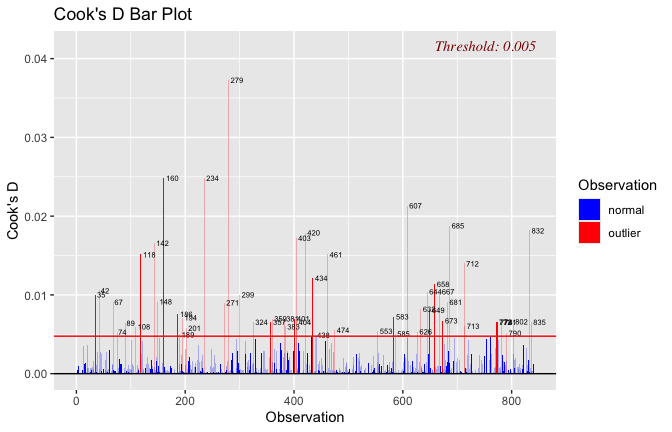
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.230 | 4.237 |
| (0.179) | (0.187) | |
| 23.647 | 22.613 | |
| p = <0.001 | p = <0.001 | |
| Heroism | −0.009 | −0.015 |
| (0.035) | (0.037) | |
| −0.263 | −0.416 | |
| p = 0.792 | p = 0.678 | |
| Cond1 | 0.315 | 0.252 |
| (0.405) | (0.371) | |
| 0.778 | 0.680 | |
| p = 0.437 | p = 0.497 | |
| Cond2 | 0.482 | 0.573 |
| (0.233) | (0.202) | |
| 2.065 | 2.839 | |
| p = 0.039 | p = 0.005 | |
| Cond3 | −0.504 | −0.624 |
| (0.300) | (0.280) | |
| −1.680 | −2.226 | |
| p = 0.093 | p = 0.026 | |
| Cond4 | 0.283 | 0.301 |
| (0.271) | (0.232) | |
| 1.046 | 1.300 | |
| p = 0.296 | p = 0.194 | |
| Cond5 | −0.516 | −0.469 |
| (0.274) | (0.271) | |
| −1.882 | −1.733 | |
| p = 0.060 | p = 0.083 | |
| Attitude | 0.152 | 0.150 |
| (0.060) | (0.062) | |
| 2.532 | 2.407 | |
| p = 0.012 | p = 0.016 | |
| Heroism × Cond1 | −0.040 | −0.041 |
| (0.068) | (0.066) | |
| −0.592 | −0.627 | |
| p = 0.554 | p = 0.531 | |
| Heroism × Cond2 | −0.041 | −0.060 |
| (0.055) | (0.050) | |
| −0.748 | −1.215 | |
| p = 0.455 | p = 0.225 | |
| Heroism × Cond3 | 0.068 | 0.100 |
| (0.052) | (0.053) | |
| 1.289 | 1.878 | |
| p = 0.198 | p = 0.061 | |
| Heroism × Cond4 | −0.021 | −0.020 |
| (0.056) | (0.049) | |
| −0.377 | −0.398 | |
| p = 0.706 | p = 0.691 | |
| Heroism × Cond5 | 0.040 | 0.033 |
| (0.051) | (0.055) | |
| 0.790 | 0.610 | |
| p = 0.430 | p = 0.542 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.051 | 0.062 |
| R2 Adj. | 0.037 | 0.048 |
| RMSE | 1.04 | 1.04 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: DemandSupp_G_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and very small (F(1,
## 833) = 5.99, p = 0.015; Eta2 (partial) = 7.14e-03, 95% CI [7.53e-04, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 833) =
## 6.48, p < .001; Eta2 (partial) = 0.04, 95% CI [0.02, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: DemandSupp_G_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and very small (F(1,
## 828) = 4.18, p = 0.041; Eta2 (partial) = 5.02e-03, 95% CI [1.03e-04, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 828) =
## 2.38, p = 0.037; Eta2 (partial) = 0.01, 95% CI [4.39e-04, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 828) = 0.69, p = 0.628; Eta2 (partial) = 4.17e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: DemandSupp_G_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(DemandSupp_G_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically not significant and very small
## (F(1, 832) = 0.02, p = 0.893; Eta2 (partial) = 2.20e-05, 95% CI [0.00, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 832) =
## 6.58, p < .001; Eta2 (partial) = 0.04, 95% CI [0.02, 1.00])
## - The main effect of scale(Attitude) is statistically significant and very
## small (F(1, 832) = 7.07, p = 0.008; Eta2 (partial) = 8.42e-03, 95% CI
## [1.22e-03, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: DemandSupp_G_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(DemandSupp_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically not significant and very small
## (F(1, 827) = 0.07, p = 0.792; Eta2 (partial) = 8.38e-05, 95% CI [0.00, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 827) =
## 2.30, p = 0.043; Eta2 (partial) = 0.01, 95% CI [2.16e-04, 1.00])
## - The main effect of scale(Attitude) is statistically significant and very
## small (F(1, 827) = 6.41, p = 0.012; Eta2 (partial) = 7.69e-03, 95% CI
## [9.35e-04, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 827) = 0.57, p = 0.723; Eta2 (partial) = 3.44e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = DemandSupp_G_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Support for demands (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Support for demands (G), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'
ggplot(scale_scores, aes(x = Heroism, y = DemandSupp_G_mean, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Support for demands (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Support for demands (G) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'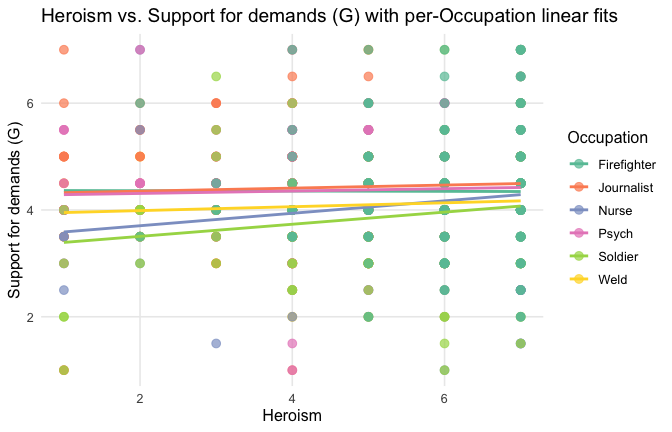
Note that there are two items here: 1) The government, and not the workers, are justified to demand changes ; and 2) the workers, and not the government are justified to demand changes. In this analysis - item 1 was reversed, so that overall score reflects support for workers (rather than government) demanding changes. Nevertheless – as we have seen in the psychometric analyses of the scale: the internal consistency is low, which might be explained by the fact that the two items are not mutually exclusive.
Overall, very small effect sizes for this measure of general support for workers demands - all eta2 < .01. It is not of interest, despite significance. Moreover, effects run in the opposite direction to our predictions, see table:
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(DemandSupp_G_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(DemandSupp_G_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(DemandSupp_G_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(DemandSupp_G_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 5.99 | = 0.015 | 0.007 |
| Occupation | Occupation | 5 | 833 | 6.48 | < .001 | 0.037 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 4.18 | = 0.041 | 0.005 |
| Occupation | Occupation | 5 | 828 | 2.38 | = 0.037 | 0.014 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 0.69 | = 0.628 | 0.004 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 0.02 | = 0.893 | 0.000 |
| Occupation | Occupation | 5 | 832 | 6.58 | < .001 | 0.038 |
| Attitude | Attitude | 1 | 832 | 7.07 | = 0.008 | 0.008 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 0.07 | = 0.792 | 0.000 |
| Occupation | Occupation | 5 | 827 | 2.30 | = 0.043 | 0.014 |
| Attitude | Attitude | 1 | 827 | 6.41 | = 0.012 | 0.008 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 0.57 | = 0.723 | 0.003 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "DemandSupp_G_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(DemandSupp_G_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(DemandSupp_G_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(DemandSupp_G_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(DemandSupp_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | DemandSupp_G_mean | Heroism | 1 | 833 | 5.99 | = 0.015 | 0.007 |
| ~ Heroism * Occupation | DemandSupp_G_mean | Heroism | 1 | 828 | 4.18 | = 0.041 | 0.005 |
| ~ Heroism + Cond + Attitude | DemandSupp_G_mean | Heroism | 1 | 832 | 0.02 | = 0.893 | 0.000 |
| ~ Heroism * Occupation + Attitude | DemandSupp_G_mean | Heroism | 1 | 827 | 0.07 | = 0.792 | 0.000 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
Specific level
Journalists should protest more for the rights they deserve
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(DemandSupp_S_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(DemandSupp_S_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
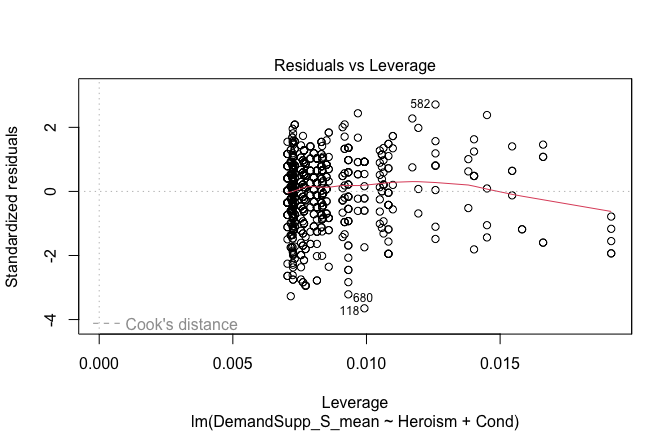
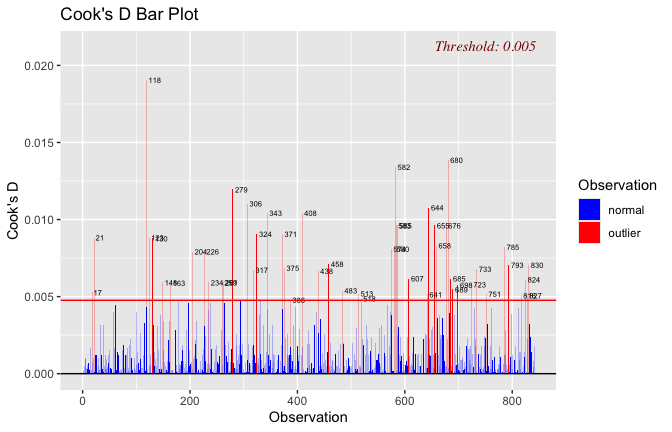
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.044 | 2.948 |
| (0.161) | (0.207) | |
| 18.957 | 14.221 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.354 | 0.393 |
| (0.031) | (0.039) | |
| 11.334 | 10.097 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.206 | −0.250 |
| (0.106) | (0.110) | |
| −1.944 | −2.273 | |
| p = 0.052 | p = 0.023 | |
| Cond2 | 0.156 | 0.164 |
| (0.110) | (0.112) | |
| 1.410 | 1.464 | |
| p = 0.159 | p = 0.144 | |
| Cond3 | 0.126 | 0.088 |
| (0.104) | (0.112) | |
| 1.218 | 0.788 | |
| p = 0.224 | p = 0.431 | |
| Cond4 | −0.030 | −0.067 |
| (0.102) | (0.092) | |
| −0.289 | −0.730 | |
| p = 0.773 | p = 0.466 | |
| Cond5 | −0.309 | −0.195 |
| (0.102) | (0.115) | |
| −3.012 | −1.690 | |
| p = 0.003 | p = 0.091 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.163 | 0.202 |
| R2 Adj. | 0.157 | 0.197 |
| RMSE | 1.31 | 1.32 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(DemandSupp_S_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(DemandSupp_S_mean ~ Heroism * Cond, data = scale_scores)
plot(mod1)
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.933 | 2.798 |
| (0.168) | (0.192) | |
| 17.438 | 14.558 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.372 | 0.413 |
| (0.032) | (0.035) | |
| 11.645 | 11.679 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −1.305 | −1.545 |
| (0.503) | (0.557) | |
| −2.596 | −2.773 | |
| p = 0.010 | p = 0.006 | |
| Cond2 | −0.014 | 0.179 |
| (0.286) | (0.328) | |
| −0.048 | 0.547 | |
| p = 0.961 | p = 0.584 | |
| Cond3 | −0.319 | −0.660 |
| (0.374) | (0.485) | |
| −0.854 | −1.359 | |
| p = 0.394 | p = 0.175 | |
| Cond4 | 0.146 | 0.369 |
| (0.338) | (0.335) | |
| 0.432 | 1.102 | |
| p = 0.666 | p = 0.271 | |
| Cond5 | 0.881 | 1.038 |
| (0.336) | (0.441) | |
| 2.620 | 2.354 | |
| p = 0.009 | p = 0.019 | |
| Heroism × Cond1 | 0.186 | 0.220 |
| (0.084) | (0.089) | |
| 2.200 | 2.472 | |
| p = 0.028 | p = 0.014 | |
| Heroism × Cond2 | 0.061 | 0.018 |
| (0.068) | (0.073) | |
| 0.905 | 0.247 | |
| p = 0.366 | p = 0.805 | |
| Heroism × Cond3 | 0.081 | 0.136 |
| (0.066) | (0.079) | |
| 1.242 | 1.711 | |
| p = 0.214 | p = 0.088 | |
| Heroism × Cond4 | −0.032 | −0.082 |
| (0.070) | (0.068) | |
| −0.457 | −1.210 | |
| p = 0.648 | p = 0.227 | |
| Heroism × Cond5 | −0.230 | −0.231 |
| (0.063) | (0.084) | |
| −3.639 | −2.732 | |
| p = <0.001 | p = 0.006 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.181 | 0.231 |
| R2 Adj. | 0.170 | 0.220 |
| RMSE | 1.30 | 1.31 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)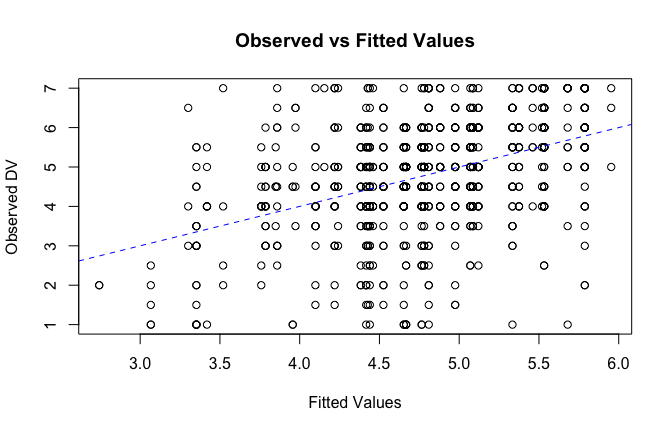
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(DemandSupp_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(DemandSupp_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)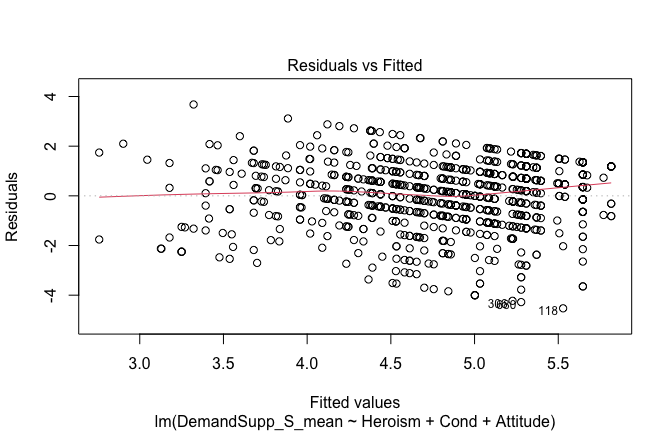
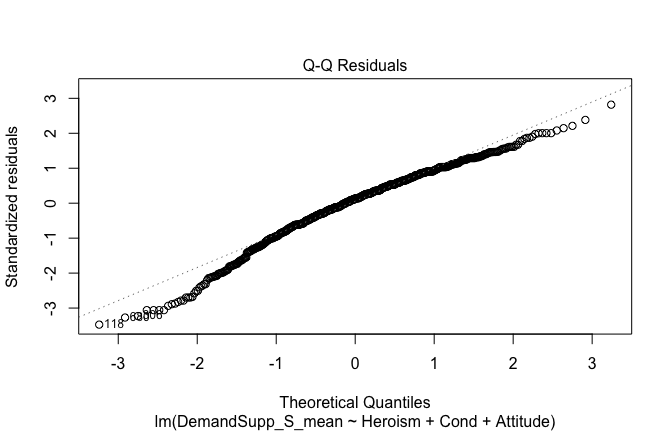
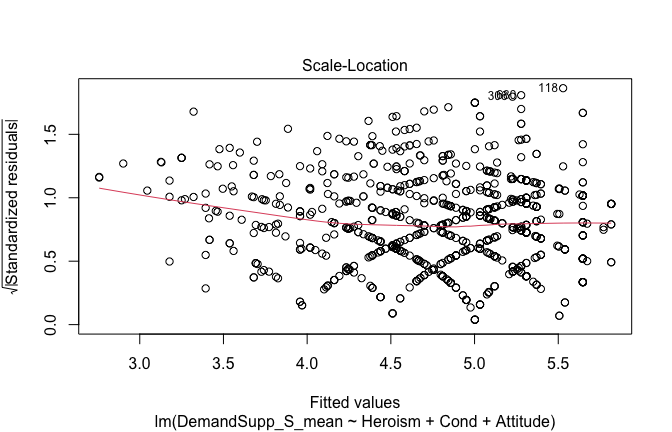
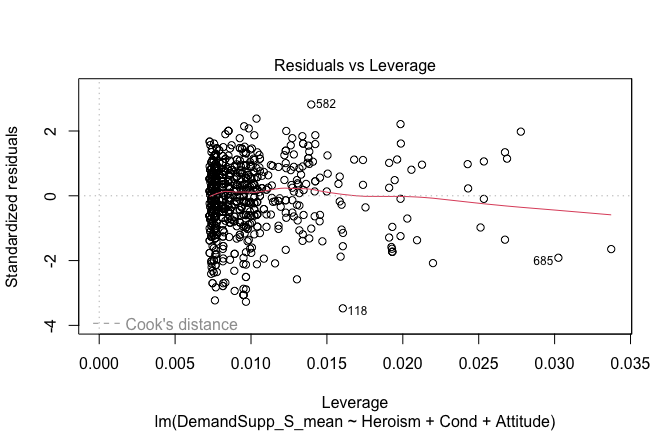
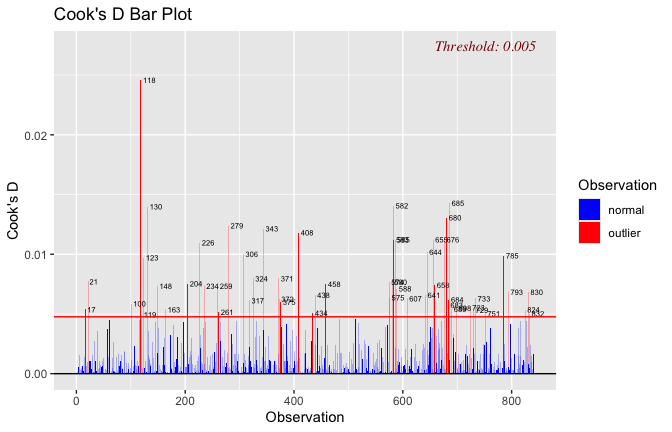
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.429 | 3.469 |
| (0.221) | (0.286) | |
| 15.485 | 12.114 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.276 | 0.289 |
| (0.044) | (0.055) | |
| 6.285 | 5.284 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.246 | −0.291 |
| (0.107) | (0.109) | |
| −2.296 | −2.673 | |
| p = 0.022 | p = 0.008 | |
| Cond2 | 0.216 | 0.223 |
| (0.113) | (0.110) | |
| 1.918 | 2.020 | |
| p = 0.055 | p = 0.044 | |
| Cond3 | 0.092 | 0.043 |
| (0.104) | (0.109) | |
| 0.884 | 0.395 | |
| p = 0.377 | p = 0.693 | |
| Cond4 | −0.048 | −0.095 |
| (0.102) | (0.091) | |
| −0.471 | −1.045 | |
| p = 0.637 | p = 0.296 | |
| Cond5 | −0.276 | −0.130 |
| (0.103) | (0.121) | |
| −2.684 | −1.075 | |
| p = 0.007 | p = 0.282 | |
| Attitude | 0.186 | 0.242 |
| (0.074) | (0.090) | |
| 2.514 | 2.697 | |
| p = 0.012 | p = 0.007 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.169 | 0.215 |
| R2 Adj. | 0.162 | 0.208 |
| RMSE | 1.31 | 1.32 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(DemandSupp_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(DemandSupp_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)
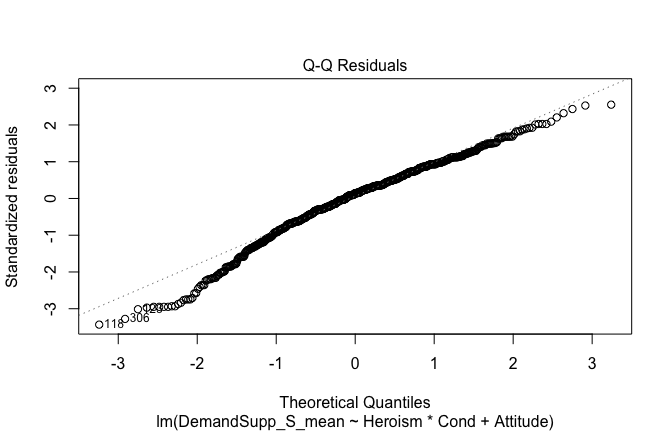
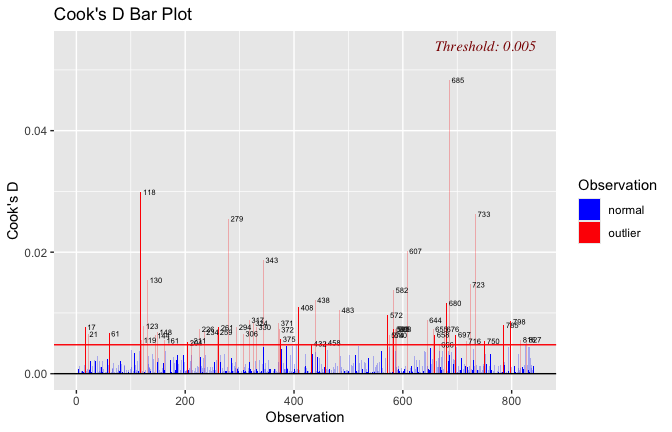
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.391 | 3.421 |
| (0.222) | (0.285) | |
| 15.240 | 12.006 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.277 | 0.288 |
| (0.044) | (0.054) | |
| 6.319 | 5.388 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −1.489 | −1.710 |
| (0.504) | (0.565) | |
| −2.957 | −3.025 | |
| p = 0.003 | p = 0.003 | |
| Cond2 | 0.168 | 0.315 |
| (0.290) | (0.304) | |
| 0.580 | 1.036 | |
| p = 0.562 | p = 0.301 | |
| Cond3 | −0.387 | −0.687 |
| (0.373) | (0.452) | |
| −1.036 | −1.520 | |
| p = 0.300 | p = 0.129 | |
| Cond4 | 0.070 | 0.208 |
| (0.337) | (0.320) | |
| 0.208 | 0.652 | |
| p = 0.835 | p = 0.515 | |
| Cond5 | 1.091 | 1.306 |
| (0.341) | (0.442) | |
| 3.196 | 2.955 | |
| p = 0.001 | p = 0.003 | |
| Attitude | 0.234 | 0.288 |
| (0.075) | (0.088) | |
| 3.122 | 3.285 | |
| p = 0.002 | p = 0.001 | |
| Heroism × Cond1 | 0.209 | 0.240 |
| (0.084) | (0.090) | |
| 2.480 | 2.665 | |
| p = 0.013 | p = 0.008 | |
| Heroism × Cond2 | 0.035 | 0.001 |
| (0.068) | (0.069) | |
| 0.519 | 0.007 | |
| p = 0.604 | p = 0.994 | |
| Heroism × Cond3 | 0.087 | 0.133 |
| (0.065) | (0.075) | |
| 1.330 | 1.784 | |
| p = 0.184 | p = 0.075 | |
| Heroism × Cond4 | −0.018 | −0.054 |
| (0.069) | (0.065) | |
| −0.259 | −0.831 | |
| p = 0.796 | p = 0.406 | |
| Heroism × Cond5 | −0.262 | −0.267 |
| (0.064) | (0.083) | |
| −4.109 | −3.200 | |
| p = <0.001 | p = 0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.191 | 0.244 |
| R2 Adj. | 0.179 | 0.233 |
| RMSE | 1.29 | 1.30 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$DemandSupp_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: DemandSupp_S_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 833)
## = 128.46, p < .001; Eta2 (partial) = 0.13, 95% CI [0.10, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 833) =
## 3.80, p = 0.002; Eta2 (partial) = 0.02, 95% CI [4.98e-03, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: DemandSupp_S_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and large (F(1, 828)
## = 135.61, p < .001; Eta2 (partial) = 0.14, 95% CI [0.11, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 828) =
## 2.66, p = 0.021; Eta2 (partial) = 0.02, 95% CI [1.26e-03, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 828) = 3.63, p = 0.003; Eta2 (partial) = 0.02, 95% CI [4.41e-03,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: DemandSupp_S_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(DemandSupp_S_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 832)
## = 39.50, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 832) =
## 3.94, p = 0.002; Eta2 (partial) = 0.02, 95% CI [5.49e-03, 1.00])
## - The main effect of scale(Attitude) is statistically significant and very
## small (F(1, 832) = 6.32, p = 0.012; Eta2 (partial) = 7.54e-03, 95% CI
## [8.91e-04, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: DemandSupp_S_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(DemandSupp_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 827)
## = 39.92, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 827) =
## 3.42, p = 0.005; Eta2 (partial) = 0.02, 95% CI [3.70e-03, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 827) = 9.75, p = 0.002; Eta2 (partial) = 0.01, 95% CI [2.61e-03, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 827) = 4.33, p < .001; Eta2 (partial) = 0.03, 95% CI [6.93e-03,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = DemandSupp_S_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Support for demands (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Support for demands (S), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'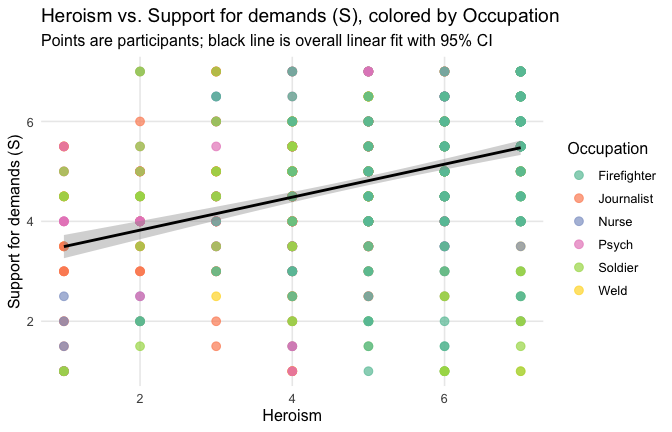
ggplot(scale_scores, aes(y = DemandSupp_S_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Support for demands (S) ",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Support for demands (S) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'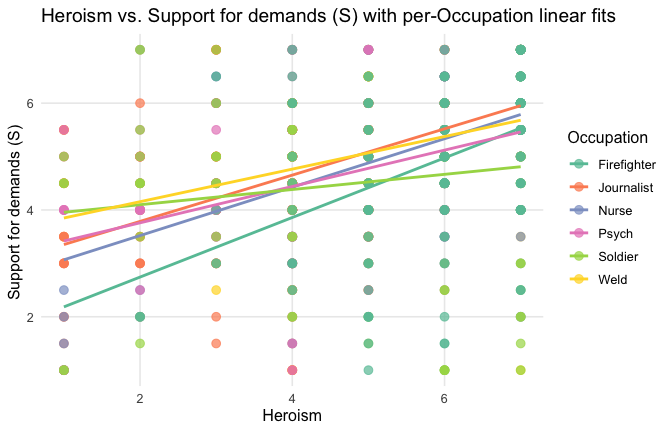
==> No support for our hypotheses. Across all occupations Heroism predicted SUPPORT for general- and specific-level workers’ demands, with or without controlling for attitude. Although effects were drastically reduced when accounting for attitude, heroism might increase our support for workers’ demands. Our hypotheses should therefore be revised.
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(DemandSupp_S_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(DemandSupp_S_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(DemandSupp_S_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(DemandSupp_S_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 128.46 | < .001 | 0.134 |
| Occupation | Occupation | 5 | 833 | 3.80 | = 0.002 | 0.022 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 135.61 | < .001 | 0.141 |
| Occupation | Occupation | 5 | 828 | 2.66 | = 0.021 | 0.016 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 3.63 | = 0.003 | 0.021 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 39.50 | < .001 | 0.045 |
| Occupation | Occupation | 5 | 832 | 3.94 | = 0.002 | 0.023 |
| Attitude | Attitude | 1 | 832 | 6.32 | = 0.012 | 0.008 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 39.92 | < .001 | 0.046 |
| Occupation | Occupation | 5 | 827 | 3.42 | = 0.005 | 0.020 |
| Attitude | Attitude | 1 | 827 | 9.75 | = 0.002 | 0.012 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 4.33 | < .001 | 0.026 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "DemandSupp_S_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(DemandSupp_S_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(DemandSupp_S_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(DemandSupp_S_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(DemandSupp_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | DemandSupp_S_mean | Heroism | 1 | 833 | 128.46 | < .001 | 0.134 |
| ~ Heroism * Occupation | DemandSupp_S_mean | Heroism | 1 | 828 | 135.61 | < .001 | 0.141 |
| ~ Heroism + Cond + Attitude | DemandSupp_S_mean | Heroism | 1 | 832 | 39.50 | < .001 | 0.045 |
| ~ Heroism * Occupation + Attitude | DemandSupp_S_mean | Heroism | 1 | 827 | 39.92 | < .001 | 0.046 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
H4: Heroism is associated with decreased perception of victim-hood
The heroic status might be incompatible with the victim status (see Hartman et al., 2022) - heroes are agentic, whereas victims are passive. Heroes are there to defend us - and we might overestimate their resilience to hardship and downplay their vulnerability and suffering. At the general level, it means that we might report heroes to be less victimised, unfairly treated, exploited. At the specific level, it means we should indicate that, upon reading that 60% of the workers report intense migraines, we would feel that workers are strong enough to endure it.
General level
[How much do you see journalists as:] Victimised
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(Victim_G_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(Victim_G_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 1.504 | 1.433 |
| (0.158) | (0.152) | |
| 9.501 | 9.418 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.300 | 0.309 |
| (0.031) | (0.032) | |
| 9.719 | 9.711 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.623 | −0.667 |
| (0.105) | (0.117) | |
| −5.952 | −5.725 | |
| p = <0.001 | p = <0.001 | |
| Cond2 | 0.021 | 0.041 |
| (0.109) | (0.097) | |
| 0.190 | 0.426 | |
| p = 0.849 | p = 0.670 | |
| Cond3 | 0.929 | 0.996 |
| (0.102) | (0.122) | |
| 9.081 | 8.173 | |
| p = <0.001 | p = <0.001 | |
| Cond4 | −0.489 | −0.496 |
| (0.101) | (0.096) | |
| −4.851 | −5.156 | |
| p = <0.001 | p = <0.001 | |
| Cond5 | 0.266 | 0.267 |
| (0.101) | (0.115) | |
| 2.637 | 2.316 | |
| p = 0.009 | p = 0.021 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.241 | 0.251 |
| R2 Adj. | 0.236 | 0.246 |
| RMSE | 1.29 | 1.30 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(Victim_G_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(Victim_G_mean ~ Heroism * Cond, data = scale_scores)
plot(mod1)
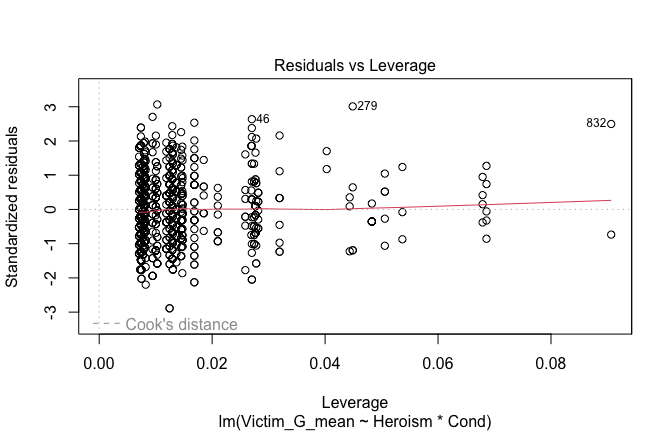
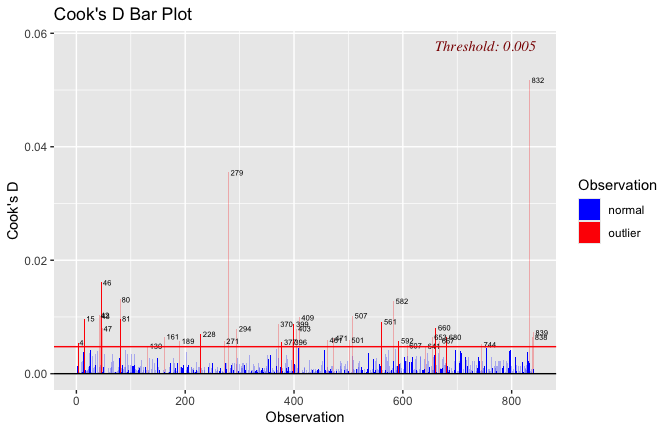
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 1.528 | 1.440 |
| (0.167) | (0.176) | |
| 9.159 | 8.166 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.294 | 0.304 |
| (0.032) | (0.034) | |
| 9.281 | 8.850 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.000 | −0.119 |
| (0.499) | (0.586) | |
| −0.001 | −0.203 | |
| p = 0.999 | p = 0.840 | |
| Cond2 | 0.069 | 0.108 |
| (0.284) | (0.235) | |
| 0.244 | 0.459 | |
| p = 0.808 | p = 0.646 | |
| Cond3 | 0.102 | −0.069 |
| (0.371) | (0.411) | |
| 0.275 | −0.169 | |
| p = 0.784 | p = 0.866 | |
| Cond4 | −0.342 | −0.277 |
| (0.335) | (0.263) | |
| −1.020 | −1.053 | |
| p = 0.308 | p = 0.292 | |
| Cond5 | 0.581 | 0.614 |
| (0.334) | (0.343) | |
| 1.741 | 1.789 | |
| p = 0.082 | p = 0.074 | |
| Heroism × Cond1 | −0.103 | −0.089 |
| (0.084) | (0.101) | |
| −1.231 | −0.884 | |
| p = 0.219 | p = 0.377 | |
| Heroism × Cond2 | −0.015 | −0.017 |
| (0.067) | (0.056) | |
| −0.222 | −0.295 | |
| p = 0.824 | p = 0.768 | |
| Heroism × Cond3 | 0.148 | 0.192 |
| (0.065) | (0.072) | |
| 2.279 | 2.682 | |
| p = 0.023 | p = 0.007 | |
| Heroism × Cond4 | −0.033 | −0.047 |
| (0.069) | (0.061) | |
| −0.472 | −0.778 | |
| p = 0.637 | p = 0.437 | |
| Heroism × Cond5 | −0.061 | −0.067 |
| (0.063) | (0.069) | |
| −0.978 | −0.967 | |
| p = 0.329 | p = 0.334 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.248 | 0.261 |
| R2 Adj. | 0.238 | 0.251 |
| RMSE | 1.29 | 1.29 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Victim_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Victim_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)
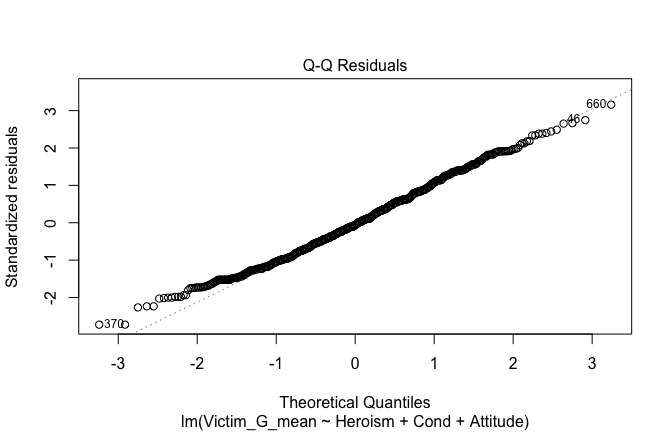
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 1.660 | 1.605 |
| (0.219) | (0.209) | |
| 7.580 | 7.668 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.268 | 0.274 |
| (0.043) | (0.043) | |
| 6.163 | 6.415 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.638 | −0.686 |
| (0.106) | (0.119) | |
| −6.038 | −5.747 | |
| p = <0.001 | p = <0.001 | |
| Cond2 | 0.045 | 0.068 |
| (0.111) | (0.099) | |
| 0.405 | 0.689 | |
| p = 0.685 | p = 0.491 | |
| Cond3 | 0.916 | 0.985 |
| (0.103) | (0.121) | |
| 8.870 | 8.106 | |
| p = <0.001 | p = <0.001 | |
| Cond4 | −0.497 | −0.506 |
| (0.101) | (0.097) | |
| −4.913 | −5.224 | |
| p = <0.001 | p = <0.001 | |
| Cond5 | 0.279 | 0.282 |
| (0.102) | (0.117) | |
| 2.745 | 2.415 | |
| p = 0.006 | p = 0.016 | |
| Attitude | 0.075 | 0.082 |
| (0.073) | (0.068) | |
| 1.029 | 1.207 | |
| p = 0.304 | p = 0.228 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.242 | 0.253 |
| R2 Adj. | 0.236 | 0.247 |
| RMSE | 1.29 | 1.29 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Victim_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Victim_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)
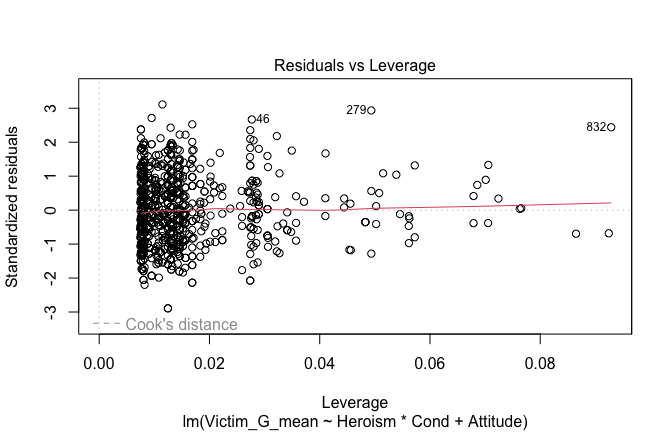
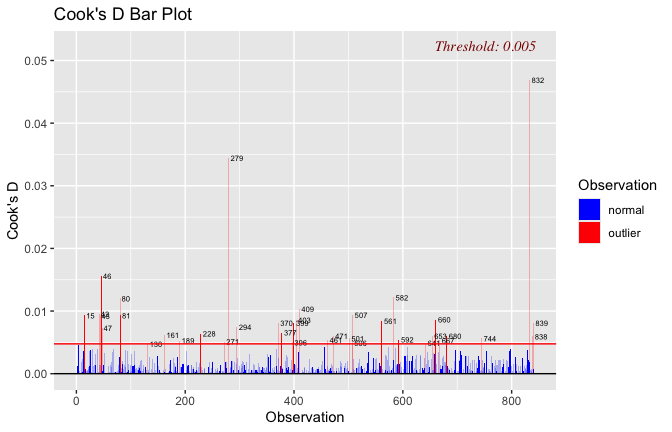
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 1.706 | 1.621 |
| (0.222) | (0.225) | |
| 7.688 | 7.194 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.258 | 0.267 |
| (0.044) | (0.044) | |
| 5.882 | 6.080 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.072 | −0.180 |
| (0.502) | (0.585) | |
| −0.142 | −0.307 | |
| p = 0.887 | p = 0.759 | |
| Cond2 | 0.140 | 0.176 |
| (0.290) | (0.238) | |
| 0.482 | 0.739 | |
| p = 0.630 | p = 0.460 | |
| Cond3 | 0.076 | −0.076 |
| (0.372) | (0.405) | |
| 0.204 | −0.189 | |
| p = 0.838 | p = 0.850 | |
| Cond4 | −0.371 | −0.312 |
| (0.336) | (0.265) | |
| −1.105 | −1.180 | |
| p = 0.269 | p = 0.238 | |
| Cond5 | 0.662 | 0.684 |
| (0.340) | (0.336) | |
| 1.946 | 2.035 | |
| p = 0.052 | p = 0.042 | |
| Attitude | 0.090 | 0.090 |
| (0.075) | (0.067) | |
| 1.213 | 1.347 | |
| p = 0.226 | p = 0.178 | |
| Heroism × Cond1 | −0.094 | −0.083 |
| (0.084) | (0.101) | |
| −1.119 | −0.818 | |
| p = 0.263 | p = 0.413 | |
| Heroism × Cond2 | −0.025 | −0.026 |
| (0.068) | (0.056) | |
| −0.369 | −0.470 | |
| p = 0.712 | p = 0.639 | |
| Heroism × Cond3 | 0.150 | 0.192 |
| (0.065) | (0.071) | |
| 2.310 | 2.697 | |
| p = 0.021 | p = 0.007 | |
| Heroism × Cond4 | −0.027 | −0.041 |
| (0.069) | (0.061) | |
| −0.394 | −0.671 | |
| p = 0.694 | p = 0.502 | |
| Heroism × Cond5 | −0.074 | −0.077 |
| (0.063) | (0.068) | |
| −1.159 | −1.135 | |
| p = 0.247 | p = 0.257 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.249 | 0.263 |
| R2 Adj. | 0.238 | 0.253 |
| RMSE | 1.29 | 1.29 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)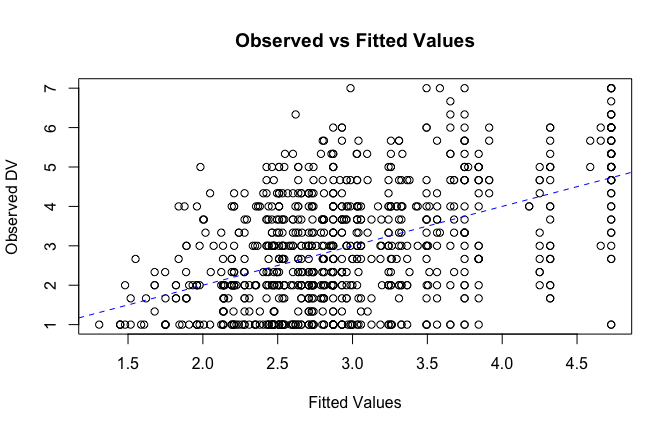
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: Victim_G_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 833)
## = 94.47, p < .001; Eta2 (partial) = 0.10, 95% CI [0.07, 1.00])
## - The main effect of Cond is statistically significant and medium (F(5, 833) =
## 26.21, p < .001; Eta2 (partial) = 0.14, 95% CI [0.10, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: Victim_G_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 828)
## = 86.13, p < .001; Eta2 (partial) = 0.09, 95% CI [0.07, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 828) = 0.94, p = 0.457; Eta2 (partial) = 5.61e-03, 95% CI [0.00, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 828) = 1.47, p = 0.197; Eta2 (partial) = 8.81e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: Victim_G_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(Victim_G_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 832)
## = 37.98, p < .001; Eta2 (partial) = 0.04, 95% CI [0.02, 1.00])
## - The main effect of Cond is statistically significant and medium (F(5, 832) =
## 26.36, p < .001; Eta2 (partial) = 0.14, 95% CI [0.10, 1.00])
## - The main effect of scale(Attitude) is statistically not significant and very
## small (F(1, 832) = 1.06, p = 0.304; Eta2 (partial) = 1.27e-03, 95% CI [0.00,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: Victim_G_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(Victim_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 827)
## = 34.60, p < .001; Eta2 (partial) = 0.04, 95% CI [0.02, 1.00])
## - The main effect of Cond is statistically not significant and very small (F(5,
## 827) = 1.12, p = 0.347; Eta2 (partial) = 6.74e-03, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically not significant and very
## small (F(1, 827) = 1.47, p = 0.226; Eta2 (partial) = 1.78e-03, 95% CI [0.00,
## 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 827) = 1.55, p = 0.171; Eta2 (partial) = 9.31e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = Victim_G_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Victimisation (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Victimisation (G), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'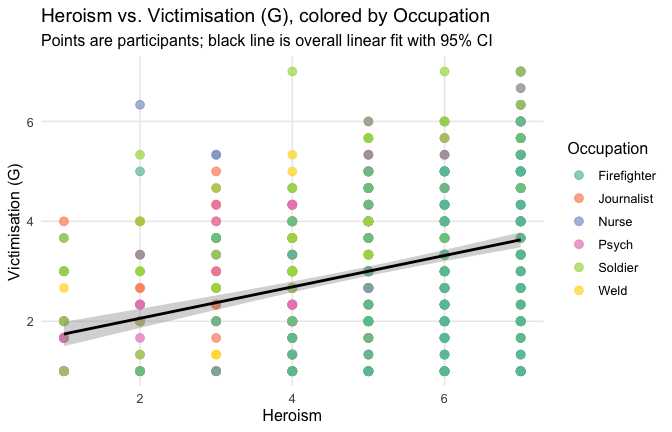
ggplot(scale_scores, aes(y = Victim_G_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Victimisation (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Victimisation (G) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'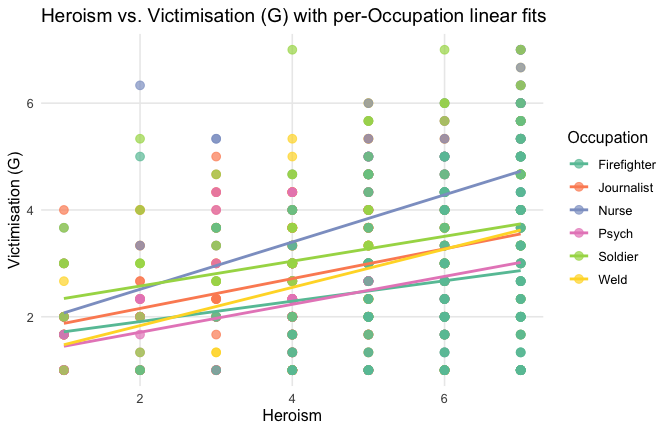
A significant, yet small effect, in the opposite direction.
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(Victim_G_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(Victim_G_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(Victim_G_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(Victim_G_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 94.47 | < .001 | 0.102 |
| Occupation | Occupation | 5 | 833 | 26.21 | < .001 | 0.136 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 86.13 | < .001 | 0.094 |
| Occupation | Occupation | 5 | 828 | 0.94 | = 0.457 | 0.006 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 1.47 | = 0.197 | 0.009 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 37.98 | < .001 | 0.044 |
| Occupation | Occupation | 5 | 832 | 26.36 | < .001 | 0.137 |
| Attitude | Attitude | 1 | 832 | 1.06 | = 0.304 | 0.001 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 34.60 | < .001 | 0.040 |
| Occupation | Occupation | 5 | 827 | 1.12 | = 0.347 | 0.007 |
| Attitude | Attitude | 1 | 827 | 1.47 | = 0.226 | 0.002 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 1.55 | = 0.171 | 0.009 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "Victim_G_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(Victim_G_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(Victim_G_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(Victim_G_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(Victim_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Occupation"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Occupation + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Occupation | Victim_G_mean | Heroism | 1 | 833 | 94.47 | < .001 | 0.102 |
| ~ Heroism * Occupation | Victim_G_mean | Heroism | 1 | 828 | 86.13 | < .001 | 0.094 |
| ~ Heroism + Occupation + Attitude | Victim_G_mean | Heroism | 1 | 832 | 37.98 | < .001 | 0.044 |
| ~ Heroism * Occupation + Attitude | Victim_G_mean | Heroism | 1 | 827 | 34.60 | < .001 | 0.040 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
Specific level
[Consider the following observation from a recent report: In their professional life, more than 60% of journalists have reported intense migraines from working long hours. How much would you agree or disagree with the following statements:] I believe journalists are strong enough to face this condition
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(Victim_S_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(Victim_S_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
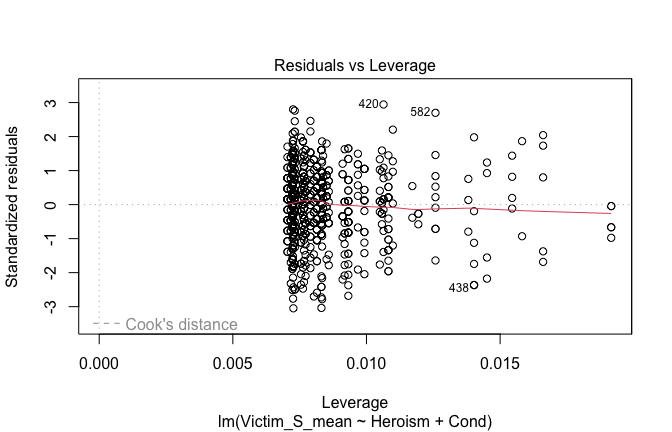
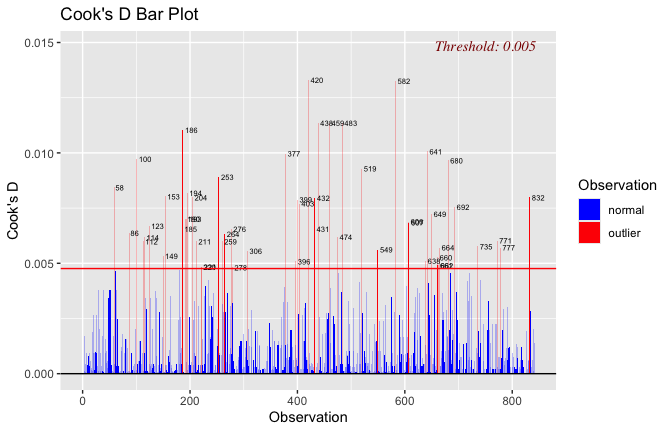
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.376 | 3.322 |
| (0.132) | (0.162) | |
| 25.614 | 20.518 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.291 | 0.309 |
| (0.026) | (0.030) | |
| 11.342 | 10.185 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.040 | 0.016 |
| (0.087) | (0.081) | |
| 0.462 | 0.194 | |
| p = 0.644 | p = 0.846 | |
| Cond2 | −0.559 | −0.515 |
| (0.091) | (0.107) | |
| −6.167 | −4.820 | |
| p = <0.001 | p = <0.001 | |
| Cond3 | 0.380 | 0.361 |
| (0.085) | (0.079) | |
| 4.462 | 4.572 | |
| p = <0.001 | p = <0.001 | |
| Cond4 | −0.126 | −0.115 |
| (0.084) | (0.080) | |
| −1.499 | −1.432 | |
| p = 0.134 | p = 0.153 | |
| Cond5 | −0.192 | −0.230 |
| (0.084) | (0.098) | |
| −2.287 | −2.357 | |
| p = 0.022 | p = 0.019 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.280 | 0.300 |
| R2 Adj. | 0.275 | 0.295 |
| RMSE | 1.08 | 1.08 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(Victim_S_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(Victim_S_mean ~ Heroism * Cond, data = scale_scores)
plot(mod1)
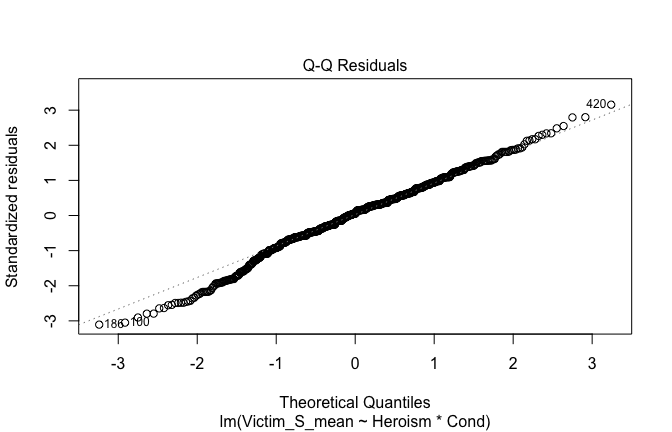
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.299 | 3.249 |
| (0.138) | (0.158) | |
| 23.834 | 20.595 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.304 | 0.321 |
| (0.026) | (0.029) | |
| 11.546 | 11.038 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.809 | −0.964 |
| (0.414) | (0.426) | |
| −1.955 | −2.261 | |
| p = 0.051 | p = 0.024 | |
| Cond2 | −0.606 | −0.623 |
| (0.235) | (0.257) | |
| −2.577 | −2.427 | |
| p = 0.010 | p = 0.015 | |
| Cond3 | 0.306 | 0.323 |
| (0.308) | (0.328) | |
| 0.993 | 0.985 | |
| p = 0.321 | p = 0.325 | |
| Cond4 | −0.377 | −0.410 |
| (0.278) | (0.379) | |
| −1.357 | −1.082 | |
| p = 0.175 | p = 0.280 | |
| Cond5 | 0.577 | 0.702 |
| (0.277) | (0.402) | |
| 2.085 | 1.745 | |
| p = 0.037 | p = 0.081 | |
| Heroism × Cond1 | 0.143 | 0.162 |
| (0.070) | (0.070) | |
| 2.058 | 2.329 | |
| p = 0.040 | p = 0.020 | |
| Heroism × Cond2 | 0.022 | 0.039 |
| (0.056) | (0.060) | |
| 0.401 | 0.658 | |
| p = 0.688 | p = 0.511 | |
| Heroism × Cond3 | 0.014 | 0.007 |
| (0.054) | (0.055) | |
| 0.264 | 0.128 | |
| p = 0.792 | p = 0.898 | |
| Heroism × Cond4 | 0.060 | 0.066 |
| (0.057) | (0.074) | |
| 1.050 | 0.892 | |
| p = 0.294 | p = 0.373 | |
| Heroism × Cond5 | −0.149 | −0.177 |
| (0.052) | (0.072) | |
| −2.866 | −2.463 | |
| p = 0.004 | p = 0.014 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.292 | 0.314 |
| R2 Adj. | 0.282 | 0.305 |
| RMSE | 1.07 | 1.07 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Victim_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Victim_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)
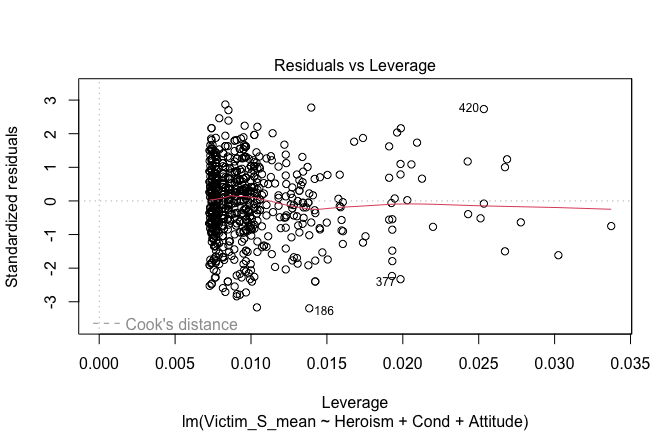
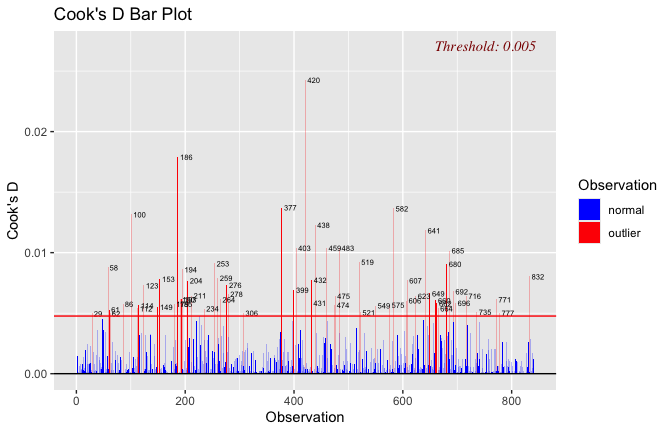
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.619 | 3.659 |
| (0.182) | (0.217) | |
| 19.883 | 16.894 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.242 | 0.241 |
| (0.036) | (0.042) | |
| 6.688 | 5.771 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.015 | −0.020 |
| (0.088) | (0.081) | |
| 0.176 | −0.248 | |
| p = 0.860 | p = 0.804 | |
| Cond2 | −0.520 | −0.459 |
| (0.093) | (0.110) | |
| −5.624 | −4.162 | |
| p = <0.001 | p = <0.001 | |
| Cond3 | 0.359 | 0.329 |
| (0.086) | (0.078) | |
| 4.180 | 4.234 | |
| p = <0.001 | p = <0.001 | |
| Cond4 | −0.138 | −0.125 |
| (0.084) | (0.080) | |
| −1.638 | −1.568 | |
| p = 0.102 | p = 0.117 | |
| Cond5 | −0.172 | −0.212 |
| (0.085) | (0.100) | |
| −2.032 | −2.108 | |
| p = 0.043 | p = 0.035 | |
| Attitude | 0.117 | 0.164 |
| (0.061) | (0.072) | |
| 1.933 | 2.274 | |
| p = 0.054 | p = 0.023 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.284 | 0.309 |
| R2 Adj. | 0.278 | 0.304 |
| RMSE | 1.08 | 1.08 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Victim_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Victim_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)
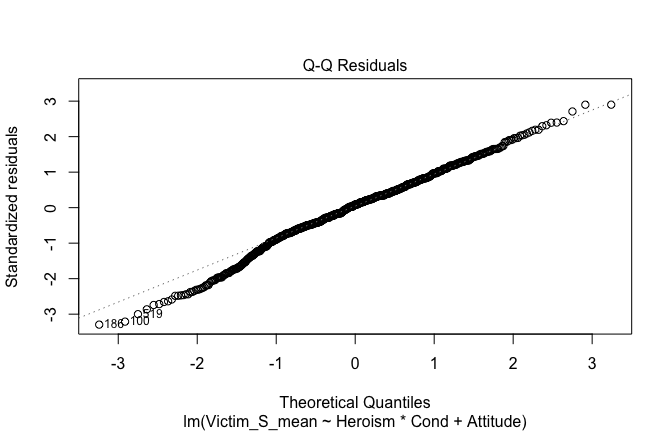
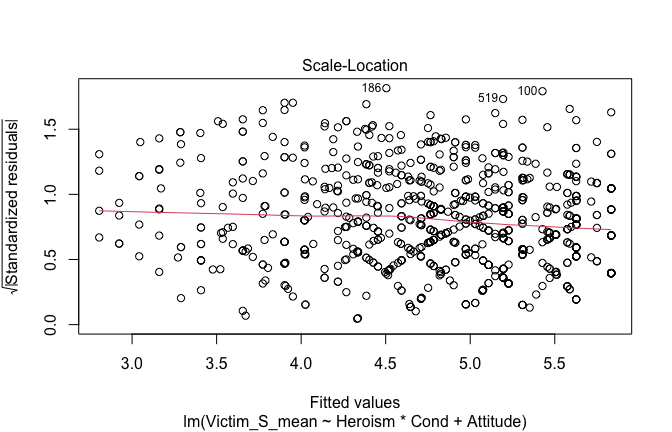
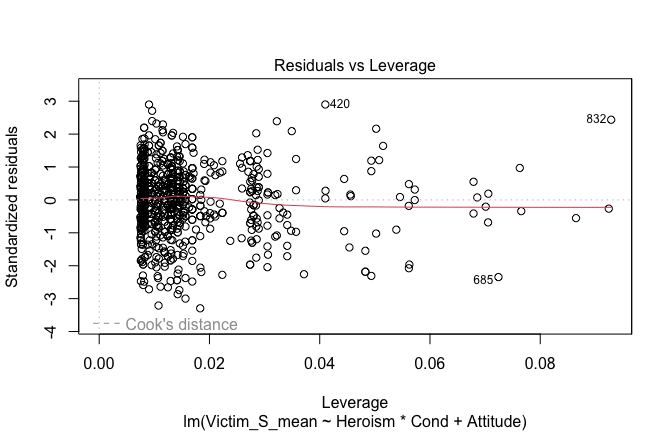
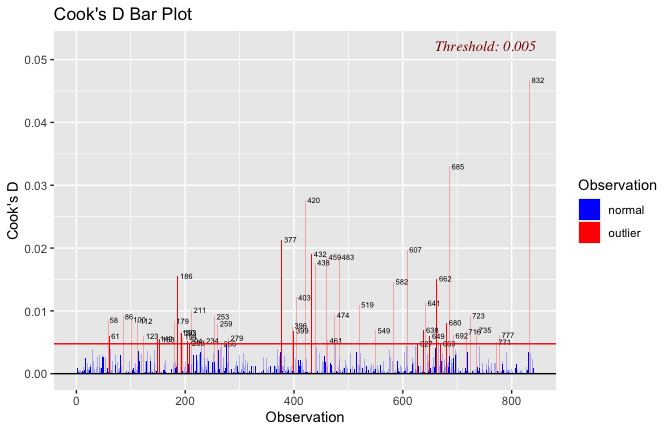
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.599 | 3.655 |
| (0.184) | (0.225) | |
| 19.611 | 16.249 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.242 | 0.239 |
| (0.036) | (0.043) | |
| 6.674 | 5.585 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.929 | −1.108 |
| (0.415) | (0.418) | |
| −2.237 | −2.649 | |
| p = 0.026 | p = 0.008 | |
| Cond2 | −0.487 | −0.506 |
| (0.239) | (0.252) | |
| −2.035 | −2.010 | |
| p = 0.042 | p = 0.045 | |
| Cond3 | 0.262 | 0.294 |
| (0.308) | (0.302) | |
| 0.852 | 0.974 | |
| p = 0.395 | p = 0.330 | |
| Cond4 | −0.426 | −0.463 |
| (0.278) | (0.375) | |
| −1.536 | −1.235 | |
| p = 0.125 | p = 0.217 | |
| Cond5 | 0.715 | 0.892 |
| (0.282) | (0.431) | |
| 2.538 | 2.069 | |
| p = 0.011 | p = 0.039 | |
| Attitude | 0.153 | 0.197 |
| (0.062) | (0.071) | |
| 2.476 | 2.778 | |
| p = 0.013 | p = 0.006 | |
| Heroism × Cond1 | 0.158 | 0.180 |
| (0.070) | (0.068) | |
| 2.276 | 2.631 | |
| p = 0.023 | p = 0.009 | |
| Heroism × Cond2 | 0.005 | 0.026 |
| (0.056) | (0.059) | |
| 0.095 | 0.435 | |
| p = 0.924 | p = 0.664 | |
| Heroism × Cond3 | 0.018 | 0.006 |
| (0.054) | (0.051) | |
| 0.329 | 0.118 | |
| p = 0.742 | p = 0.906 | |
| Heroism × Cond4 | 0.069 | 0.076 |
| (0.057) | (0.074) | |
| 1.209 | 1.029 | |
| p = 0.227 | p = 0.304 | |
| Heroism × Cond5 | −0.170 | −0.206 |
| (0.053) | (0.076) | |
| −3.233 | −2.727 | |
| p = 0.001 | p = 0.007 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.297 | 0.324 |
| R2 Adj. | 0.287 | 0.314 |
| RMSE | 1.07 | 1.07 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Victim_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: Victim_S_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 833)
## = 128.64, p < .001; Eta2 (partial) = 0.13, 95% CI [0.10, 1.00])
## - The main effect of Cond is statistically significant and medium (F(5, 833) =
## 15.52, p < .001; Eta2 (partial) = 0.09, 95% CI [0.05, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: Victim_S_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 828)
## = 133.32, p < .001; Eta2 (partial) = 0.14, 95% CI [0.10, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 828) =
## 4.55, p < .001; Eta2 (partial) = 0.03, 95% CI [7.74e-03, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 828) = 2.65, p = 0.022; Eta2 (partial) = 0.02, 95% CI [1.21e-03,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: Victim_S_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(Victim_S_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 832)
## = 44.73, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically significant and medium (F(5, 832) =
## 13.87, p < .001; Eta2 (partial) = 0.08, 95% CI [0.05, 1.00])
## - The main effect of scale(Attitude) is statistically not significant and very
## small (F(1, 832) = 3.74, p = 0.054; Eta2 (partial) = 4.47e-03, 95% CI [0.00,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: Victim_S_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(Victim_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 827)
## = 44.54, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 827) =
## 4.62, p < .001; Eta2 (partial) = 0.03, 95% CI [8.02e-03, 1.00])
## - The main effect of scale(Attitude) is statistically significant and very
## small (F(1, 827) = 6.13, p = 0.013; Eta2 (partial) = 7.36e-03, 95% CI
## [8.18e-04, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 827) = 3.14, p = 0.008; Eta2 (partial) = 0.02, 95% CI [2.74e-03,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = Victim_S_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Victimisation (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Victimisation (S), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'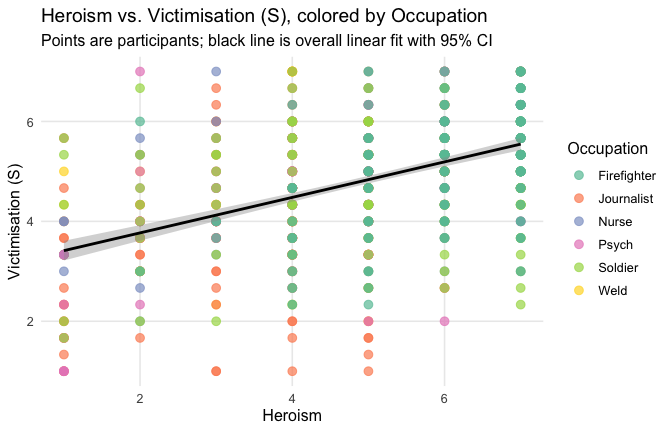
ggplot(scale_scores, aes(y = Victim_S_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Victimisation (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Victimisation (S) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'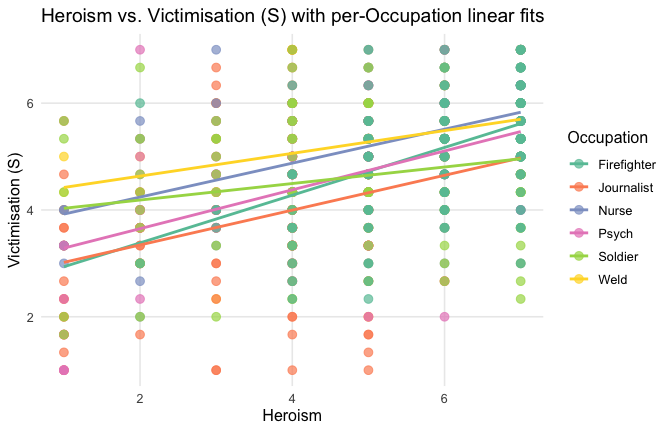
==> No support for our hypotheses. Across all occupations Heroism predicted POSITIVE general- and specific-level workers’ victimization, with or without controlling for attitude. Although effects were drastically reduced when accounting for attitude, heroism might increase our perception that workers need help and support, and suffer and are exploited. Our hypotheses should therefore be revised.
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(Victim_S_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(Victim_S_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(Victim_S_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(Victim_S_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 128.64 | < .001 | 0.134 |
| Occupation | Occupation | 5 | 833 | 15.52 | < .001 | 0.085 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 133.32 | < .001 | 0.139 |
| Occupation | Occupation | 5 | 828 | 4.55 | < .001 | 0.027 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 2.65 | = 0.022 | 0.016 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 44.73 | < .001 | 0.051 |
| Occupation | Occupation | 5 | 832 | 13.87 | < .001 | 0.077 |
| Attitude | Attitude | 1 | 832 | 3.74 | = 0.054 | 0.004 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 44.54 | < .001 | 0.051 |
| Occupation | Occupation | 5 | 827 | 4.62 | < .001 | 0.027 |
| Attitude | Attitude | 1 | 827 | 6.13 | = 0.013 | 0.007 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 3.14 | = 0.008 | 0.019 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "Victim_S_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(Victim_S_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(Victim_S_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(Victim_S_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(Victim_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | Victim_S_mean | Heroism | 1 | 833 | 128.64 | < .001 | 0.134 |
| ~ Heroism * Occupation | Victim_S_mean | Heroism | 1 | 828 | 133.32 | < .001 | 0.139 |
| ~ Heroism + Cond + Attitude | Victim_S_mean | Heroism | 1 | 832 | 44.73 | < .001 | 0.051 |
| ~ Heroism * Occupation + Attitude | Victim_S_mean | Heroism | 1 | 827 | 44.54 | < .001 | 0.051 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
H5: Heroism is associated to greater impunity
Because Heroic status might also be incompatible with the villain status (Hartman et al., 2022), we should grant greater impunity to heroes, perceived as moral instances. At the general level, it means that we would support de-regulating the occupations. At the specific level, it means that in the context of a moral dilemma contrasting respecting the rules vs doing one’s job, we would be in favour of protecting rule-breaking heroes.
General level
Journalists should be given more freedom in the way they do their work
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(Villain_G_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(Villain_G_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.184 | 2.106 |
| (0.159) | (0.160) | |
| 13.762 | 13.178 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.340 | 0.360 |
| (0.031) | (0.032) | |
| 11.001 | 11.292 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.331 | 0.369 |
| (0.105) | (0.111) | |
| 3.155 | 3.331 | |
| p = 0.002 | p = <0.001 | |
| Cond2 | −0.024 | −0.033 |
| (0.109) | (0.109) | |
| −0.220 | −0.305 | |
| p = 0.826 | p = 0.761 | |
| Cond3 | −0.181 | −0.179 |
| (0.103) | (0.108) | |
| −1.763 | −1.650 | |
| p = 0.078 | p = 0.099 | |
| Cond4 | −0.046 | −0.034 |
| (0.101) | (0.104) | |
| −0.453 | −0.330 | |
| p = 0.651 | p = 0.741 | |
| Cond5 | −0.227 | −0.272 |
| (0.101) | (0.115) | |
| −2.243 | −2.369 | |
| p = 0.025 | p = 0.018 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.183 | 0.202 |
| R2 Adj. | 0.177 | 0.197 |
| RMSE | 1.30 | 1.30 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)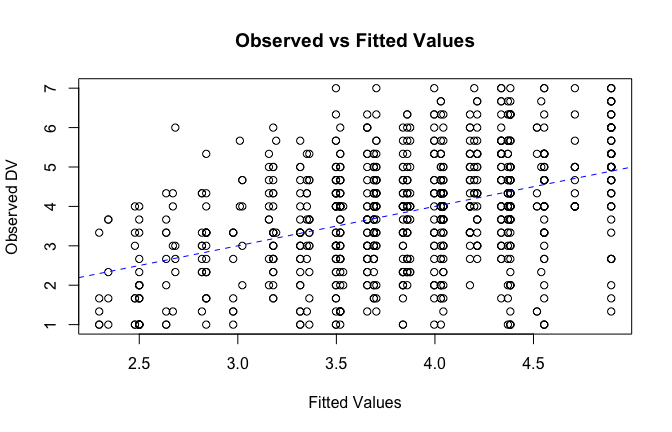
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(Villain_G_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(Villain_G_mean ~ Heroism * Cond, data = scale_scores)
plot(mod1)
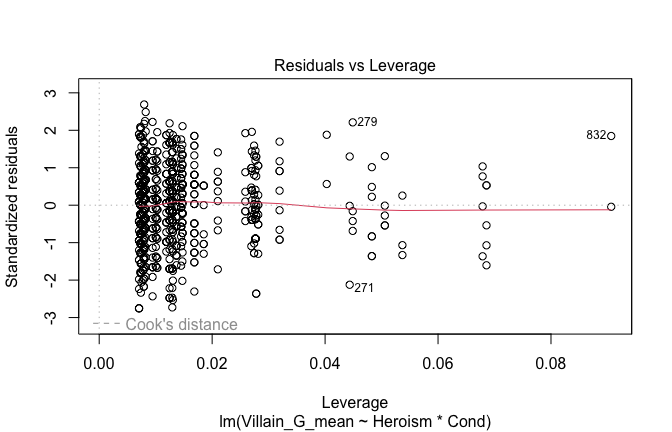
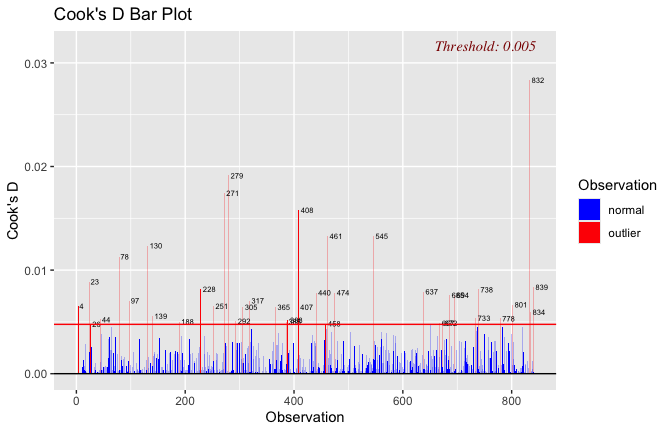
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.284 | 2.194 |
| (0.166) | (0.169) | |
| 13.723 | 12.998 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.329 | 0.351 |
| (0.032) | (0.032) | |
| 10.408 | 10.897 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.518 | 0.372 |
| (0.498) | (0.544) | |
| 1.042 | 0.685 | |
| p = 0.298 | p = 0.494 | |
| Cond2 | −0.622 | −0.602 |
| (0.283) | (0.259) | |
| −2.199 | −2.323 | |
| p = 0.028 | p = 0.020 | |
| Cond3 | 0.524 | 0.507 |
| (0.370) | (0.379) | |
| 1.415 | 1.337 | |
| p = 0.157 | p = 0.182 | |
| Cond4 | 0.161 | 0.169 |
| (0.334) | (0.335) | |
| 0.483 | 0.504 | |
| p = 0.629 | p = 0.614 | |
| Cond5 | −1.093 | −1.069 |
| (0.333) | (0.323) | |
| −3.283 | −3.313 | |
| p = 0.001 | p = <0.001 | |
| Heroism × Cond1 | −0.037 | −0.006 |
| (0.084) | (0.091) | |
| −0.448 | −0.061 | |
| p = 0.654 | p = 0.951 | |
| Heroism × Cond2 | 0.151 | 0.147 |
| (0.067) | (0.064) | |
| 2.247 | 2.294 | |
| p = 0.025 | p = 0.022 | |
| Heroism × Cond3 | −0.132 | −0.129 |
| (0.065) | (0.068) | |
| −2.038 | −1.903 | |
| p = 0.042 | p = 0.057 | |
| Heroism × Cond4 | −0.057 | −0.056 |
| (0.069) | (0.069) | |
| −0.833 | −0.802 | |
| p = 0.405 | p = 0.423 | |
| Heroism × Cond5 | 0.162 | 0.151 |
| (0.063) | (0.064) | |
| 2.585 | 2.374 | |
| p = 0.010 | p = 0.018 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.198 | 0.218 |
| R2 Adj. | 0.187 | 0.207 |
| RMSE | 1.29 | 1.29 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Villain_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Villain_G_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)
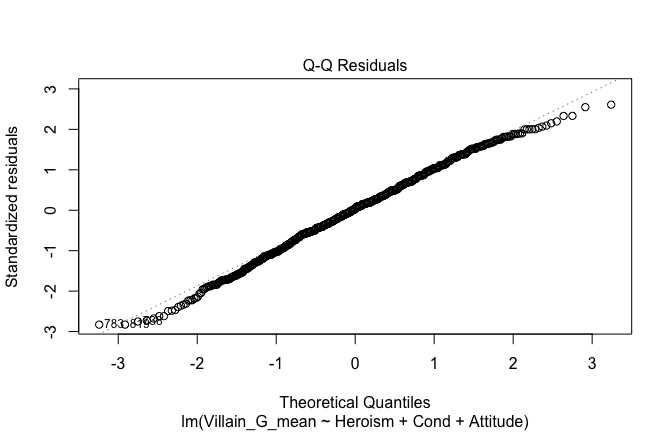
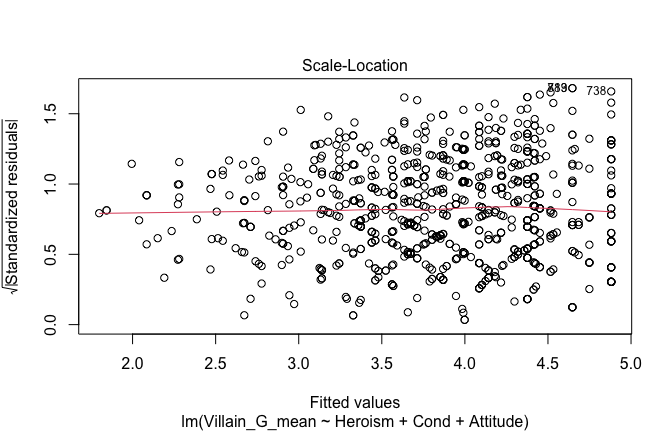
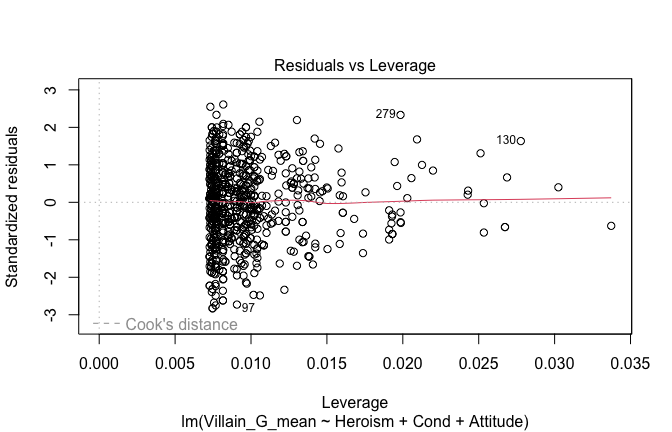
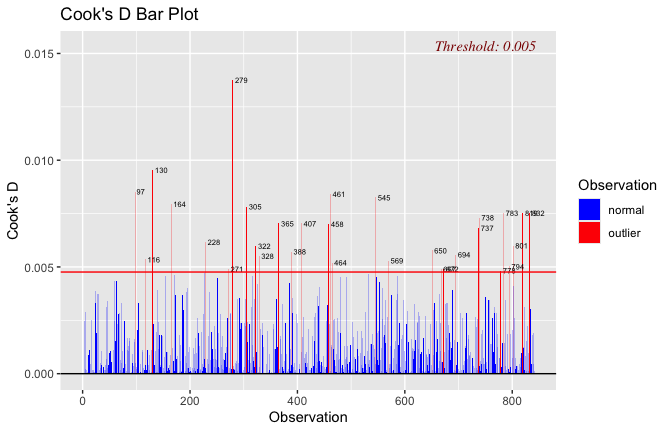
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.708 | 2.618 |
| (0.218) | (0.217) | |
| 12.420 | 12.047 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.234 | 0.257 |
| (0.043) | (0.043) | |
| 5.393 | 5.935 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.277 | 0.322 |
| (0.105) | (0.112) | |
| 2.634 | 2.862 | |
| p = 0.009 | p = 0.004 | |
| Cond2 | 0.058 | 0.044 |
| (0.111) | (0.109) | |
| 0.526 | 0.400 | |
| p = 0.599 | p = 0.689 | |
| Cond3 | −0.227 | −0.223 |
| (0.103) | (0.109) | |
| −2.212 | −2.041 | |
| p = 0.027 | p = 0.042 | |
| Cond4 | −0.071 | −0.065 |
| (0.101) | (0.104) | |
| −0.707 | −0.621 | |
| p = 0.480 | p = 0.535 | |
| Cond5 | −0.183 | −0.230 |
| (0.101) | (0.113) | |
| −1.806 | −2.034 | |
| p = 0.071 | p = 0.042 | |
| Attitude | 0.253 | 0.242 |
| (0.073) | (0.070) | |
| 3.480 | 3.478 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.194 | 0.213 |
| R2 Adj. | 0.187 | 0.206 |
| RMSE | 1.29 | 1.29 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)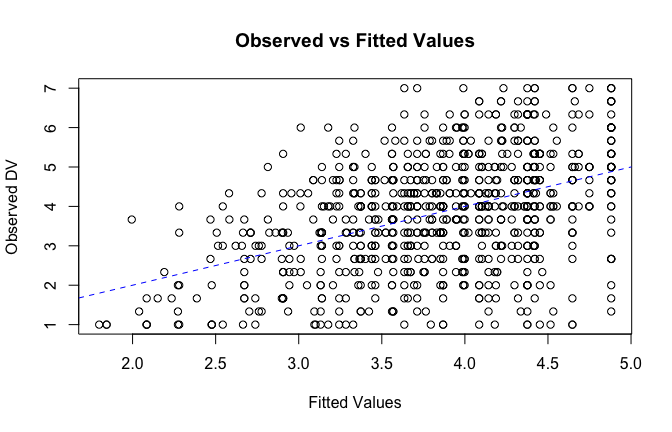
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Villain_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Villain_G_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)
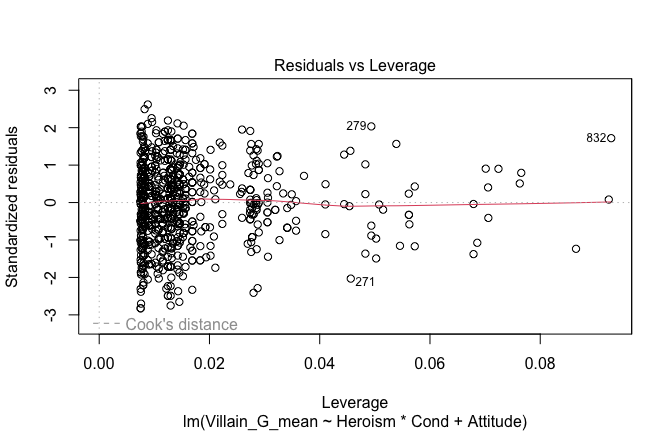
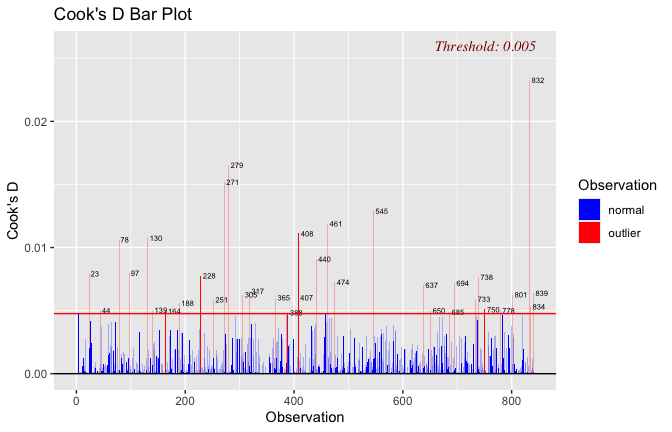
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 2.690 | 2.593 |
| (0.220) | (0.227) | |
| 12.203 | 11.424 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.245 | 0.269 |
| (0.044) | (0.044) | |
| 5.637 | 6.081 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | 0.355 | 0.238 |
| (0.499) | (0.538) | |
| 0.712 | 0.443 | |
| p = 0.476 | p = 0.658 | |
| Cond2 | −0.461 | −0.455 |
| (0.288) | (0.258) | |
| −1.602 | −1.764 | |
| p = 0.110 | p = 0.078 | |
| Cond3 | 0.465 | 0.442 |
| (0.370) | (0.369) | |
| 1.258 | 1.197 | |
| p = 0.209 | p = 0.232 | |
| Cond4 | 0.094 | 0.087 |
| (0.334) | (0.341) | |
| 0.283 | 0.254 | |
| p = 0.777 | p = 0.800 | |
| Cond5 | −0.907 | −0.877 |
| (0.338) | (0.310) | |
| −2.682 | −2.828 | |
| p = 0.007 | p = 0.005 | |
| Attitude | 0.207 | 0.198 |
| (0.074) | (0.071) | |
| 2.793 | 2.777 | |
| p = 0.005 | p = 0.006 | |
| Heroism × Cond1 | −0.017 | 0.011 |
| (0.084) | (0.090) | |
| −0.201 | 0.123 | |
| p = 0.841 | p = 0.902 | |
| Heroism × Cond2 | 0.128 | 0.126 |
| (0.067) | (0.063) | |
| 1.896 | 1.983 | |
| p = 0.058 | p = 0.048 | |
| Heroism × Cond3 | −0.127 | −0.124 |
| (0.065) | (0.066) | |
| −1.973 | −1.863 | |
| p = 0.049 | p = 0.063 | |
| Heroism × Cond4 | −0.045 | −0.041 |
| (0.069) | (0.070) | |
| −0.656 | −0.585 | |
| p = 0.512 | p = 0.559 | |
| Heroism × Cond5 | 0.133 | 0.122 |
| (0.063) | (0.062) | |
| 2.117 | 1.971 | |
| p = 0.035 | p = 0.049 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.205 | 0.224 |
| R2 Adj. | 0.194 | 0.212 |
| RMSE | 1.28 | 1.28 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_G_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: Villain_G_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 833)
## = 121.02, p < .001; Eta2 (partial) = 0.13, 95% CI [0.09, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 833) =
## 3.56, p = 0.003; Eta2 (partial) = 0.02, 95% CI [4.13e-03, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: Villain_G_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and medium (F(1, 828)
## = 108.33, p < .001; Eta2 (partial) = 0.12, 95% CI [0.08, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 828) =
## 3.47, p = 0.004; Eta2 (partial) = 0.02, 95% CI [3.85e-03, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 828) = 3.12, p = 0.008; Eta2 (partial) = 0.02, 95% CI [2.69e-03,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: Villain_G_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(Villain_G_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 832)
## = 29.09, p < .001; Eta2 (partial) = 0.03, 95% CI [0.02, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 832) =
## 3.21, p = 0.007; Eta2 (partial) = 0.02, 95% CI [2.98e-03, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 832) = 12.11, p < .001; Eta2 (partial) = 0.01, 95% CI [4.00e-03, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: Villain_G_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(Villain_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 827)
## = 31.78, p < .001; Eta2 (partial) = 0.04, 95% CI [0.02, 1.00])
## - The main effect of Cond is statistically not significant and small (F(5, 827)
## = 2.15, p = 0.058; Eta2 (partial) = 0.01, 95% CI [0.00, 1.00])
## - The main effect of scale(Attitude) is statistically significant and very
## small (F(1, 827) = 7.80, p = 0.005; Eta2 (partial) = 9.34e-03, 95% CI
## [1.58e-03, 1.00])
## - The interaction between Heroism and Cond is statistically significant and
## small (F(5, 827) = 2.27, p = 0.046; Eta2 (partial) = 0.01, 95% CI [1.15e-04,
## 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = Villain_G_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Impunity (G)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Impunity (G), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'
ggplot(scale_scores, aes(y = Villain_G_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Impunity (G) ",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Impunity (G) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'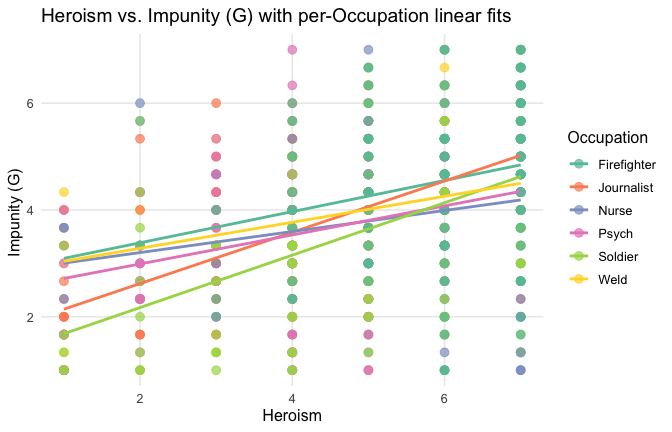
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(Villain_G_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(Villain_G_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(Villain_G_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(Villain_G_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 121.02 | < .001 | 0.127 |
| Occupation | Occupation | 5 | 833 | 3.56 | = 0.003 | 0.021 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 108.33 | < .001 | 0.116 |
| Occupation | Occupation | 5 | 828 | 3.47 | = 0.004 | 0.021 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 3.12 | = 0.008 | 0.019 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 29.09 | < .001 | 0.034 |
| Occupation | Occupation | 5 | 832 | 3.21 | = 0.007 | 0.019 |
| Attitude | Attitude | 1 | 832 | 12.11 | < .001 | 0.014 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 31.78 | < .001 | 0.037 |
| Occupation | Occupation | 5 | 827 | 2.15 | = 0.058 | 0.013 |
| Attitude | Attitude | 1 | 827 | 7.80 | = 0.005 | 0.009 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 2.27 | = 0.046 | 0.014 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "Villain_G_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(Villain_G_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(Villain_G_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(Villain_G_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(Villain_G_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | Villain_G_mean | Heroism | 1 | 833 | 121.02 | < .001 | 0.127 |
| ~ Heroism * Occupation | Villain_G_mean | Heroism | 1 | 828 | 108.33 | < .001 | 0.116 |
| ~ Heroism + Cond + Attitude | Villain_G_mean | Heroism | 1 | 832 | 29.09 | < .001 | 0.034 |
| ~ Heroism * Occupation + Attitude | Villain_G_mean | Heroism | 1 | 827 | 31.78 | < .001 | 0.037 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
Specific level
UK journalists must follow strict codes of ethics, such as IPSO rules and their employers’ policies. These ban phone hacking or wiretapping except in rare, extreme cases. The rules stress respect for privacy, following the law, and avoiding unjustified intrusion, even for the public interest. A national journalist suspects a top official of abusing their position by steering public contracts to companies owned by close associates, raising concerns of corruption and misuse of public money. With no evidence and official investigations blocked, the journalist believes normal reporting won’t work fast enough. They secretly tap the phones of the official, his wife, and two daughters for several weeks, hoping to find proof.
Toggle details of the models diagnostics and outlier analyses
Below, you’ll find model diagnostics (QQ plot, fitted vs residuals, linearity), Outliers analysis, and more details on the output
[NOTE THAT EFFECT SIZES REPORTED IN THE REPORT COMMANDS BELOW SHOULD NOT BE TRUSTED]
## [1] "####################################################"## [1] "Diagnostics for Model 1: DV ~ Heroism + Occupation"## [1] "####################################################"mod1 <- lm(Villain_S_mean ~ Heroism + Cond, data = scale_scores)
mod1r <- lmrob(Villain_S_mean ~ Heroism + Cond, data = scale_scores)
plot(mod1)
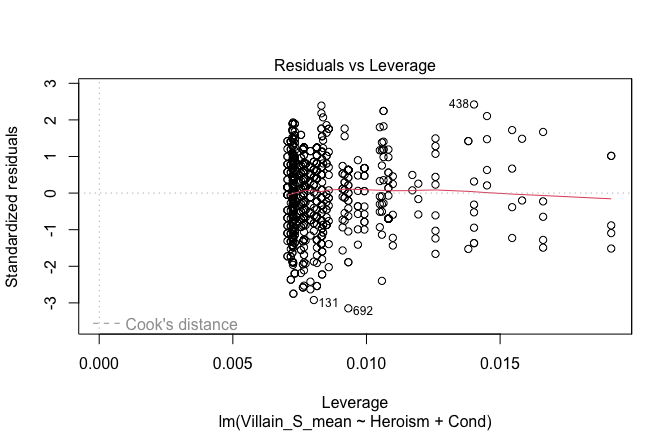
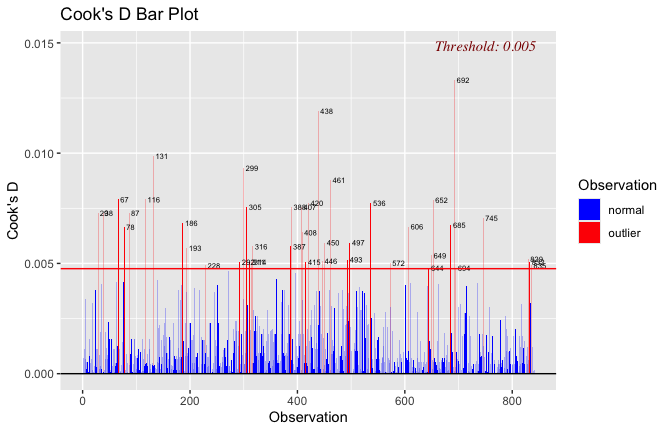
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.174 | 3.055 |
| (0.194) | (0.224) | |
| 16.337 | 13.637 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.273 | 0.309 |
| (0.038) | (0.043) | |
| 7.227 | 7.129 | |
| p = <0.001 | p = <0.001 | |
| Cond1 | −0.068 | −0.114 |
| (0.128) | (0.120) | |
| −0.529 | −0.949 | |
| p = 0.597 | p = 0.343 | |
| Cond2 | −1.336 | −1.413 |
| (0.133) | (0.150) | |
| −10.012 | −9.392 | |
| p = <0.001 | p = <0.001 | |
| Cond3 | −0.053 | −0.010 |
| (0.126) | (0.169) | |
| −0.425 | −0.058 | |
| p = 0.671 | p = 0.954 | |
| Cond4 | −0.281 | −0.344 |
| (0.124) | (0.161) | |
| −2.274 | −2.136 | |
| p = 0.023 | p = 0.033 | |
| Cond5 | 0.911 | 0.951 |
| (0.124) | (0.108) | |
| 7.354 | 8.822 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.271 | 0.311 |
| R2 Adj. | 0.266 | 0.306 |
| RMSE | 1.59 | 1.59 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 2: DV ~ Heroism * Occupation"## [1] "####################################################"mod1 <- lm(Villain_S_mean ~ Heroism * Cond, data = scale_scores)
mod1r <- lmrob(Villain_S_mean ~ Heroism * Cond, data = scale_scores)## Warning in lmrob.S(x, y, control = control): S refinements did not converge (to
## refine.tol=1e-07) in 200 (= k.max) steps## Warning in lmrob.fit(x, y, control, init = init): initial estim. 'init' not
## converged -- will be return()ed basically unchanged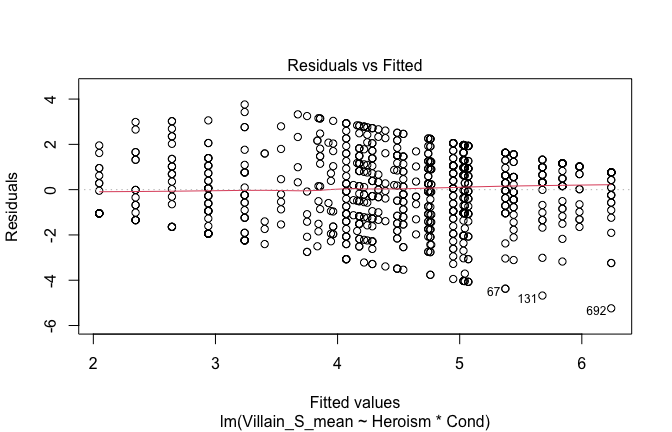
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 3.224 | 2.463 |
| (0.205) | ||
| 15.734 | ||
| p = <0.001 | ||
| Heroism | 0.264 | 0.477 |
| (0.039) | ||
| 6.779 | ||
| p = <0.001 | ||
| Cond1 | 0.293 | −0.430 |
| (0.613) | ||
| 0.478 | ||
| p = 0.632 | ||
| Cond2 | −1.474 | −1.456 |
| (0.348) | ||
| −4.230 | ||
| p = <0.001 | ||
| Cond3 | −0.092 | 1.908 |
| (0.456) | ||
| −0.202 | ||
| p = 0.840 | ||
| Cond4 | 0.419 | −1.949 |
| (0.411) | ||
| 1.020 | ||
| p = 0.308 | ||
| Cond5 | 0.220 | 0.064 |
| (0.410) | ||
| 0.537 | ||
| p = 0.591 | ||
| Heroism × Cond1 | −0.060 | 0.034 |
| (0.103) | ||
| −0.579 | ||
| p = 0.563 | ||
| Heroism × Cond2 | 0.034 | −0.180 |
| (0.083) | ||
| 0.410 | ||
| p = 0.682 | ||
| Heroism × Cond3 | 0.007 | −0.165 |
| (0.080) | ||
| 0.093 | ||
| p = 0.926 | ||
| Heroism × Cond4 | −0.157 | 0.324 |
| (0.085) | ||
| −1.853 | ||
| p = 0.064 | ||
| Heroism × Cond5 | 0.136 | 0.142 |
| (0.077) | ||
| 1.762 | ||
| p = 0.078 | ||
| Num.Obs. | 840 | 840 |
| R2 | 0.276 | 0.798 |
| R2 Adj. | 0.267 | 0.795 |
| RMSE | 1.58 | 1.80 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)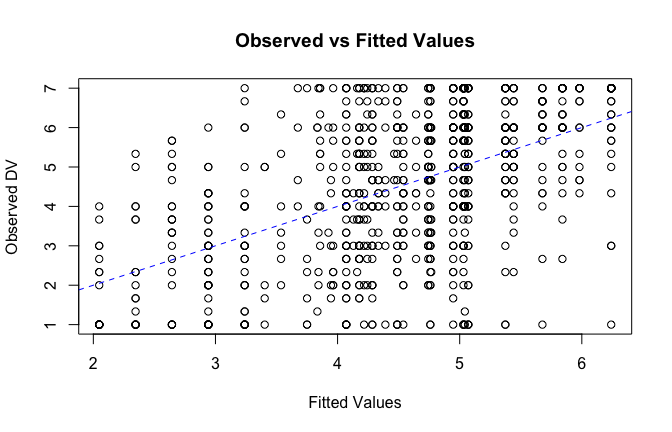
## [1] "####################################################"## [1] "Diagnostics for Model 3: DV ~ Heroism + Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Villain_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Villain_S_mean ~ Heroism + Cond + Attitude, data = scale_scores)
plot(mod1)
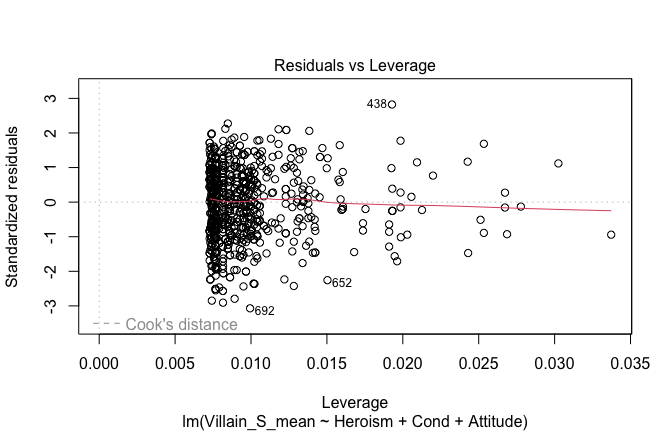
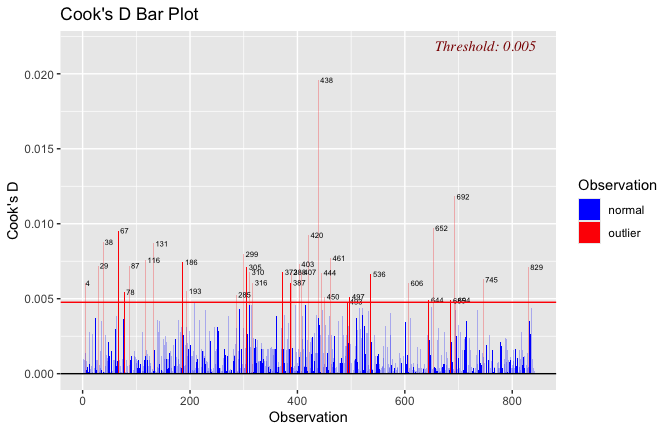
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.078 | 3.974 |
| (0.265) | (0.303) | |
| 15.390 | 13.112 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.090 | 0.123 |
| (0.053) | (0.060) | |
| 1.707 | 2.059 | |
| p = 0.088 | p = 0.040 | |
| Cond1 | −0.160 | −0.199 |
| (0.128) | (0.121) | |
| −1.253 | −1.652 | |
| p = 0.211 | p = 0.099 | |
| Cond2 | −1.195 | −1.269 |
| (0.135) | (0.149) | |
| −8.865 | −8.513 | |
| p = <0.001 | p = <0.001 | |
| Cond3 | −0.134 | −0.085 |
| (0.125) | (0.166) | |
| −1.071 | −0.511 | |
| p = 0.285 | p = 0.609 | |
| Cond4 | −0.325 | −0.377 |
| (0.122) | (0.155) | |
| −2.659 | −2.441 | |
| p = 0.008 | p = 0.015 | |
| Cond5 | 0.987 | 1.021 |
| (0.123) | (0.104) | |
| 8.015 | 9.854 | |
| p = <0.001 | p = <0.001 | |
| Attitude | 0.436 | 0.436 |
| (0.088) | (0.092) | |
| 4.942 | 4.742 | |
| p = <0.001 | p = <0.001 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.292 | 0.327 |
| R2 Adj. | 0.286 | 0.322 |
| RMSE | 1.57 | 1.57 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "Diagnostics for Model 4: DV ~ Heroism * Occupation + Attitude"## [1] "####################################################"mod1 <- lm(Villain_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
mod1r <- lmrob(Villain_S_mean ~ Heroism*Cond + Attitude, data = scale_scores)
plot(mod1)
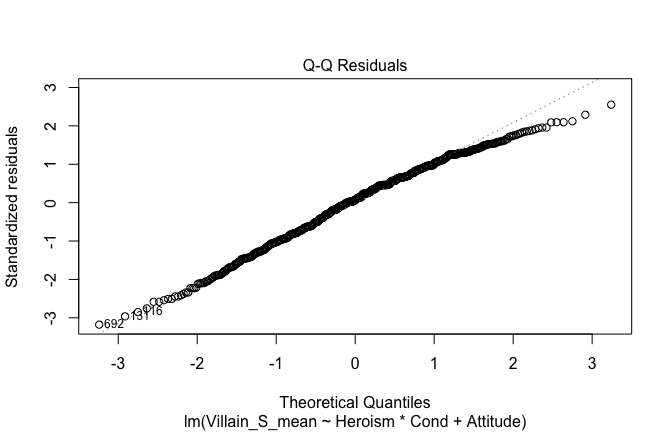
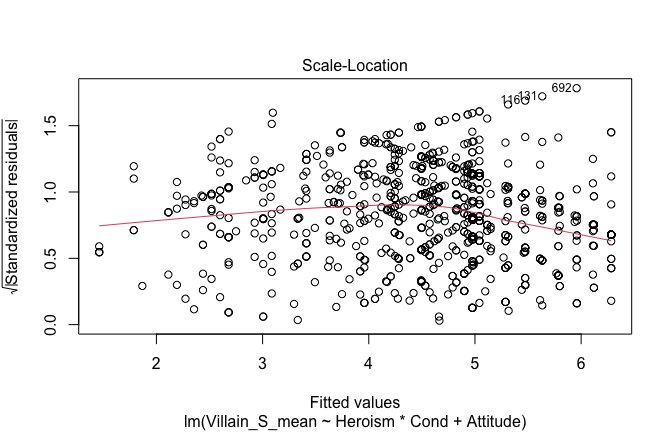
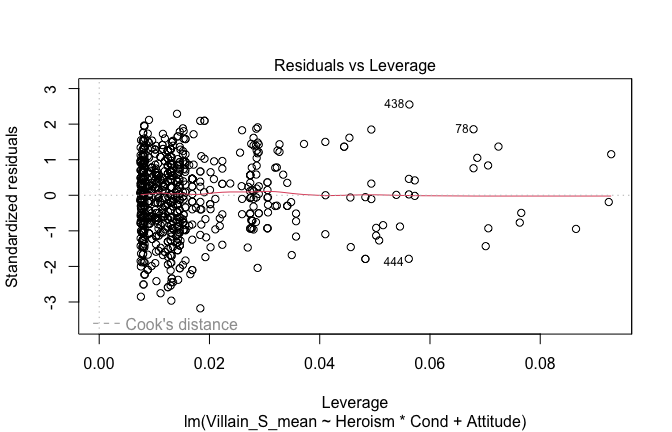
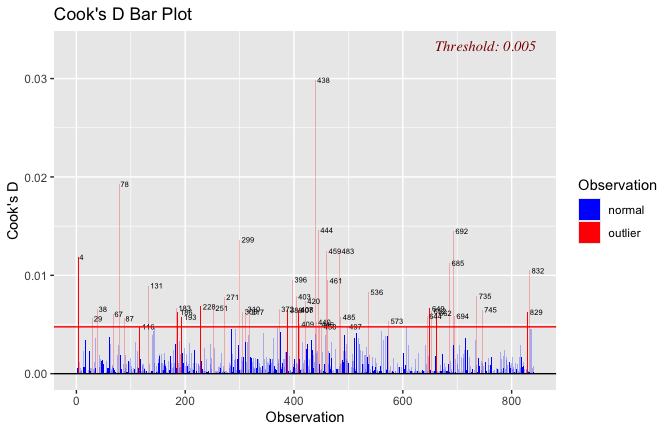
## [1] "Comparison with Robust model"models <- list("OLS (lm)" = mod1, "Robust (lmrob)" = mod1r)
modelsummary(
models,
statistic = c("({std.error})", "{statistic}", "p = {p.value}"),
gof_omit = "IC|Log.Lik", # robust AIC comparability is iffy; omit by default
output = "html"
)| OLS (lm) | Robust (lmrob) | |
|---|---|---|
| (Intercept) | 4.048 | 3.969 |
| (0.269) | (0.312) | |
| 15.041 | 12.735 | |
| p = <0.001 | p = <0.001 | |
| Heroism | 0.094 | 0.119 |
| (0.053) | (0.062) | |
| 1.761 | 1.934 | |
| p = 0.079 | p = 0.054 | |
| Cond1 | −0.038 | −0.109 |
| (0.609) | (0.547) | |
| −0.062 | −0.199 | |
| p = 0.951 | p = 0.843 | |
| Cond2 | −1.146 | −1.102 |
| (0.351) | (0.353) | |
| −3.261 | −3.125 | |
| p = 0.001 | p = 0.002 | |
| Cond3 | −0.213 | −0.275 |
| (0.451) | (0.546) | |
| −0.471 | −0.505 | |
| p = 0.638 | p = 0.614 | |
| Cond4 | 0.283 | 0.198 |
| (0.407) | (0.662) | |
| 0.695 | 0.299 | |
| p = 0.487 | p = 0.765 | |
| Cond5 | 0.598 | 0.579 |
| (0.413) | (0.409) | |
| 1.448 | 1.416 | |
| p = 0.148 | p = 0.157 | |
| Attitude | 0.421 | 0.423 |
| (0.091) | (0.096) | |
| 4.646 | 4.397 | |
| p = <0.001 | p = <0.001 | |
| Heroism × Cond1 | −0.018 | −0.009 |
| (0.102) | (0.094) | |
| −0.172 | −0.099 | |
| p = 0.864 | p = 0.921 | |
| Heroism × Cond2 | −0.013 | −0.047 |
| (0.082) | (0.088) | |
| −0.158 | −0.539 | |
| p = 0.874 | p = 0.590 | |
| Heroism × Cond3 | 0.017 | 0.040 |
| (0.079) | (0.094) | |
| 0.216 | 0.423 | |
| p = 0.829 | p = 0.672 | |
| Heroism × Cond4 | −0.132 | −0.120 |
| (0.084) | (0.133) | |
| −1.576 | −0.901 | |
| p = 0.115 | p = 0.368 | |
| Heroism × Cond5 | 0.079 | 0.091 |
| (0.077) | (0.073) | |
| 1.020 | 1.240 | |
| p = 0.308 | p = 0.215 | |
| Num.Obs. | 840 | 840 |
| R2 | 0.295 | 0.331 |
| R2 Adj. | 0.284 | 0.321 |
| RMSE | 1.56 | 1.57 |
fitted_vals <- fitted(mod1)
# Plot observed values against fitted values
plot(fitted_vals, scale_scores$Villain_S_mean,
xlab = "Fitted Values",
ylab = "Observed DV",
main = "Observed vs Fitted Values")
abline(0, 1, col = "blue", lty = 2)
## [1] "####################################################"## [1] "REPORTS for each model (please ignore the eta squares, they are way off"## [1] "####################################################"## [1] "MODEL 1: Villain_S_mean ~ Heroism"## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 833)
## = 52.23, p < .001; Eta2 (partial) = 0.06, 95% CI [0.04, 1.00])
## - The main effect of Cond is statistically significant and large (F(5, 833) =
## 34.66, p < .001; Eta2 (partial) = 0.17, 95% CI [0.13, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 2: Villain_S_mean ~ Heroism * Cond"## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically significant and small (F(1, 828)
## = 45.96, p < .001; Eta2 (partial) = 0.05, 95% CI [0.03, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 828) =
## 3.94, p = 0.002; Eta2 (partial) = 0.02, 95% CI [5.51e-03, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 828) = 1.24, p = 0.290; Eta2 (partial) = 7.41e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 3: Villain_S_mean ~ Heroism +scale(Attitude)"report(Anova(mod3 <- lm(Villain_S_mean ~ Heroism + Cond +scale(Attitude) , data = scale_scores), type = "III"))## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically not significant and very small
## (F(1, 832) = 2.91, p = 0.088; Eta2 (partial) = 3.49e-03, 95% CI [0.00, 1.00])
## - The main effect of Cond is statistically significant and large (F(5, 832) =
## 34.61, p < .001; Eta2 (partial) = 0.17, 95% CI [0.13, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 832) = 24.42, p < .001; Eta2 (partial) = 0.03, 95% CI [0.01, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "MODEL 4: Villain_S_mean ~ Heroism * Cond + scale(Attitude)"report(Anova(mod4 <-lm(Villain_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores), type = "III"))## Type 3 ANOVAs only give sensible and informative results when covariates
## are mean-centered and factors are coded with orthogonal contrasts (such
## as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
## *not* by the default `contr.treatment`).## The ANOVA suggests that:
##
## - The main effect of Heroism is statistically not significant and very small
## (F(1, 827) = 3.10, p = 0.079; Eta2 (partial) = 3.74e-03, 95% CI [0.00, 1.00])
## - The main effect of Cond is statistically significant and small (F(5, 827) =
## 2.83, p = 0.015; Eta2 (partial) = 0.02, 95% CI [1.77e-03, 1.00])
## - The main effect of scale(Attitude) is statistically significant and small
## (F(1, 827) = 21.59, p < .001; Eta2 (partial) = 0.03, 95% CI [0.01, 1.00])
## - The interaction between Heroism and Cond is statistically not significant and
## very small (F(5, 827) = 0.71, p = 0.616; Eta2 (partial) = 4.27e-03, 95% CI
## [0.00, 1.00])
##
## Effect sizes were labelled following Field's (2013) recommendations.## [1] "Model Comparison: assessing the importance of attitude - not accounting for occupations"## [1] "Model Comparison: assessing the importance of attitude - accounting for occupations"ggplot(scale_scores, aes(y = Villain_S_mean, x = Heroism)) +
# 1) points colored by Cond
geom_point(aes(color = Cond),
size = 2.7, alpha = 0.7) +
# 2) ONE global lm line (group = 1 prevents one line per Cond)
stat_smooth(method = "lm", se = TRUE,
aes(group = 1),
color = "black", linewidth = 1) +
# Nice, accessible palette (works well with >3 groups)
scale_color_brewer(palette = "Set2") +
labs(
y = "Impunity (S)",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Impunity (S), colored by Occupation",
subtitle = "Points are participants; black line is overall linear fit with 95% CI"
) +
theme_minimal(base_size = 12) +
theme(
legend.position = "right",
panel.grid.minor = element_blank()
)## `geom_smooth()` using formula = 'y ~ x'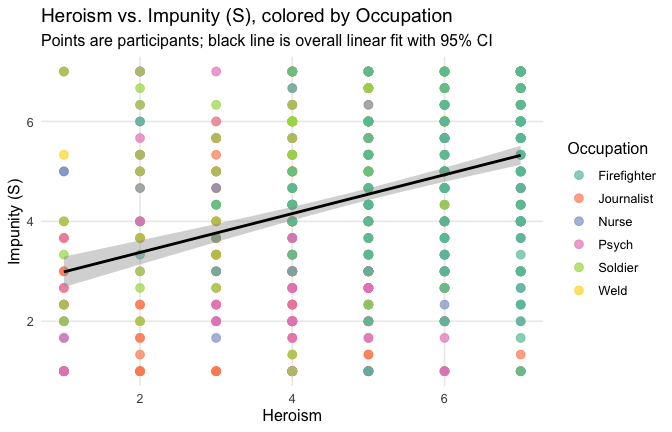
ggplot(scale_scores, aes(y = Villain_S_mean, x = Heroism, color = Cond)) +
# points colored by condition
geom_point(size = 2.7, alpha = 0.7) +
# ONE lm line PER condition (because color is mapped here)
stat_smooth(method = "lm", se = FALSE, linewidth = 1, fullrange = TRUE) +
scale_color_brewer(palette = "Set2") +
labs(
y = "Impunity (S) ",
x = "Heroism",
color = "Occupation",
title = "Heroism vs. Impunity (S) with per-Occupation linear fits"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "right", panel.grid.minor = element_blank())## `geom_smooth()` using formula = 'y ~ x'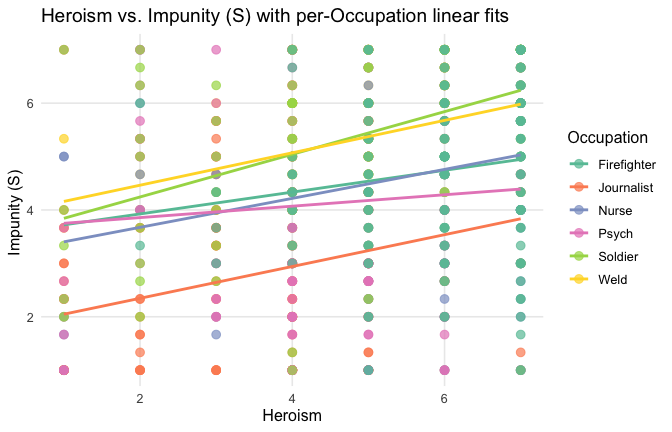
==> Full support for our hypotheses. Across all occupations Heroism predict general- and specific-level gratitude, with or without controlling for attitude.
Model 1: “~Heroism + Occupation”
# =========================
# OLD MODELS (Heroism)
# =========================
m1_H <- lm(Villain_S_mean ~ Heroism + Occupation, data = scale_scores)
m2_H <- lm(Villain_S_mean ~ Heroism * Occupation, data = scale_scores)
m3_H <- lm(Villain_S_mean ~ Heroism + Occupation + Attitude, data = scale_scores)
m4_H <- lm(Villain_S_mean ~ Heroism * Occupation + Attitude, data = scale_scores)
tidy_type3(m1_H, "~Heroism + Cond")| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 833 | 52.23 | < .001 | 0.059 |
| Occupation | Occupation | 5 | 833 | 34.66 | < .001 | 0.172 |
Model 2: “~Heroism * Occupation”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 828 | 45.96 | < .001 | 0.053 |
| Occupation | Occupation | 5 | 828 | 3.94 | = 0.002 | 0.023 |
| Heroism:Occupation | Heroism:Occupation | 5 | 828 | 1.24 | = 0.290 | 0.007 |
Model 3: “~Heroism + Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 832 | 2.91 | = 0.088 | 0.003 |
| Occupation | Occupation | 5 | 832 | 34.61 | < .001 | 0.172 |
| Attitude | Attitude | 1 | 832 | 24.42 | < .001 | 0.029 |
Model 4: “~Heroism * Occupation + Attitude”
| Term | df1 | df2 | F | p | eta2p | |
|---|---|---|---|---|---|---|
| Heroism | Heroism | 1 | 827 | 3.10 | = 0.079 | 0.004 |
| Occupation | Occupation | 5 | 827 | 2.83 | = 0.015 | 0.017 |
| Attitude | Attitude | 1 | 827 | 21.59 | < .001 | 0.025 |
| Heroism:Occupation | Heroism:Occupation | 5 | 827 | 0.71 | = 0.616 | 0.004 |
Comparison of main predictors across models
# Use orthogonal contrasts; keeps your "Heroism main effect" interpretable with Cond in the model
old_contr <- options(contrasts = c("contr.sum", "contr.poly"))
# Helper to extract the main effect of "Heroism" from a car::Anova table
extract_heroism <- function(mod, model_label) {
a <- car::Anova(mod, type = "III")
# Coerce to data.frame with rownames preserved
tab <- as.data.frame(a)
tab$Term <- rownames(tab)
# Standard column names across R versions
# (car::Anova uses these names for lm/glm type=III)
# Columns: "Sum Sq", "Df", "F value", "Pr(>F)"
names(tab) <- sub(" ", "_", names(tab)) # make names safe: "Sum_Sq", "F_value", etc.
# Pull rows we need
hero <- tab %>% filter(Term == "Heroism")
resid <- tab %>% filter(Term == "Residuals")
# Safety checks (in case of name variants)
stopifnot(nrow(hero) == 1, nrow(resid) == 1)
# Partial eta^2 = SS_effect / (SS_effect + SS_residual)
eta_p2 <- hero$Sum_Sq / (hero$Sum_Sq + resid$Sum_Sq)
# Format p nicely (APA-ish)
p_fmt <- ifelse(hero$`Pr(>F)` < .001, "< .001",
sprintf("= %.3f", hero$`Pr(>F)`))
dplyr::tibble(
Model = model_label,
Outcome = "Villain_S_mean",
Predictor = "Heroism",
df1 = hero$Df,
df2 = resid$Df,
F = hero$F_value,
p = p_fmt,
eta2p = eta_p2
)
}
# ----- Fit the four models -----
mod1 <- lm(Villain_S_mean ~ Heroism + Cond, data = scale_scores)
mod2 <- lm(Villain_S_mean ~ Heroism * Cond, data = scale_scores)
mod3 <- lm(Villain_S_mean ~ Heroism + Cond + scale(Attitude), data = scale_scores)
mod4 <- lm(Villain_S_mean ~ Heroism * Cond + scale(Attitude), data = scale_scores)
# ----- Build the summary table -----
tbl <- bind_rows(
extract_heroism(mod1, "~ Heroism + Cond"),
extract_heroism(mod2, "~ Heroism * Occupation"),
extract_heroism(mod3, "~ Heroism + Cond + Attitude"),
extract_heroism(mod4, "~ Heroism * Occupation + Attitude")
) %>%
# Nice number formatting for F and eta^2p
mutate(
F = round(F, 2),
eta2p = round(eta2p, 3)
)
# ----- Print as HTML-friendly table -----
# Build the table first
tbl_kbl <- tbl %>%
kable("html",
caption = "Main effect of Heroism across models (Type-III ANOVA): F, p, partial η²",
align = "lllrrrcr")
# Add a footnote in a version-robust way
if ("footnote" %in% getNamespaceExports("kableExtra")) {
tbl_kbl <- tbl_kbl %>%
kableExtra::footnote(
general = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
general_title = ""
)
} else {
tbl_kbl <- tbl_kbl %>%
kableExtra::add_footnote(
label = "Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style.",
notation = "none"
)
}
tbl_kbl| Model | Outcome | Predictor | df1 | df2 | F | p | eta2p |
|---|---|---|---|---|---|---|---|
| ~ Heroism + Cond | Villain_S_mean | Heroism | 1 | 833 | 52.23 | < .001 | 0.059 |
| ~ Heroism * Occupation | Villain_S_mean | Heroism | 1 | 828 | 45.96 | < .001 | 0.053 |
| ~ Heroism + Cond + Attitude | Villain_S_mean | Heroism | 1 | 832 | 2.91 | = 0.088 | 0.003 |
| ~ Heroism * Occupation + Attitude | Villain_S_mean | Heroism | 1 | 827 | 3.10 | = 0.079 | 0.004 |
| Type-III sums of squares with sum contrasts. Partial η² = SS_effect / (SS_effect + SS_residual). p values are APA-style. |
Conclusion for Primary statistical models
We obtained FULL SUPPORT for H1 (Gratitude), H2 (Criticism acceptability), and H5 (Impunity). However, we obtained NO SUPPORT for H3 (support for workers demands) and H4 (victimisation). In fact, heroised occupation appeared to be supported and victimised.
Those previous analyses focus on effects of heroism across occupations. We demonstrated in previous studies that heroism was predicted by perceptions of exposure to danger and perceptions of helpfulness of the occupations. In our secondary analyses, we make the predictions that these antecedents of heroism should predict our target outcomes as well (hypothetically, through increased perceived heroism).